ГОСТ Р ИСО 26162-2016
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
СИСТЕМЫ УПРАВЛЕНИЯ ТЕРМИНОЛОГИЕЙ, БАЗАМИ ЗНАНИЙ И КОНТЕНТОМ
Проектирование, внедрение и поддержка систем управления терминологией
Systems to manage terminology, knowledge and content. Design, implementation and maintenance of terminology management systems
ОКС 01.020
35.240.60
Дата введения 2017-09-01
Предисловие
1 ПОДГОТОВЛЕН Автономной некоммерческой организацией "Институт безопасности труда" (АНО "ИБТ") на основе собственного перевода на русский язык англоязычной версии стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 55 "Терминология, элементы данных и документация в бизнес-процессах и электронной торговле"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 30 ноября 2016 г. N 1905-ст
4 Настоящий стандарт идентичен международному стандарту ИСО 26162:2012* "Системы управления терминологией, знаниями и содержанием. Проектирование, внедрение и поддержка систем менеджмента терминологии" (ISO 26162:2012 "Systems to manage terminology, knowledge and content - Design, implementation and maintenance of terminology management systems", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные стандарты, сведения о которых приведены в дополнительном приложении ДА
5 ВВЕДЕН ВПЕРВЫЕ
6 ПЕРЕИЗДАНИЕ. Апрель 2020 г.
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске ежемесячного информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
Введение
Терминологические данные собираются, управляются и хранятся в самых разнообразных системах управления терминологией (TMSs). TMSs используют различные системы управления базами данных, начиная с приложений персонального компьютера для отдельных пользователей, клиент-сервером, приложения или веб-приложения, используемые крупными компаниями и правительственными учреждениями. Терминологические сборники данных (TDCs) основаны на различных видах моделей данных и состоят из различных наборов категорий данных (Выбор категорий данных, DCSs). Чтобы облегчить сотрудничество и предотвратить дублирование, необходимо разработать стандарты и рекомендации для создания и использования TDCs, а также для совместного использования и обмена данными.
В целях содействия обмену терминологическими данными и создания комплексного подхода, который будет использоваться при анализе существующих и проектировании новых TDC, ISO/TC 37 опубликовал следующие стандарты: ИСО 704, ИСО 12620, ИСО 16642.
Было бы полезно ознакомиться с этими документами прежде, чем прочитать настоящий стандарт.
Настоящий стандарт содержит указания по выбору соответствующих категорий данных, а также по проектированию и реализации модели данных и пользовательского интерфейса для TMS, принимая во внимание целевую группу пользователей. Рекомендации, описанные в этом стандарте, обязательны для успешного развития TMS и для предотвращения дорогостоящих ошибок. Этот стандарт может использоваться для выбора соответствующих TMS в определенной цели.
1 Область применения
Настоящий стандарт устанавливает критерии проектирования, внедрения и поддержания систем управления терминологией (TMSs).
Настоящий стандарт предоставляет информацию о содержании обоснования использования IMS, типах и потребностях пользователей системы, разработке и внедрении IMS, а также о задачах по организации и управлению терминологическим сбором данных (TDC). Настоящий стандарт содержит рекомендации по выбору и использованию категорий данных для управления терминологией в различных средах.
Настоящий стандарт предназначен для терминологов, разработчиков программного обеспечения и других лиц, которые вовлечены в процесс разработки или приобретения IMS.
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие международные стандарты. Для датированных ссылок применяют только указанные издания. Для недатированных ссылок применяют самые последние издания (включая любые изменения и поправки).
ISO 704, Terminology work. Principles and methods (Терминологическая работа. Принципы и методы).
ISO 12620, Terminology and other language and content resources. Specification of data categories and management of a Data Category Registry for language resources (Терминология, другие языковые ресурсы и ресурсы содержания. Спецификация категорий данных и ведение реестра категорий данных для языковых ресурсов).
ISO 16642, Computer applications in terminology - Termilogy markup framework (Применение компьютера в терминологии. Структура терминологической разметки)
ISO 30042, Systems to manage terminology, knowledge and content - TermBase eXchange (TBX) (Системы для управления терминологией, знаниями и содержанием. Обмен базами данных (TermBase eXchange (TBX)).
3 Термины и определения
В настоящем стандарте применены термины с соответствующими определениями:
3.1 Ресурсы
3.1.1 terminological resource, terminological data collection TDC (терминологический ресурс, терминологический сбор данных TDC): Текст или информационный ресурс, состоящий из терминологических записей (3.1.4).
Примечание - Адаптированный в ИСО 24613:2008.
3.1.2 terminology management system TMS (системы управления терминологией TMS): Программное средство, специально предназначенное для сбора, поддержания и доступа к терминологическим данным.
3.1.3 terminological database TDB (termbase) (терминологическая база данных TDB): Терминологическая база, база данных, включающая терминологический ресурс (3.1.1).
3.1.4 terminological entry TЕ (терминологический вход TE): Часть терминологического ресурса (3.1.1), который содержит терминологические данные, связанные с одним понятием.
Примечание - Адаптированный в ИСО 1087-2, 2.22.
3.1.5 concept orientation (ориентация понятия): Принцип относится к управлению терминологией, посредством чего терминологический вход (3.1.4) описывает одно и только одно понятие или два, или больше квазиэквивалентных понятий (3.1.7).
Примечание - Ориентированный на понятие вход может содержать многократные условия, которые считают семантически эквивалентными.
3.1.6 equivalent concept (эквивалентное понятие): Понятие на одном языке, которое включает те же самые особенности, как покрытый данным понятием на другом языке.*
___________________
* Текст документа соответствует оригиналу. - .
3.1.7 quasi-equivalent concept (nearly equivalent concept) (квазиэквивалентное понятие (почти эквивалентное понятие)): Понятие на одном языке, которое разделяет больше всего, но не все особенности с понятием на другом языке, но это тем не менее используется в качестве эквивалента для того понятия в некоторых контекстах.
3.1.8 entailed term (вызванный термин): Термин использовался в текстовом поле, таком как /definition/ или /contеxt/, которое определяет понятие, которое определено в другом терминологическом входе (3.1.4) в том же самом терминологическом ресурсе (3.1.1).
3.1.9 doublette (двойной вход): Терминологический вход (3.1.4), который описывает то же самое понятие как другой вход.
Примечание - Двойной вход обычно обнаруживается TMS, определяя два условия, имеющие ту же самую форму; однако, в нем определены основанные на идентичных понятиях, не на идентичных условиях. Двойной вход не должен быть перепутан с омографами.
3.1.10
concept system (система понятия): Набор понятий, структурированных согласно отношениям среди них. [ИСО 1087-1:2000, 3.2.11] |
3.1.11
concept diagram (диаграмма понятия): Графическое представление системы понятия (3.1.10). [ИСО 1087-1:2000, 3.2.12] |
3.1.12 legacy data (устаревшие данные): Терминологические данные, которые доступны в существующем файле или базе данных и которые рассматривают для импорта в TMS (3.1.2).
Примечание - Устаревшие данные могут быть в форме ранее используемых баз данных, файлов обработки текстов, разграниченных запятой текстовых файлов, SGML, HTML или файлов XML, и т.п. Преобразование таких данных к формату, который будет совместим с новыми TMS, может создать серьезные проблемы.
3.1.13 term (термин): Слово или несколько слов, которые обозначают понятие.
Пример - "Олимпийские игры" и "специальные Олимпийские игры" являются двумя условиями в области спортивных состязаний.
Примечание 1 - Когда слово или слова могут обозначать больше чем одно понятие, каждая пара слова/понятия - отдельный термин. Например, "порт" (приют для лодок) и "порт" (компьютерная точка контакта) являются двумя различными условиями.
Примечание 2 - В теории терминологии термины обозначают понятия в определенных предметных областях, и слова от общего словаря, как полагают, не являются условиями. В TDC, однако, слова от общего словаря иногда регистрируются в терминологических записях, где они все еще упоминаются как "условия".
3.2 Категории данных
3.2.1
data category (категория данных): Результат спецификации поля данных. [ИСО 1087-2:2000, 6.14] |
3.2.2
data element (элемент данных): Единица данных, в определенном контексте, считается неделимым. [ИСО 1087-2:2000, 6.11] |
3.2.3 data granularity (степень детализации данных): Степень точности данных.
Примечание - Например, набор отдельных категорий данных (3.2.1) /часть речи/, /грамматический пол/, и/ грамматическое число/ предусматривает большую степень детализации данных, чем делает единственную категорию данных /грамматика/.
3.2.4 data elementarily (данные): Принцип, посредством чего единственное поле данных должно содержать только один пункт информации.
Примечание - Например, включение полной формы и включение сокращения в той же самой области было бы нарушением принципа данных elementary.
3.2.5 term autonomy (автономия термина): Принцип, посредством чего все условия в терминологическом входе (3.1.4) могут быть описаны при помощи того же самого набора категорий данных (3.2.1).
3.2.6
Data Category Registry DCR (Регистрация категории данных DCR): Набор стандартизированных категорий данных (3.2.1), чтобы использоваться в качестве ссылки для определения лингвистических схем аннотации или любых других форматов в области языковых ресурсов. [ИСО 12620:2009, 3.2.1] |
Примечание - ISO/TC 37 DCR содержит технические требования категории данных (3.2.7), которые включают историческую, описательную, и административную информацию и другие метаданные.
3.2.7
data category specification (спецификация категории данных): Набор признаков, используемых, чтобы полностью описать данную категорию данных (3.2.1). [ИСО 12620:2009, 3.2.2] |
Примечание - Сокращение, которое DCS отсылает к Выбору Категории Данных (3.2.8).
3.2.8
Data Category Selection DCS (Выбор категории данных DCS): Набор категорий данных (3.2.1) отобранный из Регистрации категории данных (3.2.6). [ИСО 12620:2009, 3.2.3] |
3.2.9
complex data category (сложная категория данных): Категория данных (3.2.1), у которых есть концептуальная область (3.2.11). [ИСО 12620:2009, 3.1.7] |
3.2.10
open data category (открытая категория данных): Сложная категория данных (3.2.9), чья концептуальная область (3.2.11) не ограничена перечисленным набором ценностей. [ИСО 12620:2009, 3.1.8] |
3.2.11 conceptual domain (концептуальная область): Набор действительных значений стоимости (3.2.14).
Примечание 1 - Основанное на ИСО/МЭК 11179-1:2004, 3.3.6.
Примечание 2 - Значения стоимости в концептуальной области могут быть перечислены, далее определены дополнительными ограничениями или выражены через описание. Например, категория данных (3.2.1) /термин/ описан его определением и таким образом ограничен от надлежащего содержания, например, контекстной информации или грамматической информации, но было бы невозможно перечислить все ценности, связанные с этой категорией данных.
3.2.12
closed data category (закрытая категория данных): Сложная категория данных (3.2.9), чья концептуальная область (3.2.11) ограничена рядом определенных простых категорий данных (3.2.13). [ИСО 12620:2009, 3.1.13] |
3.2.13
simple data category (простая категория данных): Категория данных (3.2.1) без концептуальной области (3.2.11). [ИСО 12620:2009, 3.1.12] |
3.2.14
value meaning (значение стоимости): Значение или семантическое содержание стоимости. [ИСО/МЭК 11179-1:2004, 3.3.39] |
Примечание - ISO/TC 37 перечислили ценности как простые категории данных, то есть как категории данных самостоятельно. Значение стоимости всегда рассматривается в контексте области общей стоимости и закрытой категории данных, с которой это связано и не является просто собственностью области, ценят себя.
3.2.15
value domain (область стоимости): Набор допустимых ценностей (3.2.16) [ИСО/МЭК 11179-1:2004, 3.3.38] |
3.2.16
permissible value (допустимая стоимость): Выражение стоимости, означающей (3.2.14) позволенный в определенной области стоимости* (3.2.15). [ИСО/МЭК 11179-1:2004, 3.3.28] |
___________________
* Текст документа соответствует оригиналу. - .
3.2.17
thematic domain (тематическая область): Класс заявлений, определенных подобием структур данных, они должны управлять. [ИСО 12620:2009, 3.4.3] |
Примеры - Терминология, лексикография, морфосинтаксис.
3.2.18
thematic domain profile profile (тематический профиль профиля области): Представление той в пределах спецификации (3.2.7) категории данных тематической области (3.2.17), с которой этa категория данных (3.2.1) связана. [ИСО 12620:2009, 3.4.4] |
Примечание - У категории данных может быть несколько тематических профилей области, указывая, что она используется несколькими тематическими областями.
3.3 Моделирование данных
3.3.1
data model (модель данных): Графическое и/или лексическое представление данных, определяющее их свойства, структуру и взаимосвязи. [ИСО/МЭК 11179-1:2004, 3.2.7] |
3.3.2 data modelling (моделирование данных): Процесс структурирования и организации данных, как правило для внедрения в системе управления базой данных.
3.3.3 data modelling variance (различие моделирования данных): Изменение в назначении категорий данных (3.2.1) к моделям данных в результате различий в философии относительно заказа информации в терминологическом входе (3.1.4).
3.3.4
metamodel (метамодель): Модель (3.3.1) данных, которая определяет одну или более других моделей данных. [ИСО/МЭК 11179-1:2004, 3.2.20] |
3.3.5
metadata (метаданные): Данные, которые определяют и описывают другие данные. [ИСО/МЭК 11179-1:2004, 3.2.16] |
3.3.6
global information GI (глобальная информация GI): Техническая информация и административная информация, относящаяся к полному сбору данных. [ИСО 16642:2003, 3.7] |
Пример - Название сбора данных, истории пересмотра.
3.3.7
complementary information CI (дополнительная информация CI): Информация, дополнительная к описанной в терминологических записях (3.1.4) и разделенная через терминологический сбор данных (3.1.1). [ИСО 16642:2003, 3.1] |
Пример - Иерархии области описания учреждения и библиографические ссылки - типичные примеры дополнительной информации.
3.3.8 shared resource (общий ресурс): Информационный объект, к которому можно получить доступ от любых из терминологических или лексикографических записей в терминологическом или лексикографическом ресурсе.
Пример - Общие ресурсы, как правило, включают библиографические записи, записи ответственности, namespace идентификаторы, часто ссылаются на текстовый материал, списки географического положения и внешние файлы, такие как графические или аудиофайлы.
3.3.9
language section LS (языковая секция LS): Часть терминологического входа (3.1.4), содержащего информацию, имела отношение к одному языку*. [ИСО 16642:2003, 3.9] |
___________________
* Текст документа соответствует оригиналу. - .
3.3.10
term section TS (секция термина TS): Часть языкового раздела (3.3.9), содержащего информацию о термине (3.1.13). [ИСО 16642:2003, 3.15] |
3.3.11 class (object class) (класс): Класс объекта.
<UML> Графическое описание ряда объектов, которые разделяют тех же самых участников.
3.3.12 multiplicity (разнообразие): Число случаев одного класса (3.3.11), которое связалось с одним случаем другого класса в установленных отношениях.
Примечание - Например, дата происхождения может быть тем же самым для многих терминологических записей, но у одного терминологического входа может только быть одна дата происхождения.
3.4 Заявления
3.4.1 language planning (языковое планирование): Преднамеренные усилия влиять на поведение человека относительно приобретения, структуры или функционального распределения языка.
Пример - Языковое планирование может включать стандартизацию правописания и грамматических правил, спецификации официальных национальных языков, усилия создать жизнеспособные неологизмы, разработанные, чтобы увеличить способность языка как транспортного средства для научной и коммерческой коммуникации и меры, разработанные, чтобы защитить язык от иностранных влияний.
3.4.2 descriptive terminology (описательная терминология): Подход для руководящей терминологии, которая документирует путь, который называет (3.1.13), используется в контекстах, не указывая на предпочтенное использование.
3.4.3 prescriptive terminology (предписывающая терминология): Подход для руководящей терминологии, которая указывает на предпочтительное использование.
3.4.4 normative terminology (нормативная терминология): Подход для руководящей терминологии, которая используется в работе стандартов или правительственном регулировании.
3.4.5 translation editor (редактор перевода): Программное обеспечение, которое поддерживает процесс создания и пересмотра переводов.
3.4.6 controlled authoring (создание, которым управляют): Создание, которое использует ограниченный словарь и текстовую сложность, чтобы представить четкие документы.
3.4.7
localization l10n (локализация l10n): Процесс взятия продукта и создания его лингвистически и культурно соответствующим целевому месту действия (страна/область и язык), где это будет использоваться и продаваться. [Ассоциация промышленных стандартов локализации] |
4 Системы управления терминологией (TMS)
4.1 Общее описание
TMS программное средство, специально предназначенное для сбора, хранения и предоставления доступа к терминологическим данным. Она используется переводчиками, терминологами, техническими писателями и другими пользователями. TMSs должны быть основаны на принципах терминологической работы, изложенной в ИСO 704, что означает, что терминологические ресурсы, которые созданы при помощи TMS, содержат терминологические записи, разработанные, чтобы зарегистрировать понятия и все условия (синонимы и эквиваленты на других языках), которые обозначают эти понятия.
TMSs, как правило, используются для разработки, поддержания и распространения TDCs в различных организационных структурах, в том числе национальными органами, государственными учреждениями, заинтересованными группами, компаниями и частными лицами. В зависимости от организационной структуры TMS должны будут поддерживать различные функции, задачи и потенциальных пользователей.
Планируя приложение управления терминологией, важно рассмотреть различные возможные типы или категории TMS.
4.2 Коммерческие и некоммерческие TMS
Есть множество инструментов управления терминологией на рынке программного обеспечения; большая часть программного обеспечения коммерческая, но увеличивающееся множество бесплатного программного обеспечения или общедоступного программного обеспечения доступно для управления терминологией. Если организационные, функциональные и методологические потребности соответствующей прикладной окружающей среды удовлетворены системой, она может использоваться с полки. Однако во многих случаях ориентированная на клиента адаптация и регулирование необходимы. Если коммерческое программное обеспечение не может быть адаптировано к определенным потребностям, TMS должны будут быть развиты внутренне. Затраты, обслуживание, поддержка и совместимость - важные параметры, которые должны быть рассмотрены, когда принимается решение между покупкой или арендой TMS.
4.3 Предопределенный или свободно определяемый TMS
Коммерческий TMSs мог предопределить или свободно определить структуры моделирования данных. TMS с фиксированным набором категорий данных, определенным набором языков и/или неизменной модели данных должны только использоваться, если урегулирование будет соответствовать точно потребностям организационной окружающей среды, в которой будут применены TMS. TMS со свободно определимой структурой позволяют пользователям определять свои собственные категории данных и свои собственные структуры входа так, чтобы программное обеспечение могло быть адаптировано, чтобы удовлетворить определенным терминологическим потребностям пользователей и могло быть изменено, когда будущие требования изменяются.
4.4 Настольный, клиент-сервер или Сетевой TMS
Самые простые TMSs установлены на местном компьютере для единственного человека. Иногда основные файлы базы данных хранятся на компьютере LAN и могут быть разделены многократными настольными клиентами. В крупных организациях со многими пользователями (и различными ролями), только TMS с архитектурой клиент-сервер может удовлетворить потребности организации. Эти TMSs требуют установки клиента на каждом местном рабочем столе и установки программного обеспечения сервера, обращающейся с одновременным доступом различных клиентов (с различными задачами).
Если у многочисленных пользователей во всем мире должен быть доступ к терминологическим данным, единственное эффективное решение - Сетевые TMS; пользователи не должны устанавливать программное обеспечение, определенное для TM на их местных компьютерах, потому что стандартный веб-браузер позволит все операции с TMS. Выбирая Сетевые TMS, проектировщики также должны решить, принять ли их собственный сервер или использовать сторонние TMS, например выбирающие между услугами, предложенными крупными поставщиками программного обеспечения TMS или свободной, Резидентской сетью совместной окружающей средой.* Прежде чем решить произвести принимающую функцию на стороне, они должны тщательно взвесить факторы - такой, как строится, экспертные знания хозяина и надежная доступность данных, а также защита информации и конфиденциальность.
___________________
* Текст документа соответствует оригиналу. - .
4.5 Автономный, интегрированный или объединенный TMS
Автономные TMS - автономный пакет программ, разработанный для руководящей терминологии независимо от любого другого применения. Объединение терминологии от автономных TMS в другие заявления, такие как инструменты разработки, которыми управляют, или инструменты Перевода с помощью компьютера (CAT), обычно требует, чтобы терминология была экспортирована от TMS и импортирована в другое применение. Иногда интеграция может быть понята, если развить определенные программные расширения для каждого применения, в котором требуется терминология. Поскольку они не связаны с определенным приложением, эти типы TMS, как правило, предлагают больше гибкости с точки зрения адаптируемости данных для различных заявлений.
Интегрированные TMS - те, которые включают ряд функций управления терминологией непосредственно в рамках другого приложения, такого, как в инструменте CAT. Чтобы использовать интегрированные TMS, пользователь должен установить и использовать пакет TMS вместе с беспрепятственно совместимым номером люкс программного обеспечения. Эти типы TMS разработаны, чтобы предложить функции и особенности, определенно требуемые программным обеспечением, которого они - часть, но как следствие они могли бы забыть включать особенности, требуемые для других заявлений. Например, TMS, объединенные в авторское применение, которым управляют, будут содержать функции и типы данных, требуемые для создания, которым управляют, но оно, вероятно, испытало бы недостаток в особенностях, требуемых процесса перевода.*
___________________
* Текст документа соответствует оригиналу. - .
4.6 Одноязычный, двуязычный или многоязычный TMS
Одноязычные TMSs обычно используются авторами и читателями, которые, вероятно, не вовлечены в перевод или многоязычное производство документа. Двуязычные TMS могут показать простой термин или пары слова, иногда используя лексикографический подход, где Термин A представлен как равный, чтобы назвать B, независимо от любой предметной области, определения или контекста. Они могут также уважать ориентацию понятия, где условия, перечисленные на этих двух языках, принадлежат определенно единственному понятию, и если термин приписан больше чем одному понятию, то каждое понятие зарегистрировано в отдельном входе. Многоязычные TMS обычно ориентируется на понятие из-за трудностей, вовлеченных в управление многократными значениями через многократные языки; некоторые из этих TMSs также допускают двуязычное представление, например, для использования в окружающей среде перевода.
4.7 База данных или структурированный текст TMS
Начиная с TMS должны поддержать огромный объем данных, ядро базы данных обычно бежит на заднем плане. Реляционная база данных - идеальная архитектура для обработки типичных терминологических требований, таких как много условий на многих языках, многократных категориях данных и (неограниченной) воспроизводимости определенных типов терминологической информации. Ориентированный на структурированный текст TMS также отвечает многим типичным терминологическим требованиям, помечая различные типы данных, такой как в XML.
4.8 Единственная база данных или многократная база данных TMS
TMS могут сохранить все терминологические записи в одной единственной базе данных. Различные предметные области, обрабатывая стадии, клиентов и другие типы информации, могут быть классифицированы признаками, и фильтры могут использоваться, чтобы создать виртуальное подмножество базы данных. Другие TMSs хранят терминологические данные в различных физических базах данных, такой что касается различных предметных областей или различных клиентов. Или пользователь должен выбрать одну из баз данных прежде, чем искать и отредактировать, или программное обеспечение допускает одновременный поиск и доступ ко всем базам данных, иногда с определимой иерархией, определяющей, с какой базой данных будут консультироваться сначала. Особый случай последнего - объединенные TMS, которые собирают данные от различных внешних баз данных, потенциально с различными структурами данных.
5 Этапы проекта
5.1 Обзор
Как описано в 4.2, в некоторых целях может быть возможно купить или иначе использовать TMS; однако в других случаях, может быть необходимо развить новые TMS. Процесс осуществления TMS, является ли это третьим лицом или составляющим собственность решением, включает некоторых или все упомянутые ниже фазы. Некоторые проекты, проекты особенно гибкой разработки, которые могут также вовлечь конечных пользователей, требуют итеративного процесса, где несколько фаз повторены, пока желаемый результат не достигнут.
- Проведите предварительное технико-экономическое обоснование (см. 5.2).
- Проведите технико-экономическое обоснование (см. 5.3).
- Проведите анализ случая использования (см. 5.4).
- Установите системные требования (см. 5.5).
- Проанализируйте рентабельность (см. 5.6).
- Проектируйте TMS (см. 5.7).
- Развейте TMS (см. 5.8).
- Разверните TMS (см. 5.9).
- Проверьте TMS (см. 5.10).
- Населите, используйте и поддержите TMS (см. 5.11).
Подробная работа и график времени должны быть установлены, чтобы установить крайние сроки и распределить задачи вовлеченному персоналу. Промежуточные отчеты должны зарегистрировать результаты. График должен ясно указать, когда решения будут приняты, чтобы возобновить проект (так называемое go/no-go решение) и построить ли новые TMS, купить или выбрать существующие TMS, или изменяют существующие TMS. Эти решения могут повториться на различных стадиях в процессе, поскольку требования расположены по приоритетам.
Фазы, описанные в этом пункте, могут быть приспособлены согласно объему проекта и типу вовлеченной организации (коммерческие предприятия, правительственные учреждения, учебные заведения, бюро переводов и т.д.).
5.2 Предварительное технико-экономическое обоснование
Предварительное технико-экономическое обоснование определяет объем проекта и определяет, какие группы пользователей, организационные единицы и системы должны быть вовлечены. Среди заинтересованных сторон и пользователей могут быть люди с определенными ролями в организации (писатели, переводчики и т.д.), организационные предприятия, такие как публикация отделов и услуг по переводу, деловых партнеров и продавцов, и клиентов. Но они могут также включать людей, ответственных за связанное программное обеспечение и системы, такие как системы обработки файла, системы технологического процесса, программное обеспечение для перевода и инструменты разработки содержания.
Может быть решение сознательно исключить единицы или части процесса, определенного здесь, или отложить их до более поздней стадии проекта. Предварительное технико-экономическое обоснование также предоставляет первоначальное описание процесса создания TMS. Это оправдывает потребность в представлении TMS, включая идентификацию любых альтернатив, и определяет основные требования потенциальных пользователей. Организационная окружающая среда, требуемая для осуществления и управления TMS, должна быть обсуждена.
5.3 Технико-экономическое обоснование
Технико-экономическое обоснование включает более усовершенствованную схему задач, которые будут выполнены, а также персонал и финансовые ресурсы, необходимые, чтобы установить и управлять TMS. Технико-экономическое обоснование должно также рассмотреть техническую и организационную интеграцию TMS в полную среду управления информацией организации. Технико-экономическое обоснование должно позволить окончательному принятию решения, должны ли быть осуществлены TMS.
5.4 Анализ случая использования
Проведение анализа случая использования важно для обеспечения, что TMS удовлетворят потребности целевой группы пользователей. Эта фаза описана в 6.3.
5.5 Системные требования
Во время этой фазы определенные требования для спроектированных TMS определены как основанные на обратной связи от прямых пользователей и других заинтересованных сторон. Технические требования характеристики программного обеспечения тогда определены, чтобы выполнить те требования. Компоненты аппаратного и программного обеспечения выбраны согласно предпосылкам, обрисованным в общих чертах в технических требованиях характеристики программного обеспечения.
Как правило, требования расположены по приоритетам, основанным на отзывах пользователей, так как может быть невозможно обеспечить все требования (см. 6.6).
В дополнение к сосредоточенным пользователями техническим требованиям, касающимся инфраструктуры программного обеспечения организации, нужно ответить, например, гарантировано ли соответствие стандартам компании, а также меры безопасности и правила технического обслуживания.
Модель данных для TMS должна быть определена, прежде чем она будет развита или куплена.
5.6 Рентабельность
Затраты на осуществление и работу TMS должны быть оценены, так же как ожидаемая выгода системы. Нужно отметить, что финансовый возврат инвестиций не будет понят до окончания TMS. Любое экономическое обоснование ситуации, которое используется, чтобы определить, одобрен ли проект для финансирования, должно включать неосязаемые, нематериальные преимущества (иногда так называемые "мягкие преимущества") в дополнение к финансовым. Мягкие преимущества включают улучшенное качество и удовлетворенность потребителя, стоят предотвращения через сокращение дублирования работы или другие источники неэффективности и более эффективные процессы (такие, как перевод и обслуживание клиентов). Если несколько альтернативных вариантов все еще возможны в этой фазе (такой как строительство новых TMS или покупка коммерчески доступных TMS), затраты и преимущества должны быть оценены и сравнены для каждого выбора.
Другим фактором являются затраты на неосуществление TMS. Факторы предотвращения стоимости, упомянутые выше, вписываются в эту категорию, но есть другие соображения, такие как судебные издержки фирменного нарушения, которого TMS могли бы помочь избежать, упущенные возможности для создания, которым управляют, и дополнительные трудности в осуществлении системы управления контентом без терминологии, которой управляют. Все потенциальные текущие и будущие применения терминологии должны быть приняты во внимание в строительстве экономического обоснования ситуации.
Затраты на импортирование существующих данных могут быть значительными, особенно если существующий набор данных должен быть изменен до импорта. Средства для импортирования существующих данных, предлагаемых различными системами, которые рассматривают, должны быть вычислены в анализе затрат. Может быть возможно просить, чтобы поставщик существующих TMS развил любой необходимый таможенный конверсионный установленный порядок.
5.7 Cистемное проектирование
Эта стадия включает или поиск и нахождение программных продуктов, которые могут использоваться, чтобы осуществить TMS или проектирование новых TMS. Если несколько программных продуктов доступны на рынке, который может ответить требованиям, каждый должен быть оценен согласно спроектированным требованиям для TMS - включая фактор стоимости - чтобы определить лучшее решение. Если новые TMS должны быть созданы, подробное понятие для системы программного обеспечения и ее компонентов должно быть развито и окружающая среда, и штату для развития программного обеспечения нужно предоставить.*
___________________
* Текст документа соответствует оригиналу. - .
Любые требования для импортирования существующих терминологических данных нужно рассмотреть в дизайне.
5.8 Развертывание системы
Цель этой стадии состоит в том, чтобы развить необходимые компоненты аппаратного и программного обеспечения. TMS и его подсистемы осуществлены, сочиняя новое программное обеспечение или формируя и/или настраивая существующее программное обеспечение, важно зарегистрировать и проверить компоненты и их функцию в пределах целой системы, поскольку они осуществлены.
5.9 Стадии развертывания системы
Стадия развертывания охватывает несколько подстадий и должна быть идеально объединена со стадией тестирования.
Начальное развертывание, особенно на крупных предприятиях, должно показать системный запуск для небольшой группы отобранных пользователей. Во время этого начального запуска должны быть проверены TMS, и любые недостатки должны быть исправлены. Люди, вовлеченные в это начальное развертывание, должны участвовать в тестировании действий и должны экспериментировать с маленьким набором терминологических записей прежде, чем работать с крупными проектами.
Полное развертывание всего предприятия должно быть предпринято только после завершения фазы тестирования, как описано в 5.10.
5.10 Системный тест
Полный тест целой системы (все характеристики программного обеспечения и требования) должен быть выполнен после начального развертывания. Тестирование должно быть основано на полной обработке представительного набора терминологических записей, который является достаточно большим, чтобы бросить вызов системе. Данные испытаний должны быть discardable в случае тестирования неудач. Тестирование должно покрыть все аспекты технологического процесса терминологии и включать варианты развития событий многократного использования. Тестирование должно охватить все характеристики программы (вход, произвести, импортировать, экспортировать, показывает и т.д.) и вовлечь представителей всех пользовательских ролей (терминологи, технические писатели, специалисты по предметной области, переводчики и т.д.). Ручное тестирование может быть увеличено при помощи автоматических методов и установленного порядка и может обеспечить исходные данные, которые могут использоваться позже, чтобы проанализировать выгоду изменений в системе.
Людям нельзя разрешать настраивать их собственную автономную среду тех же самых TMS, пока тестирование не завершено.
5.11 Наполнение TMS, эксплуатация и обслуживание
Как только TMS были развернуты и проверены, система готова к эксплуатации. Полное развертывание вовлекает системных администраторов инструктирования и системных пользователей, установление необходимой инфраструктуры обслуживания и интеграция TMS в полный технологический процесс. Может быть необходимо наполнение TMS первоначально, импортировав существующие терминологические данные. До импорта должны быть рассмотрены данные; модификации в содержании, структуре и формате могут быть необходимыми. Эта задача может занять большое количество времени, таким образом, усилие должно быть оценено, и подходящее время позволено в полном графике. Для получения дополнительной информации об импортировании данных см. 12.2.
6 Пользовательско-ориентированный дизайн
6.1 Основные процедуры
6.1.1 Пользовательско-ориентированный дизайн относится к методологиям и принципам проектирования продукта так, чтобы это удовлетворило потребности пользователей продукта. Цель этого пункта состоит в том, чтобы объяснить, как включать пользователей в процесс проектирования.
В число потенциальных пользователей TMS включаются:
- люди, такие как терминологи, переводчики, переводчики - специалисты по предметной области, учителя, студенты, технические писатели, рекламодатели, проектировщики СМИ и сценаристы, инженеры знаний и информации, языковые инженеры, разработчики продукта, инженеры и т.д.;
- машины и инструменты, что доступ и обрабатывает терминологическую информацию, такую как инструменты разработки, которыми управляют, правописание и блоки проверки грамматических ошибок, двигатели машинного перевода, называют инструменты извлечения, инструменты перевода с помощью компьютера, функции соответствия, поисковые системы, текстовые анализаторы и т.д*.
___________________
* Текст документа соответствует оригиналу. - .
У каждой пользовательской категории есть свои особенности и определенные потребности. Если TMS предназначены больше чем для одной пользовательской категории, общий знаменатель или доминирующие потребности всех пользователей должны быть определены, и эти потребности должны быть расположены по приоритетам по всем другим.
6.1.2 Проектировщики должны определить:
- нормативная ли цель коллекции терминологии, предписывающая, или описательная;
- должны ли TMS быть общим, покрывающим все области или специализированную, рассматривающую только одну предметную область или ограниченное число предметных областей и, если это - последний, какие предметные области должны быть покрыты.*
___________________
* Текст документа соответствует оригиналу. - .
6.1.3 Возможности для поставки информации пользователям с изменением потребностей включают обеспечение:
- многократные представления о терминологических данных (частичные взгляды, некоторые области, скрытые, пока не требуется);
- всей информации, доступной на всех языках или некоторой информации, доступной только на одном языке;
- различные интерфейсы в различных целях (автоматизированное рабочее место переводчика, техническая поддержка письма, взаимодействие с другими компьютеризированными инструментами и т.д.);
- доступ на местной (внутренней), национальной и/или международной основе;
- Интерфейс Web или другой тип интерфейса;
- открытый доступ или доступ, ограниченный определенной окружающей средой.
6.1.4 Проектировщики должны определить, как база данных будет использована. Некоторые типы информации более важны для некоторых пользователей, чем для других. Например, технические писатели должны знать значение технических терминов и как написать термин правильно (капитализация, hyphenation и т.д.), а также какой термин выбрать, когда имеются синонимы. Переводчики, как правило, интересуются нахождением предпочтительного эквивалента для характеристик выброса на данном выходном языке. Программы, которые взаимодействуют с TM, такими как упомянутые выше, должны быть в состоянии получить доступ к различным типам информации, которую они запрашивают.
6.2 Процедуры пользовательско-ориентированного подхода
Принятие ориентированного на пользователя подхода к проектированию TMS позволяет гарантировать то, что созданная система будет проста в использовании и позволит достичь желаемых целей.
Этапы:
- Определите пользователей и их потребности (см. 6.3).
- Определите выходную продукцию (см. 6.4).
- Проанализируйте задачи, которые будут выполнены и создадут случаи использования (см. 6.5).
- Перечислите требования (см. 6.6).
- Проведите оценку конкурента (см. 6.7).
- Подготовьте и оцените дизайн прототипа (см. 6.8).
- Отрегулируйте дизайн в соответствии с отзывами пользователей (см. 6.9).
- Выполните бета-оценку (см. 6.10).
6.3 Идентификация пользователей и их потребностей
Первый шаг в проектировании TMS должны* определить, кто будет использовать его и каковы их потребности. Все потенциальные пользователи TMS должны быть опрошены, чтобы узнать, будут ли они использовать его, как часто они будут использовать его, какие задачи они выполнят и какие определенные потребности они имеют. Проектировщики могут также провести сессии фокус-группы, когда каждый берет интервью, чтобы исследовать более глубоко ответы. TMS должны быть разработаны, чтобы удовлетворить эти потребности и должны быть оценены на нескольких стадиях во время его развития, чтобы определить, как успешно это удовлетворяет эти потребности и ожидания.
___________________
* Текст документа соответствует оригиналу. - .
Различные типы пользователей должны быть рассмотрены способом, который пропорционален их использованию. Например, если есть 1000 переводчиков и 100 терминологов, которые, как ожидают, получат доступ к TMS в Сети, тогда отношение переводчиков к терминологам, которые опрошены на Сетевых функциях, должно быть 10:1. Однако если терминологи проведут вдвое больше времени, обновляя сбор данных как переводчики, отношение должно быть приспособлено соответственно для вопросов о функциях обновления: 10*1:1*2=10:2.
Особое внимание должно быть уделено потребностям, которые, кажется, противоречат друг другу. Иногда, воспринятые потребности одной группы настроены против потребностей другой группы; например, технические писатели и переводчики могут выразить взаимоисключающие требования. Например, предложения контекста (типовые предложения, содержащие термин), могут быть полезны для переводчиков, но не для писателей. В таких случаях может быть возможно удовлетворить и те, и другие потребности, обеспечив определенные для пользователя представления о данных и/или определенные для пользователя технологические процессы.
Обзоры онлайн могут использоваться, чтобы иметь обратную связь от удаленных пользователей, которые не могут посетить сессию фокус-группы лицом к лицу. Подготовка обзора должна включать экспериментальный тест обзора, в котором обзор проверен с небольшой группой, прежде чем провести обзор с полной группой пользователей. Это поможет гарантировать, что правильные вопросы задают в правильном заказе. Фокус-группа для экспериментального теста должна быть представительной для всех типов пользователей, чтобы избежать предубежденных заключений, и шаги должны быть сделаны, чтобы заставить пользователей участвовать в обзоре.
Чтобы утвердить потребности и восприятие, что берущие обзора имеют потребностей, которые они выражают, вопросы должны быть включены, что попытка оценить результаты, которые предполагают берущие обзора, будет получена, осуществляя их предложения. Важно избежать любой двусмысленности в вопросах об обзоре.*
___________________
* Текст документа соответствует оригиналу. - .
В дополнение к идентификации потребностей различных групп пользователей обзор должен предоставить информацию о следующих общих определяющих факторах, учтя и существующие и потенциальные будущие потребности.
1. Какова главная цель TMS?
- Например, если цель состоит в том, чтобы стандартизировать терминологию на одном или более языках, то сбор данных должен быть нормативным. Это означает, что будет проведено в жизнь использование определенных стандартных условий. В этом случае дизайн и методология, принятые для TMS, должны следовать за стандартами ISO для стандартизации терминологии, такими как ИСO 704, ИСO 1087 и ИСO 10241-1. С другой стороны, если цель состоит в том, чтобы улучшить использование терминологии, то сбор данных должен быть предписывающим. Это означает, что должно указать на предпочтенные условия и непредпочтенные условия и включать рекомендации по использованию. Если цель состоит в том, чтобы описать, как термины использованы (не предписывая, как они должны использоваться), то сбор данных описательный. Этот тип терминологического ресурса не указывает предпочтенные или непредпочтенные условия.
- Если сбор данных предназначается, чтобы поддержать поставщика услуг локализации, у которого есть много различных клиентов, то целостность терминологии клиента в пределах TMS главная. Поля данных должны быть обеспечены, чтобы определить происхождение условий, клиента и проектов, где термины использованы, и меры безопасности могут быть осуществлены, допуская защиту данных. В некоторых случаях отдельные сборы данных должны быть предоставлены отдельным клиентам.
2. Все пользователи состоят в компании/организации или некоторые являются внешними?
- Ответ на этот вопрос повлияет на доставку и каналы доступа для данных. Например, в случае основанных на сети TMS, если некоторые пользователи вне брандмауэра организации, специальные меры должны быть взяты, чтобы предоставить им доступ к TMS. Все ли данные о терминологии подойдут и для внутренних и для внешних пользователей? В противном случае будет необходимо так или иначе дифференцировать данные, которые могут быть распределены внешне, от данных, которые не могут, например с помощью специального поля данных. У внешних групп, таких как клиенты и продавцы, может не быть доступа к тем же самым инструментам для использования терминологии. В этом случае важна совместимость данных, что обеспечивается через поддержку международных стандартов обмена (см. ИСO 12620, ИСO 16642 и ИСO 30042).
- Каждый раз, когда многократные версии или копии данных существуют внутренне и внешне, управление версиями и глобальное обновление должны составляться в технологическом процессе и планировании. Однако, нежелательно поддержать многократные версии данных.
3. Все пользователи - опытные профессионалы (писатели, переводчики, терминологи и т.д.) или являются таковыми в других областях, таких как продажи, управление, служба поддержки, обучение, и т.д.?
- TMS, которые служат диапазону пользовательских типов, возможно, должны показать различные типы информации к различным типам пользователей. Если много пользователей могут создать терминологические записи, им также, возможно, понадобятся различные интерфейсы, чтобы создать те записи. Административный персонал не захочет делать запись столько же детализированной информации, как терминологи, и технические специалисты будут нуждаться в информации, представленной из других источников, а не в той, которая требуется переводчикам.
4. Будут какие-либо другие инструменты, такие как система настольной издательской системы или система Translation Memory, должны получить доступ или взаимодействовать с TMS?*
___________________
* Текст документа соответствует оригиналу. - .
- Стадия проектирования должна определить все инструменты, которые могут взаимодействовать с терминологическими данными, и определить, каких данных и форматов они требуют. Машинные процессы могут потребовать данных, которые, как правило, не требуются человеческим пользователям, таким как часть речи.
5. Какие языки TMS должны поддержать?
- Unicode (ISO 10646) является рекомендуемым стандартом кодирования для совместимости с другими системами и поддерживать самый широкий диапазон языков. Все недавно развились, TMSs должен быть Unicode-послушный.
- Выбор UTF8 или выше зависит от языков, которые будут осуществлены и доступная операционная система.*
___________________
* Текст документа соответствует оригиналу. - .
- Если TMS будут включать двунаправленные языки (такие как арабский или иврит), то двунаправленные входные методы и форматы показа должны быть поддержаны.
6. Сколько языков должно поддержать TMS и с точки зрения содержания, и с точки зрения интерфейса?
- Дизайн TMS для одноязычных, двуязычных, и многоязычных терминологических ресурсов будет очень отличаться.
- Одноязычные базы данных развиты прежде всего как справочные инструменты для писателей и других пользователей языка, тогда как двуязычные и многоязычные базы данных развиты прежде всего для переводчиков и многоязычных коммуникаторов. Одноязычные базы данных, типично рекордные больше информации об использовании термина и, имеют тенденцию помещать больше важности в определения. Они также более часто делают запись информации о связанных условиях и синонимах. Двуязычные и многоязычные базы данных, с другой стороны, типично рекордные предложения контекста, категорию данных, которая часто опускается в одноязычных ресурсах. Эти базы данных должны, очевидно, также показать полный спектр категорий данных для ориентированной на перевод терминологии: языковые идентификаторы, комментарии передачи, степень индикаторов эквивалентности, региональных идентификаторов, определенных для перевода комментариев, и т.д.*
___________________
* Текст документа соответствует оригиналу. - .
- Если те же самые TMS предназначены, чтобы использоваться для одноязычных, двуязычных, и многоязычных заявлений, то различные взгляды должны быть созданы для каждого определенного пользовательского типа и деятельности. Каждое представление может скрыть нежелательные области и подчеркнуть важные.
- Для двуязычных или многоязычных TMS проектировщики должны также рассмотреть, будет ли один определенный исходный язык (язык центра) или будут функции поиска базы данных двунаправлены или мультинаправлены относительно входных и выходных языков. Например, когда исходный язык фиксирован, пользователь не может установить язык поиска, и пользовательский интерфейс может быть разработан таким образом, что данные по этому исходному языку всегда появляются наверху экрана. Но в двуязычные TMS, которые поддерживают поиск на любом языке, пользовательский интерфейс, должны позволить пользователю выбирать исходный язык, и результаты поиска могли динамично приспособиться, чтобы показать отобранный исходный язык наверху. В многоязычные TMS, который позволяет поиск* на любом языке, пользовательский интерфейс, должны позволить пользователю выбирать исходный язык плюс один или несколько выходных языков. В любом случае, если определено, что большинство пользователей будет, как правило, выбирать один определенный исходный язык, тогда тот исходный язык должен собираться как язык поиска по умолчанию максимизировать эффективность, но пользователи должны быть в состоянии изменить тот язык при желании.
___________________
* Текст документа соответствует оригиналу. - .
- В пределах многоязычные, ориентированные на понятие TMS, проектировщики должны рассмотреть, как обращаться с ситуациями, включающими квазиэквивалентные понятия: термин A можно считать эквивалентным B на одном языке и C в другом, но понятия, лежащие в основе B и C, могут не быть полностью эквивалентными. Решение должно быть принято относительно того, как обращаться с такими случаями неполной эквивалентности понятия, поскольку это решение может повлиять на основной дизайн TMS. Эти частично эквивалентные понятия могут быть включены в тот же самый вход понятия с областью, доступной для комментариев передачи, чтобы объяснить различие, или они могут быть зарегистрированы в отдельных терминологических записях и соединены как кандидаты перевода.
7. Какие определенные данные делают каждый тип пользовательской потребности?
- Людям, ищущим одноязычную терминологическую информацию, обычно нужны определения и информация об использовании. Переводчикам, очевидно, нужны эквиваленты выходного языка, но они могут часто принимать предложения контекста вместо определений. Определенные для проекта идентификаторы необходимы, если различные эквиваленты для тех же самых характеристик выброса могли бы использоваться для различных проектов. Для больших сборов данных, которые служат различным пользователям и целям, специальные области могут быть необходимыми, чтобы организовать терминологию согласно их потребностям, таким как проект, клиент или идентификаторы продукта. Такие области иногда описываются как выполняющие "подурегулирование" целей, так как они могут быть важны для экспорта подмножеств данных.
8. Как пользователи будут искать и восстанавливать информацию?
- Пользователи должны быть в состоянии искать условия из других приложений, такой как от редактора перевода или текстового процессора?* Они будут использовать Интернет или интранет? Им нужен доступ от мобильных устройств? Им будут нужны фильтры расширенного поиска, или действительно простая строка поиска достаточна? Есть ли какие-либо исполнительные проблемы, которые нужно рассмотреть относительно этих СМИ доступа?
___________________
* Текст документа соответствует оригиналу. - .
- Функции поиска могут допускать нахождение условий, которые подобны критерию поиска (нечеткое соответствие) и находящие условия, основанные на критерии поиска без его наклонов (усечение). Целые классы условий могут быть восстановлены, фильтруя на определенных категориях данных, которые они разделяют вместе, такие как источник термина, идентификатора продукта, особой части речи, или даже даты, что вход был создан или в последний раз изменен.
6.4 Идентификация продуктов продукции
Основываясь на информации, предоставленной целевыми пользователями, проектировщики должны определить, какие виды продуктов продукции этим пользователям TMS нужны, чтобы произвести. Они могут колебаться от традиционных глоссариев (одноязычный, двуязычный или многоязычный), включение, например, только называет и определения, к сложным машиночитаемым выходным форматам, требующим очень гранулированных данных, таким как морфологические и синтаксические данные используемый в программном обеспечении машинного перевода. Некоторая продукция, такая как глоссарии и словари перевода, может лучше всего формироваться со словом - базируемая структура, в то время как другие, такой, как управляется авторские словари* и поисковые системы, могут быть более эффективными с основанной на понятии структурой. Некоторые продукты продукции, такие как спеллчекеры, требуют только термина, в то время как другие требуют полного спектра терминологической и лексической информации.
___________________
* Текст документа соответствует оригиналу. - .
Различные продукты продукции также требуют различных экспортных форматов от простых отделенных от запятой списков до подробного повышения XML.
Чтобы приспособить все эти факторы, проектировщики должны сделать инвентарь всех ожидаемых терминологических продуктов продукции и форматов и категорий данных требуемым поддержать те продукты.*
___________________
* Текст документа соответствует оригиналу. - .
6.5 Выполнение анализа задачи и подготовка случаев использования
Эта стадия включает проведение всестороннего анализа задач, которые будущие пользователи TMS в настоящее время выполняют, и затем развивающий случаи использования для того, как пользователи выполнили бы эквивалентные задачи, а также любые недавно необходимые задачи, используя новые TMS.*
___________________
* Текст документа соответствует оригиналу. - .
Эффективный метод выполнения анализа задачи должен провести встречу фокус-группы лицом к лицу с пользователями. Это включает то, чтобы просить, чтобы пользователи описали типичные задачи, которые они выполняют, которые требуют терминологии, и что их текущие проблемы, выполняя эти задачи.* Проектировщики должны рассмотреть факторы, которые могли изменить способ, которым пользователи выполняют свои задачи и как задачи были бы затронуты. Может быть более эффективно провести отдельные встречи центра с каждым типом целевого пользователя.
___________________
* Текст документа соответствует оригиналу. - .
Пример 1 - Типовой анализ задачи, выполненной переводчиком.
Задача: используйте предписанный термин из словаря проекта во время перевода
Актер: удаленный переводчик
Материал использовал: электронная таблица, содержащая определенную для проекта терминологию
Инструменты использовали: редактор перевода
Описание: В их редакторе перевода у переводчиков в настоящее время есть только доступ к двуязычным словарям, содержащим основные словари. Определенные для проекта словари в настоящее время собираются в формате электронной таблицы менеджером проектов перевода. Электронные таблицы не импортированы в редакторы перевода как интегрированные словари проекта, потому что у менеджеров проектов нет времени, чтобы добавить необходимые обязательные поля (часть речи и идентификатор проекта) и преобразовать файл в разрешенный к вводу формат XML. В результате переводчик только использует электронную таблицу словаря проекта на специальной основе, и терминологическая последовательность не проведена в жизнь. Есть потребность в автоматизированном средстве показа стандартизированных условий проекта переводчикам и возможно для того, чтобы автоматически проверить целевой текст на соответствие указанному терминологическому использованию.
Развивая случаи использования для новых TMS, проектировщики должны определить, кто выполняет задачи, каковы предпосылки, какие определенные данные и инструменты включены, последовательные шаги, которые будут сделаны, и любые определенные взаимодействия, которые произойдут между пользователем и TMS.
Пример 2 - Упрощенные случаи использования, показывающие, как переводчик мог бы выполнить эту задачу в новых TMS.
Задача: используйте предписанный термин из словаря проекта во время перевода
Актер: удаленный переводчик
Инструменты использовали: редактор перевода, словарь проекта
Предпосылка: словарь проекта доступен в редакторе перевода
Описание:
1. Переводя в редакторе перевода, переводчик сталкивается с термином в предложении, которое она переводит, и термин существует в словаре проекта (условия в активном сегменте перевода, которые включены в словарь проекта, должны быть визуально идентифицируемыми).
2. Переводчик выбирает термин в предложении.
3. Переводчик щелкает кнопкой в редакторе перевода пользовательский интерфейс, чтобы показать терминологический вход из словаря проекта (альтернативные способы активации, такие как щелкание правой кнопкой мыши, и клавиши быстрого вызова должны также быть возможными). Словарь проекта открывается входом для отобранного показанного термина.
4. Переводчик выбирает эквивалент из списка вариантов во входе.
5. Переводчик щелкает кнопкой (или альтернативная активация), чтобы вставить отобранное эквивалентное понятие в переведенное предложение.
6. Переводчик щелкает кнопкой (или альтернативная активация), чтобы закрыть словарь проекта и возвратиться к редактору перевода.
Используя инструмент моделирования задачи, возможно добавить условия и альтернативные пути для достижения вышеупомянутой задачи и использовать визуальные пособия, такие как блок-схемы. Например, какие действия произошли бы, если бы словарь проекта не содержал отобранный термин? Какие действия произошли бы, если бы ни один из доступных переводов не был приемлем для переводчика? Какие альтернативные действия могли произойти для локальных переводчиков, у которых может быть доступ к различным ресурсам? Что произошло бы, если бы термин был сокращением другого термина, или у этого термина было сокращение? Словарь проекта должен быть всегда открыт и, если так, является ли сжатым представлением о требуемом входе?
6.6 Идентификация потребностей и их приоритетов
Основываясь на анализе задач и возможном сценарии их выполнения, проектировщики должны составить список требований для TM. Общие требования к ТМ могут содержать:
- создание и обновление терминологических записей непосредственно в системном интерфейсе;
- сравнение данных в двух или больше терминологических записях;
- управление двойным входом;
- импорт и экспорт данных в предопределенных стандартизированных форматах;
- данные о фильтре согласно множеству критериев;
- публикацию данных в Сети или другими средствами.
В окружающей среде, где различные вычислительные системы используются для задач, которые могут быть увеличены с помощью терминологии, такой как создание, управление контентом и перевод, компоненты окружающей среды TMS должны быть совместимыми с этими другими системами, чтобы получить максимальную выгоду от данных о терминологии на предприятии. Например, TMS могут предоставить списки известных условий к инструменту извлечения термина так, чтобы инструмент мог эффективно определить только "новые" условия. TMS могут обеспечить данные для автоматической функции поиска в окружающей среде перевода, чтобы улучшить последовательность терминологии в переводах. TMS могут также быть динамично обысканы системой технологического процесса локализации, чтобы предоставить соответствующие терминологические словари для данного проекта локализации. В авторской окружающей среде TMS могут обеспечить данные, чтобы помочь писателям избегать запрещенных условий и использовать сокращения и акронимы правильно. Как заявлено ранее, у каждого из этих различных применений терминологии есть различные требования, которые должны быть тщательно исследованы.
Как только потенциальные требования были определены, проектировщики должны возвратиться к их фокус-группам, чтобы попросить, чтобы пользователи расположили по приоритетам требования от самого высокого до самой низкой важности. Те требования, которые обязательны, должны быть ясно определены, означая, что без них TMS не будут развиты.
Требования, как правило, располагаются по приоритетам в следующих категориях как первый шаг: (1) важный, (2) важный и (3) хорошо иметь.
Второй шаг должен назначить стоимость на каждый пункт в масштабе 1-5, игнорируя на данном этапе, важно ли это, важно или хорошо иметь. Этот подход допускает создание сетки, представляющей приоритет каждого требования.
В некоторых случаях есть другая категория установления приоритетов, которая отражает некоторую корпоративную стратегию или другое стратегическое или законное требование. Например, у компании может быть политика для поддержки определенных требований доступности для сенсорно ослабленных пользователей, и эти требования могут быть обязательными, нужны ли текущей группе пользователей они.
От типового прецедента использования, на который ссылаются в 6.1.3, возможно определить следующие конструктивные требования. (Следующий список только иллюстративен и не предназначен быть всесторонним).
a) Редактор перевода и словарь проекта должны быть применимыми в удаленной окружающей среде.
b) У терминологических записей должны быть идентификаторы проекта, которые являются распознаваемыми редактором перевода.
c) Терминологические записи должны быть экспортными от сбора данных в форме словаря проекта для редактора перевода, или непосредственно связанные с редактором перевода. Идентификатор проекта поэтому должен быть применимым как экспортный фильтр или, поскольку представление просачивается, интегрированная окружающая среда. Кроме того, требованиям обязательного поля для редакторского переводческого словаря должны отвечать TM.
d) Словарь проекта должен быть доступным независимо от редактора перевода.
e) Редактор перевода должен автоматически выдвинуть на первый план условия, которые находятся в словаре проекта.
f) Редактор перевода должен искать в словаре проекта термин, который выдвинут на первый план в исходном предложении.
g) Поля данных должны быть видимы в словаре проекта, чтобы помочь переводчику сделать соответствующий выбор, когда вход содержит многократные переводы или многократные чувства.
h) Редактор перевода должен быть запрограммирован, чтобы вставить отобранный перевод на целевое предложение. (Этот тип зависимости от внешнего инструмента должен быть определен и решен с разработчиками того инструмента).
6.7 Проведение конкурентоспособной оценки
Чтобы гарантировать, что задачи и требования, которые были определены, не чрезмерно сосредоточены на внутренних процедурах и что они принимают во внимание практику управления терминологии за пределами организации, коллектив дизайнеров должен исследовать способ, которым другие сопоставимые организации обращаются с подобными задачами терминологии. Команда должна оценить другие TMSs, чтобы произвести идеи о том, как осуществить функции. Прежде чем развить новые TMS, команда должна определить, есть ли коммерчески доступные TMS, которые обеспечивают необходимые особенности, и если так, будет ли это более рентабельно, чтобы купить или настроить эти TMS, чем развить новые?
6.8 Проектирование и оценка прототипа
Используя данные, собранные во время предыдущих стадий, проектировщики должны произвести прототип, размышляющий, как TMS будут смотреть и функционировать. Пользователи должны оценить прототип на другой сессии фокус-группы лицом к лицу, куда они идут посредством дизайна и сравнивают его с инструментами и процессами, с чем в настоящее время они работают. Оценки дизайна прототипа должны быть проведены в течение развития продукта. Анкетный опрос или форма комментария должны использоваться, чтобы создать обратную связь от пользователей. Эти данные могут тогда быть по сравнению со статистикой обратной связи в ранее и более поздние стадии, чтобы утвердить дизайн.*
___________________
* Текст документа соответствует оригиналу. - .
Этапы должны быть установлены в графике развития, когда развивающиеся TMS должны будут быть проверены против технических требований дизайна. Это помогает гарантировать, что функции развиты согласно оригинальному вводу данных пользователем.
6.9 Наладка дизайна по отзывам пользователей
На основе обратной связи от сессии оценки прототипа дизайна проектировщики должны внести изменения в дизайн, чтобы исправить слабые места или добавить требуемые функции. Сессии обратной связи должны быть повторены по мере необходимости, пока пользователи не удовлетворены прототипом.
6.10 Выполнение бета-оценки
Перед TMS развернут, это должно быть проверено с пользователями, чтобы определить, оправдывает ли это их надежды и, при необходимости, некоторые заключительные корректировки могут быть внесены, хотя на этой поздней стадии невозможно внести существенные изменения в основной дизайн. Для планирования будущих улучшений также может быть полезно определить основные количественные показатели, такие как время на задаче, число помогает*, и число ошибок, а также качественные меры, такие как удовлетворенность пользователей.
___________________
* Текст документа соответствует оригиналу. - .
7 Терминологическая категория данных
7.1 Введение в категории данных
Терминологические записи составлены из определенных единиц информации, таких как условия, определения и контексты, которые называют категориями данных. ИСО 12620 определяет параметры для определения категорий данных для записи информации, связанной с терминологией и другим языком и ресурсами содержания (например, терминологическими ресурсами, лексикографическими ресурсами, электронными лексическими ресурсами и т.д.). Data Category Selection (DCS), определяемый Терминологией тематическая группа области, которая функционирует под наблюдением TC 37/SC 3/WG 1, должен определить категории данных для записи терминологической информации в компьютеризированной окружающей среде и для обмена и поиска терминологической информации, независимой от местных приложений или окружающей среды аппаратных средств, в которой используются эти категории данных. Терминология DCS включает подмножество глобального набора категорий данных, определенных для использования в лингвистических ресурсах и содержавшихся в Регистрации Категории Данных (DCR, см. //www.isocat.org).
DCS терминологии включает больше чем 200 категорий данных для терминологических данных, которые могут использоваться в качестве имен полей в записях плюс дополнительные категории данных, которые используются в качестве полевых данных. Например, /обозначение данных/категория данных, которая, как правило, была бы именем поля, и мужской, женский, средний категории данных, которые, как правило, происходили бы как ценности этой области.
Список категорий данных в терминологии, DCS всесторонний, потому что это стремится содержать все категории данных от большого разнообразия существующего TDCs. Обычно данная терминологическая база будет только использовать маленькое подмножество категорий данных о терминологии, найденных в терминологии DCS. Категории данных, выбранные для терминологической базы данных (TDB), зависят от технических требований проекта терминологии, его целей и пользовательских потребностей. В большинстве баз данных обычно небольшое количество категорий данных обязательно и остающиеся - дополнительные.*
___________________
* Текст документа соответствует оригиналу. - .
Категории данных, процитированные в ИСО 10241-1 и ИСО 12616, включают:
- условия (на любом желаемом языке);
- связанная с термином "информация" (такие как грамматические признаки, регистр, статус);
- классификация типов термина (таких как правописание вариантов полных форм, сокращенные формы, и т.д.);
- описательную связанную с понятием "информация" (такая, как предметная область (область), определения, контексты, примеры, примечания и графика);
- административную и библиографическую информацию;
- идентификаторы различных видов, например: определить продукты или проекты, с которыми связаны условия;
- даты, имена людей, которые создали или изменили вход или части его;
- статус входа, например представленный, работа одобренная;
- источники условий, определений, контекстов, примечаний, и т.д.
7.2 Принципы для отбора и использования категорий данных
7.2.1 Ориентация понятия
Структуру терминологических записей отличают от того из лексикографических ресурсов в том каждом терминологическом входе, содержит информацию о единственном понятии (или иногда, особенно в многоязычных коллекциях, квазиэквивалентных понятиях), вместе со всеми терминами, которые использованы, чтобы назвать это понятие на стольких языках, сколько желаемо.*
___________________
* Текст документа соответствует оригиналу. - .
Это может быть выгодно, чтобы обеспечить представление о данных, которые устроены в лексической, или основанной на слове, структуре, наряду с традиционным ориентированным на понятие терминологическим представлением. Многие из тех же самых категорий данных используются для обоих взглядов, но они устроены по-другому в показе. Лексическое представление включает все чувства или значения, слова, тогда как терминологическое представление показывает все условия, которые обозначают единственное понятие или значение. Лексическое представление поэтому особенно полезно для понимания всех множеств значений слова, и терминологическое представление полезно, когда пользователь должен определить эквиваленты перевода и синонимы.
Рисунки 1 и 2 графически демонстрируют основные различия между представлением понятия и представлением слова и корреспонденцией между ними.
|
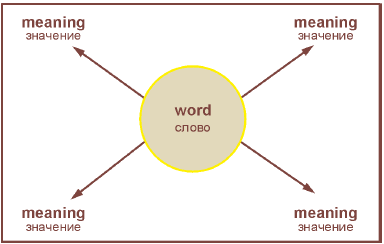
Рисунок 1 - Ориентированный на Word на структуру
|
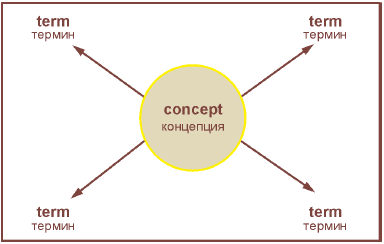
Рисунок 2 - Ориентированный на понятие на структуру
7.2.2 Контекстные и семантические категории данных
Часто может быть трудно различить значение термина, базируемого только на самом термине. Таким образом двуязычные и многоязычные глоссарии издали в Сети, которые обеспечивают только эквиваленты без определений, контексты, или во многих случаях, ограничительные пометы или ссылки предметной области, могут не быть надежными. Пользователей нельзя уверить, что термин выходного языка, предоставляющий такую ограниченную информацию, точен для данного контекста. Хорошо разработанные TMS обеспечат категории данных, чтобы явно сохранить полный спектр информационных типов, чтобы снять неоднозначность значения условий, таких как определения, предметные области, предложения контекста, ценности части речи и т.д. Иногда, однако, пользователям действительно нужны простые списки эквивалентов исходного языка и выходного языка. В этом случае семантическая классификация, такая как предметная область, должна быть ясно обозначена в списке, чтобы разъяснить, в каких контекстах условия релевантны. TMS должны быть способны к экспорту этого типа терминологического продукта с помощью экспортного фильтра на семантической категории данных (/подчиненная область/или другой).
7.2.3 Автономия термина
Согласно принципу автономии термина, должно быть возможно обеспечить равный уровень информации и описания для каждого термина, включенного в терминологический вход. Автономия термина подразумевает, что, даже если один термин идентифицирован как предпочтительный термин, все синонимы и эквиваленты также связаны с полным набором категорий данных. Лучший способ сохранить автономию термина состоит в том, чтобы обеспечить отдельную/term/область для каждого термина, который будет зарегистрирован во вход. /termType/категория данных тогда используется, чтобы указать, является ли термин полной формой, сокращенной формой, акронимом и т.д. /administrativeStatus/ категория данных может использоваться, чтобы указать, предпочтен ли термин, осужден и т.д. Различные дополнительные категории данных доступны, чтобы отличить условия в рамках того же самого входа и предоставить информацию, которая говорит пользователям, какой термин наиболее подходит для данного контекста.
В терминологической базе, из-за принципов автономии термина и ориентации понятия, категория данных /synonym/нe должна быть необходимой. Все условия в рамках входа понятия - синонимы, и у каждого термина в рамках входа понятия есть равный статус как термин.
7.2.4 Воспроизводимость
В теории категории данных могут повторяться так же часто по мере необходимости и могут быть объединены с другими категориями данных, чтобы сделать запись информации о понятии или об одном из условий во входе понятия. Например, категория данных /term/ должна быть повторяемой в языковой секции много раз по мере необходимости, чтобы зарегистрировать синонимы и эквиваленты для данного языка. /term/ категория данных может сопровождаться множеством связанных с термином категорий данных, чтобы описать свойства термина и текстовые категории данных, такие как определение//, /контекст/, и /note/ может быть добавлен /source/ категорией данных, чтобы указать на источник информации. Например, в типовом многоязычном терминологическом входе, показанном в приложении A, /term/ категория данных, наряду со всеми ее связанными категориями данных, повторена для каждого термина в каждом языке (японский язык, английский и немецкий язык). /term/ категория данных добавлена /part of Speech/, /grammatical Gender/ (только для немецкого термина), и /term Type/.
С другой стороны, в зависимости от типа TMS и его цели, можно решить, чтобы некоторые категории данных не были повторимы во входе или части входа. Например, в предписывающие TMS, /definition/ категория данных могла быть ограничена единственным случаем во входе, или как единственный случай для языковой секции, тогда как в очень описательные TMS, /definition/ мог бы быть повторимым. Также часто согласовывается, чтобы для данного входа понятия только одна предметная область применилась и только одна стоимость части речи. TMS должны быть разработаны, чтобы провести в жизнь собственность воспроизводимости данных согласно потребностям пользователей и цели данных.
7.2.5 Степень детализации данных
Терминологические записи должны обеспечить категории данных, разработанные, чтобы приспособить соответствующую степень степени детализации данных. Например, грамматическая информация должна быть зарегистрирована в различных определенных категориях данных - такой, как в следующем примере:
/partOfSpeech/ - существительное
/grammaticalGender/ - женский
/grammaticalNumber/ - исключительный
Объединение многократных свойств в одной общей категории данных не рекомендуется, как в следующем примере:
/grammar/ - существительное, женское, исключительное
Проекты TMS, которые показывают многократные определенные категории данных, более "гранулированы", чем те, которые используют меньше, более общих, категорий данных. Быть провалом, чтобы дифференцировать подтипы информации таким образом может привести к ситуациям, где данные становятся трудными восстановить, управлять и обменять.*
___________________
* Текст документа соответствует оригиналу. - .
7.2.6 Данные elementarity
Категория данных elementarity относится к принципу, посредством чего категория данных должна только держать единственный пункт информации. Пример в 7.2.5 из /grammar/ категории данных, содержащей три различных типа данных (часть речи, пол и число), нарушает этот принцип. Аналогично, если термин и его сокращение оба зарегистрированы вместе в единственной /term/ области, такой как "список контроля доступа (ACL)", этот принцип нарушен. Такие методы распространены в изданных глоссариях, но должны избегаться в терминологической базе. Автоматическая обработка большой части данных становится трудной, если не невозможный, если этот принцип не наблюдается. Например, было бы невозможно искать или извлечь акронимы из базы данных эффективно, если бы они были объединены в той же самой области, как их полные формы. Аналогично, присутствие двух или больше условий в той же самой области вызовет проблемы для инструментов CAT, которые разработаны, чтобы автоматически вставить условия от терминологических записей в документы, поскольку они переводятся.
Решения, затрагивающие степень детализации и elementarity, включают взвешивание преимуществ информационного поиска, предоставленных, предоставляя больше гранулированной информации против иногда увеличиваемого усилия, требуемого войти в информацию в отдельные области. Необходимо соблюдать осторожность во время стадии проектирования, чтобы определить, какие информационные пользователи захотят сделать запись. Отказ обеспечить соответствующие области ввода данных для каждого вида информации может привести к людям, использующим несоответствующие области или входящим в несколько различных видов информации в единственной области, но требующим, чтобы пользователи заполнили больше областей, чем им нужно, может оказать негативное влияние на удобство использования TMS и уменьшить производительность во время ввода данных.
7.3 Типы категорий данных
7.3.1 Открытые, закрытые и простые категории данных
Открытые категории данных могут содержать любой текст, который придерживается их определений категории данных. Например, a /term/область должна только содержать термин, не определение или контекст. Следовательно, /term/категорию данных считают открытой, потому что фактические условия, которые могут быть зарегистрированы, там непредсказуемы. Другие примеры открытых категорий данных - /definition/ и /context/.
Напротив, некоторые категории данных могут только содержать один или больше конечного множества допустимых ценностей, иногда называемых допустимыми случаями. Эти категории данных называют закрытыми категориями данных, потому что их ценности включают закрытый набор. Например, документируя условия в немецком языке, категория данных /grammaticalGender/ может только взять ценности /мужской/, /женский/, или /neuter/. Эти допустимые ценности составляют область стоимости этой категории данных для немецкого языка. Для французского языка, однако, только мужской и женский действительны.
Допустимые ценности в областях стоимости называют простыми категориями данных. Например, /feminine/ - простая категория данных, используемая в качестве стоимости для закрытой категории данных/grammaticalGender/. Они перечислены и определены в особой спецификации категории данных для их соответствующих родительских категорий данных. Их называют простыми, потому что у них самих не может быть содержания. Проектируя терминологический ресурс, важно выбрать определенные допустимые ценности, связанные с закрытыми категориями данных, и обеспечить их как выбираемые ценности (иногда называемый ценностями picklist) в TMS. Например, TMS, используемые, чтобы зарегистрировать французские условия, не должны будут включать /neuter/ гендерную стоимость, потому что нет никакого среднего пола во французском языке. Использование picklists позволяет пользователям выбрать соответствующую стоимость, не имея необходимости печатать его, и это также предотвращает орфографические ошибки или различные формы ценностей от того, чтобы быть введенным в TDC. Например, оставленный их собственным устройством, пользователи могли бы напечатать мужcкой, masc., или просто m. для мужского существительного. Обеспечение однородного представления этих ценностей гарантирует последовательность всюду по TDC, который важен для обеспечения работы фильтров поиска и других задач управления данными.
7.3.2 Обязательный, дополнительный, автоматический и категории данных по умолчанию
Категории данных могут быть или обязательными или дополнительными в TMS. Как правило, TMS не позволят пользователям экономить терминологический вход, если обязательное поле будет пусто. По крайней мере, один термин требуется для каждого терминологического входа.
Другие типичные обязательные поля могут включать информацию о предметной области, которая может быть важна для дифференциации омографов или ценностей части речи, которые также служат, чтобы дифференцировать омографы. Обозначение определенных областей быть обязательным может быть проблематичным. Например, может потребоваться большое количество времени и усилие найти определения и контексты, обсудить их и войти в них в TMS. Может быть более производительным позволить этой информации быть добавленной позже, поскольку это становится доступным.
Некоторое содержание категории данных произведено системой вместо того, чтобы быть заполненным пользователем вручную. Например, многие TMSs автоматически назначают числа входа на терминологические записи, а также делают запись дат создания и дат модификации и имен людей, которые создали или изменили вход. Часть дизайна TMS включает принятие решений об уровнях в рамках входа, который будет зарегистрирован с такой административной информацией. Это вообще недостаточно, чтобы сделать запись такой административной информации только для входа в целом, потому что различные люди могут быть ответственны за различные части входа, специально для различных языковых секций.
Это также возможно, и даже рекомендуемо, чтобы установить значения по умолчанию для определенных категорий данных. Например, если пользователь собирается зарегистрировать условия, связанные с единственным проектом или исходным текстом во время данной рабочей сессии, может быть удобно позволить пользователю задавать ценности для соответствующих категорий данных /source/ или /projectSubset/ так, чтобы все терминологические записи, созданные во время той рабочей сессии автоматически, содержали те ценности. Аналогично, если определено, что большинство условий в TDC будет существительными, это экономит пользовательское время, если /partOfSpeech/ категория данных задана к существительному, и пользователь может изменить эту стоимость для не - существительные.
7.3.3 Только для чтения, читайте - пишут, и скрытые категории данных
В TMS должно быть возможно установить различные уровни доступа для пользователей на полевом уровне, в зависимости от потребностей и роли пользователя. Область, которая видима, но не может быть изменена, является областью "только для чтения". Область, которая видима и может быть изменена, "прочитана - пишут" область. Области, которые не необходимы некоторым пользователям, могут быть скрыты от их представления.
Например, может быть желательно для ведущего терминолога читать - пишут доступ ко всем областям. Этот человек может также быть ответственен за назначение уровней разрешения другим пользователям. Терминологи, создающие записи для определенных языков, должны были читать - пишут доступ к областям в их языковых секциях. Только определенные ведущие терминологи, возможно, читали - пишут доступ к области статуса входа, чтобы установить стоимость в "одобренный". Технические писатели и переводчики, возможно, читали - пишут доступ только к одной или нескольким областям, необходимым, чтобы позволить им предоставлять обратную связь терминологам и права только для чтения на остающиеся области. Часто желательно скрыть категории административной информации, такие как /date/ и /responsibility/ области, чтобы обеспечить менее загроможденное представление о данных для большинства пользователей.
7.3.4 Мультимедийные файлы
Терминологическая база, которая описывает понятия, относящиеся к конкретным объектам, такой как в науке и технических областях, может извлечь выгоду из наличия способности включить мультимедийные файлы, такие как графика непосредственно в терминологические записи. В этом случае области должны формироваться, чтобы сохранить и показать двойные объекты. Область для графики должна быть доступной на уровне понятия, чтобы допускать графику, которая представляет все понятие независимо от языка. Область для графики может также быть обеспечена на языковом уровне, чтобы приспособить ситуации, где объекты, определяемые понятием, отличаются по внешности по различным культурам. Если тот же самый мультимедийный файл необходим для многократных терминологических записей, может быть более выгодно обращаться с ним как с общим ресурсом.
7.3.5 Общие ресурсы
Некоторые категории данных указывают на другие ресурсы, такие как другие файлы (тексты, графика, аудио или видео) или веб-сайты. Эти ресурсы часто называют общими ресурсами, потому что на любой пункт можно сослаться от многих терминологических записей; таким образом это в действительности разделено различными записями.
Библиографические записи - другой тип общего ресурса. Распространено зарегистрировать источник условий, определений, контекстов, примечаний и другой информации, а также источника любых внешних ресурсов (графика, аудио, видео и т.д.). Вместо того чтобы цитировать полную библиографическую информацию в самом входе, это более экономично, особенно если та же самая ссылка используется в многократных записях, чтобы создать отдельный библиографический вход и указать на него от записей при помощи библиографического идентификатора. Эта практика сохраняет принцип экономии данных, потому что это избавляет от необходимости повторять те же самые данные в многократных терминологических записях. Также легче обновить библиографические ссылки, которые происходят в многократных записях, потому что есть только один случай каждого библиографического входа. Исключение к этой практике - цитата URL и URIs ссылка на веб-ресурсы, потому что они уже - короткие, уникальные идентификаторы.
Общие ресурсы могут быть сохранены во внешней базе данных или в отдельном местоположении в самой терминологической базе. Для пользователей должно быть возможно рассмотреть разделенные ресурсы, рассматривая или ища терминологическую базу, потому что эта информация часто крайне важна для оценки терминологического входа.
7.3.6 Отношения между записями
Часто необходимо указать, что термин в одном терминологическом входе так или иначе связан с термином в другом входе.
Иерархические отношения, такие как суперордината и подчиненный, могут быть желательными в терминологической базе, где пользователи должны сделать запись иерархических отношений понятия в некоторой цели, такой, что касается определенных нормативных баз данных, где стандартизация терминологии и суровость определений главные, или для приложений, которые могут использовать такие иерархические данные, например, заявления для управления знаниями или поиска. В этом случае отдельная категория данных для каждого типа иерархического отношения будет требоваться. Такие области должны позволить пользователю уникально указывать на цель отношения, которое может быть входом понятия, или это может быть термин в рамках входа понятия. Например, следующее - представление XML, в TBX (ISO 30042) формат, этого типа категории данных:
<descrip type="broaderConceptGeneric'' target="cid1234''>boat</descrip>
Этот пример мог бы произойти в терминологическом входе для особого вида лодки, такой как "парусная лодка", чтобы указать на вход для более широкого универсального понятия, "лодки". Уникальный указатель обозначен как ценность целевого признака, который является идентификатором входа понятия, который содержит термин "лодка". Содержание элемента, который является "лодкой", не является уникальным идентификатором, так как это слово может представлять несколько различных понятий и таким образом, это может произойти как термин в нескольких различных записях понятия.
Предположим, что вход номер cid1234 содержит несколько условий, определенно "лодка", "судно" и "судно". В этом случае может также быть желательно указать на одно из этих определенных условий в рамках входа. Это будет возможно, если у каждого термина в рамках входа также будет уникальный идентификатор, например:
Concept: cid1234
boat: tid1234-1 vessel:
tid1234-2 ship: tid1234-3
В этом случае связь была бы представлена следующим образом в формате TBX, если пользователь хочет указать определенно на термин "boat" в рамках входа понятия:
<descrip type="broaderConceptGeneric'' target="tid1234-1''>boat</descrip>
Системы понятия могут также быть восстановлены, основанные на письменных числах, разработанных, чтобы представлять положение данного понятия в пределах системы понятия. Обеспечение связей от диаграмм понятия до терминологических записей и наоборот является очень полезным средством визуализации концептуальных отношений.
Системы понятия могут включить неиерархические отношения, такие как ассоциативные отношения или временные отношения. Есть также неиерархические отношения, где тип отношения не определен, такой как просто /relatedConcept/. Некоторые терминологические базы используют этикетку, "см. также" или "видите" для этого типа отношения. Следующее - типовые представления в формате TBX:
<descrip type="relatedConcept'' target="cid2345''>sail</descrip>
<ref type="see'' target="cid2345''>sail</ref>
<ref type="crossReference'' target="cid2345''>sail</ref>
Рекомендуется, чтобы такие отношения были выражены через определяемые области и категории данных, как показано в предыдущих примерах. Этот подход оптимизирует способность к таким отношениям, чтобы быть автоматически обрабатываемым. Для TDC, который включает иерархические отношения понятия, тип отношения должен быть явно выражен при помощи определенных категорий данных, таких как /broaderConcept/.
Некоторые терминологические базы действительно выражают отношения, включенные в других текстовых полях, такой как в определении или примечании. Действительно, условия в определениях часто тесно связаны с понятием, определяемым, и это - популярная практика, чтобы превратить любые такие условия в гиперссылки, которыми можно щелкнуть непосредственно, чтобы открыть связанный вход понятия. Ниже приведен пример двух вызванных условий в формате TBX в типовом определении для термина "sail boat".
<descrip type="definition''>A <hi type="entailedTerm'' target="cid1234''>boat</hi> propelled by a <hi type="entailedTerm'' target="cid2345''>sail</hi>.</descrip>
Безотносительно типа эти отношения могут быть преобразованы в гиперссылки в пользовательском интерфейсе, позволив пользователям нажать на ссылку, чтобы открыть целевой терминологический вход непосредственно.
7.4 Структуры ввода данных
У терминологических баз и терминологических записей есть логическая структура, как описано в ИСО 16642. Эта структура отражена в иерархической модели данных. Категории данных "закреплены" на различных уровнях в этой иерархической модели. Этот процесс называют моделированием данных, как описано в 8.2.
Терминологическая база состоит из глобальной информации (информация обо всем TDC), дополнительной информации (содержащей разделенные ресурсы), и терминологических записей. У каждого терминологического входа есть секция для понятия - связанные категории данных (такие как идентификатор понятия//, /предметная область/, и /определение/), которые сопровождаются языковыми секциями. Каждая языковая секция содержит одну или более секций термина, которые содержат/term/и связанные с термином категории данных (такие как /часть речи/, /грамматический пол/, /регистр/, /тип термина/, и т.д.). Наконец, секции термина могут быть разломаны на секции компонента термина, где компоненты составных или фразовых условий могут быть полностью зарегистрированы. Эти структуры служат основой, на которой закреплены терминологические записи и категории данных.
Некоторые категории данных могут произойти в различных секциях, как позволено по условию модели. Например, предложения контекста (текст, который содержит сам термин) могут быть рассмотрены и как связанные с термином, и как связанные с понятием, потому что они могут предоставить информацию о термине или понятии. Некоторые базы данных позволяют определение только на уровне понятия, тогда как другие позволяют определенные для языка определения в языковой секции. Примечания и категории административной информации могут быть связаны фактически со всеми другими категориями данных и могут поэтому произойти на любом уровне входа.
7.5 Отбор категорий данных
У различных целевых пользователей TMS, включая не только людей, но также и приложения машины (как описано в пункте 6), а также различные продукты продукции, которые TMS, как ожидают, поставят, могут быть различные потребности относительно терминологических категорий данных. Категории данных, процитированные в 7.1, широко используются, но другие могут быть необходимы для отдельных ситуаций, например, что касается локализации программного обеспечения, определенных бизнес-приложений, или стандартизации терминологии и языкового планирования, которое иногда выполняется государственными организациями. Ранее в процессе проектирования, важно определить все категории данных, которые будут необходимы во всех предполагаемых целях TMS. Способность существующего TMSs покрыть необходимые категории данных нужно рассмотреть, решая, купить ли или изменить существующие TM вместо того, чтобы развить новую. Основные добавления категорий данных к существующему TMSs могут быть препятствующими стоимости и, из-за их дизайна, определенный TMSs может быть не в состоянии приспособить определенные дополнения или изменения.
Если есть существующие данные (иногда называемые устаревшими данными), которые должны быть включены в TMS, набор категорий данных в этих данных должен быть оценен, чтобы определить, которые требуются в новых TMS. Посмотрите 8.5. Необходимо соблюдать осторожность, чтобы согласовать названия категории данных с именами, отобранными для новых TMS.
Приложение A предоставляет список типичных категорий данных, сопровождаемых многоязычным терминологическим входом, смоделированным для японского языка, английского и немецкого языка.
7.6 Определенные для перевода категории данных
Условия, появляющиеся в единственном входе на различных языках, как предполагается, являются эквивалентами перевода. Однако иногда понятия, которые они обозначают, не полностью эквивалентны. В этом случае может быть необходимо предоставить информацию о различиях между двумя квазиэквивалентными понятиями или условия, при которых их можно считать эквивалентными, при помощи /degreeOfEquivalence/ категории данных.
/falseFriend/категория данных может использоваться, чтобы указать на термин, который обычно ошибочен, чтобы быть семантически эквивалентным другому термину, часто из-за морфологического подобия, когда фактически у этого есть различные значения. Например, на французском языке, термин ![]() не означает понимать (чтобы узнать), а скорее достигнуть. Два условия, которые являются ложными друзьями, будут, конечно, зарегистрированы в отдельные записи, потому что они представляют различные понятия, но перекрестная ссылка, используя /falseFriend/категорию данных, может сделать явно возможным для пользователей терминологической базы избежать этой потенциальной ошибки. Ниже приведен пример этого типа перекрестной ссылки в формате TBX, как это могло бы произойти во входе, "чтобы понять", где в этом примере tid5678 - уникальный идентификатор термина "
не означает понимать (чтобы узнать), а скорее достигнуть. Два условия, которые являются ложными друзьями, будут, конечно, зарегистрированы в отдельные записи, потому что они представляют различные понятия, но перекрестная ссылка, используя /falseFriend/категорию данных, может сделать явно возможным для пользователей терминологической базы избежать этой потенциальной ошибки. Ниже приведен пример этого типа перекрестной ссылки в формате TBX, как это могло бы произойти во входе, "чтобы понять", где в этом примере tid5678 - уникальный идентификатор термина "![]() ":
":
<termNote type="falseFriend'' target="tid5678''>![]() </termNote>
</termNote>
Другая полезная категория данных - /transferComment/, который может использоваться, чтобы обеспечить дополнительные объяснения об условиях, затрагивающих использование квазиэквивалентных понятий.
7.7 Предписывающие категории данных
Много категорий данных доступны, когда есть потребность предписать терминологию. Например, /administrativeStatus/категория данных может использоваться, чтобы указать, предпочитают ли термин, допускают или осуждают для использования в пределах определенных производственных условий например в коммерческом предприятии. Авторитетные группы, такие как организации стандартов и языковые отделы планирования в правительствах, могут использовать подобную категорию данных, /normativeAuthorization/, чтобы указать на нормативные ограничения использования, к примеру, когда термин был определен в формальном законодательстве.
7.8 Связанные с технологическим процессом категории данных
Как правило, терминологические записи созданы шаг за шагом. Эти стадии могут быть отмечены во входе при помощи категории данных /elementWorkingStatus/, который берет ценности, такие как начинающий, работа, и объединенный, отражая полноту входа и его статуса одобрения. Категория /language-planningQualifier/данных обеспечивает государства технологического процесса для терминологического входа, поскольку она проходит через процесс одобрения в языковой окружающей среде планирования, такой, как предложено, нестандартизированный, предложенный и новый. /processStatus/ категория данных обеспечивает основные необработанные государства технологического процесса, provisionallyProcessed, и завершенный.
7.9 Стандартизированные названия категории данных и понятия категории данных
Как отмечено в 7.1, названия категорий данных и их значений были стандартизированы в DCR. Для TMS, чтобы соответствовать стандартам ISO, должно осуществить и использовать категории данных согласно их значению и описаниям в терминологии DCS ИСО/TC 37 DCR (см. 7.1). Однако при желании, в детали TMS, названия категории данных, которые отличаются от тех в DCR, могут использоваться, при условии, что непосредственное отображение категории данных в DCR возможно. В этом случае администратор TMS может зарегистрировать эти альтернативные имена в DCR. Например, TMS могут выбрать имя "типовое предложение" для категории данных /контекст/, или могут выбрать имя "грамматическая категория" для категории данных/partOfSpeech/. Поддержка определенных для применения названий категорий данных также удовлетворяет потребности TMS, который развит на любом языке, кроме английского языка, так, чтобы, например, у французских TMS могло быть имя "partie du discours" для категории данных/partOfSpeech/. Иногда проектировщики должны добавить новые категории данных к DCR, где они могут быть предложены для будущей стандартизации.
8 Моделирование данных
8.1 Терминологическая метамодель
Модели данных предоставляют формальные описания того, как данные будут структурированы в TMS, и метамодели используются, чтобы обеспечить стандартную архитектуру высокого уровня, за которой могут следовать модели, используемые в единственной дисциплине, чтобы достигнуть совместимости.
Как уже упомянуто в 7.4, ИСО 16642 определяет структуру, разработанную, чтобы дать представление об основных принципах для представления данных, зарегистрированных в TDC. Эта структура включает метамодель и методы для описания терминологического языка повышения (TML), выраженного в XML (расширяемый Язык Повышения). Метамодель ISO 16642 облегчает обмен терминологическими данными и может использоваться, чтобы проанализировать существующий TDC и проектировать новый.
Таким образом определенные модели данных, которые формируют основание для любых TMS, должны быть основаны на универсальной метамодели, определенной в ISO 16642. Эта терминологическая метамодель, в свою очередь, основана на методах и принципах управления терминологией для создания терминологических записей, как описано в ИСO 704.
Метамодель - абстрактная концептуальная модель данных, которая описывает основную иерархию информационных уровней, которым должен соответствовать любой TDC: 1) глобальная информация о коллекции, 2) любая дополнительная информация (разделенные ресурсы, на которые ссылаются всюду по коллекции), и 3) много терминологических записей.
Каждый вход выполняет три функции:
- описывает одно понятие или два или больше квазиэквивалентных понятия на одном или более языках;
- определяет условия, которые определяют понятия;
- описывает сами условия.
У каждого входа могут быть многократные языковые секции, и у каждой языковой секции могут быть многократные секции термина. Каждый элемент данных во входе может быть связан с различными видами описательной и административной информации. Кроме того, есть различные общие ресурсы, на которые могут сослаться одни или более записей. Такие ресурсы включают библиографические ссылки, описания онтологии и изображения, которые иллюстрируют понятия. Для получения дополнительной информации об общих ресурсах см. 7.3.5.
ИСО 16642 также обеспечивает схематическое представление о структуре TDC, который воспроизведен в рисунке 3.
|
Рисунок 3 - Схематическое представление о терминологической метамодели от ИСО 16642
8.2 Данные, моделирующие для ориентации понятия
Одна из самых важных особенностей терминологического входа - своя ориентация понятия. Терминологический вход рассматривает одно понятие. В многоязычных записях обычно понятие - то же самое, независимо от того, которые называют, в котором язык используется, чтобы обозначить понятие. Однако могут быть различия в особенностях понятия для различных языков. В таких случаях можно сказать, что определенные для языка понятия, которые рассматривают в том же самом входе, квазиэквивалентны.
Как показано в рисунке 4, в науках и в технологии, это весьма характерно для концептуального согласия быть столь сильным, что общее восприятие состоит в том, что условия на каждом языке действительно определяют одно и то же понятие. В общественных науках и в культурных исследованиях, однако, некоторые понятия отличаются немного от одного языка до другого, даже когда есть согласие, что условия, обозначающие те определенные для языка понятия, функционально эквивалентны, что означает, что они могут использоваться в целях перевода. Кроме того, синонимы могут существовать в пределах одного языка, такого, что каждая языковая секция может содержать многократные условия. У этих синонимов могут быть незначительные различия в значении или применении, делая их также квази эквивалентами. Можно проявить несколько подходов, чтобы точно отразить эти незначительные различия в значении. Один подход должен проектировать модель данных, которая допускает изменение понятия. Другой должен использовать гомогенную модель понятия, где различия в значении зарегистрированы на уровне категории данных.
Когда два условия выражают то же самое понятие на одном языке, они упоминаются как синонимы, и они должны быть зарегистрированы в том же самом терминологическом входе. Могут, однако, быть различия в стиле или регистре, которые отличают синонимы, означая, что один из них может более подойти в определенных контекстах, чем другой. Эти различия должны быть зарегистрированы в соответствующей категории данных, такой как/administrativeStatus/ или Зарегистрироваться.
Рисунок 4 дает пример многоязычного входа, включающего условия на двух языках, которые определяют единственное понятие, стек протокола. Как имеющая столько понятий в современной науке и технологии, эта особенность интернет-архитектуры развилась во всем мире и известна и обсуждена через культуры. Условия, которые определяют понятие на большинстве языков, являются по существу переводами ссуды английского оригинала. Возможно, метафорическое изображение позади термина, возможно, изменилось, развили термин индивидуально в различных культурах, но это не сделало. Термин стек на английском языке часто используется в ясных контекстах как краткая форма для полного термина формы, и стек пересказа связанных протоколов происходит при случае как своего рода объяснение или синоним. Нет фактически никаких детальных двусмысленностей или различий между языками относительно усилия понятия, следовательно, нет никакой проблемы во включении всех условий в том же самом входе, и при этом нет никакой потребности включать любой комментарий передачи.
|

Рисунок 4 - Многоязычный терминологический вход, документирующий единственное понятие
В некоторых случаях обозначения на различных языках, которые, как считают, практически эквивалентны, не обозначают точно то же самое понятие, как описано в 7.6. Это явление иллюстрировано в рисунке 5, который демонстрирует раздвоение понятия, лежащего в основе немецкого wissenschaftlich, который, когда переведено на английский язык, становится любым научным (для эмпирических наук) или академическим для искусств и гуманитарных наук, наряду с параллельной диверсификацией английского исследования, которое становится на немецком языке или Forschung для стипендии, которая создает новое знание или Исследование для поиска и интеграции имеющихся знаний.
|
Рисунок 5 - Пример отношений эквивалентности между двумя английскими и двумя немецкими понятиями
Рисунок 6 демонстрирует комбинацию этих понятий, которая приводит к четырем различным детальным понятиям, потенциально зарегистрированным в четырех различных терминологических записях.
|

Рисунок 6 - Записи, включающие информацию о понятиях в рисунке 5
Создавая четыре одноязычные записи понятия, пользователь может выбрать, какие одноязычные записи должны быть соединены, чтобы показать квазиэквиваленты. Этот подход более силен для документирования понятий на языковом уровне, чем подход, где все языки находятся в одном входе. Однако наиболее коммерчески доступные TMSs не следуют за этим подходом. Комментарии передачи могли использоваться в многоязычных записях, чтобы объяснить отношения, показанные здесь.
8.3 Прикладные подходы
TDC можно управлять, используя систему управления реляционной базой данных, или он может быть сохранен как структурированные документы с повышением, основанным на форматах, которые, как правило, определяются, используя расширяемый Язык Повышения (XML). Однажды выбор между системой управления базой данных и файлом с повышением был сделан, модель данных может быть развита. Для реляционной базы данных типичный метод описания модели данных является ER (отношения предприятия) диаграмма или UML (объединенный язык моделирования), диаграмма. Для документа XML типичные методы описания модели данных включают DTD (определение типа документа) или схему XML, оба из которых могут быть представлены посредством диаграммы древовидной структуры.
Чтобы соответствовать этому Международному стандарту, все форматы XML и заявления реляционной базы данных на терминологические данные должны быть основаны на:
- метамодель, определенная в ISO 16642,
- модель данных, определенная посредством диаграммы UML, диаграммы ER, ДАТЫ XML или схемы XML, и
- DCS произошел из DCR, определенного в ISO 12620.
Определяя структуру данных TMS, есть два подхода, в зависимости от того, будут ли TMS содержать устаревшие данные. Последняя ситуация описана в 8.5.
8.4 Примеры моделирования данных
Первый шаг должен выбрать категории данных для TMS, основанных на принципах, описанных в пункте 7. Второй шаг должен определить структуру данных, используя диаграмму UML. Третий шаг должен назначить категории данных на их соответствующие положения в той структуре. Получающаяся модель формирует основание для осуществления TMS.
Если данные будут сохраненными в реляционной базе данных, диаграмма UML может использоваться в качестве основания для разработки таблиц базы данных. Если данные будут собранным использованием основанные на XML TMS, диаграмма UML может использоваться в качестве основания для разработки DTD или схемы XML.
Следующий список содержит типовой набор категорий данных, которые используются в следующих разделах, описывающих развитие модели данных для гипотетических типовых TMS:
- Предметная область;
- Определение;
- Отметьте;
- Термин;
- Часть речи;
- Исходный Идентификатор (соединяющийся с определением, термин, контекст, отмечает);
- Контекст;
- Комментарий передачи;
- Возникновение человека;
- Дата происхождения.
Рисунок 7 содержит диаграмму UML, касающуюся вышеупомянутых категорий данных для одного возможного внедрения TM. Коробки показывают классы, и линии показывают отношения (ассоциации) между классами. Для каждого класса дана информация о разнообразии класса, который должен назвать число случаев класса, участвующего в отношениях, а также информацию о том, дополнительное ли участие или обязательное. В UML используются следующие символы:
1 | точно одно возникновение |
0..1 | ноль или одно возникновение |
1..* | один или более случаев |
0..* | ноль, один или более случаев |
В этой модели каждый терминологический вход включает одну или более Языковых секций. Каждый терминологический вход назначен на одну предметную область, но одна предметная область может быть связана с нулем, одной или более терминологическими записями. В примере у каждой языковой секции может быть только одно /определение/, что означает, что там существует "один к" отношениям между Языковой Секцией и/definition/. Ноль означает, что/definition/дополнительный. Те же самые отношения существуют между Языковой секцией и/note/. Во многих случаях определения обязательны, и часто желательно быть в состоянии сохранить несколько определений, например, различные определения, стремящиеся к различным целевым аудиториям. Кроме того, может быть желательно сохранить несколько версий определения, поскольку это проходит несколько стадий одобрения. Это потребовало бы, чтобы информация о разнообразии между Языковой Секцией и/definition/была изменена (1.. От 1 до 0..*). В этой особой модели есть только один /исходный идентификатор/ для каждого /definition/. В случаях, когда ввод для определения найден в источнике, но терминолог изменяет или повторно формулирует определение, может быть желательно быть в состоянии сохранить и оригинальный /исходный идентификатор/ и имя терминолога как источник. В метамодели, определенной в ИСО 16642, определение может также быть в понятии (терминологический вход, TE) уровнем, когда этот/definition/ относится ко всем Языковым секциям. Это не подход, проявленный в модели, показанной в рисунке 7.
Эквивалентность может быть установлена между понятиями на двух или более языках на основе особенностей рассматриваемых понятий. Если два понятия полностью эквивалентны, понятия идентичны и могут быть рассмотрены как единственное понятие. Если почти эквивалентные понятия зарегистрированы вместе в одном входе, это означает, что они разделяют особенности в известной степени, что можно использовать термины как эквиваленты в переводах. /передача комментируют, что/ категория данных дает информацию о природе отношения эквивалентности между двумя такими тесно связанными условиями, сохраненными в единственном терминологическом входе. Например, может быть комментарий к определенным концептуальным особенностям, которые соответствуют между английским и немецким термином и другим комментарием между английским термином и французским термином.
У одного термина могут быть один или несколько источников, и один источник может быть назначен на многие условия, что означает, что есть many-many в отношения между/term/ и /исходным идентификатором/. Есть также many-many в отношения между/term/и /контекстом/, так как один термин может быть найден в нескольких контекстах, и один контекст может содержать несколько условий. В этой модели не всегда будет /контекст/, поскольку/context/дополнительный. Для пользы простоты модель в рисунке 7 показывает только один пункт информации (/часть речи/), связанный с одним термином//, хотя терминологический вход мог содержать множество других пунктов. Так как каждая /часть речи/ стоимость связана со многими условиями, там будет существовать one-many отношения между классами /часть речи/ и TermSection.
|
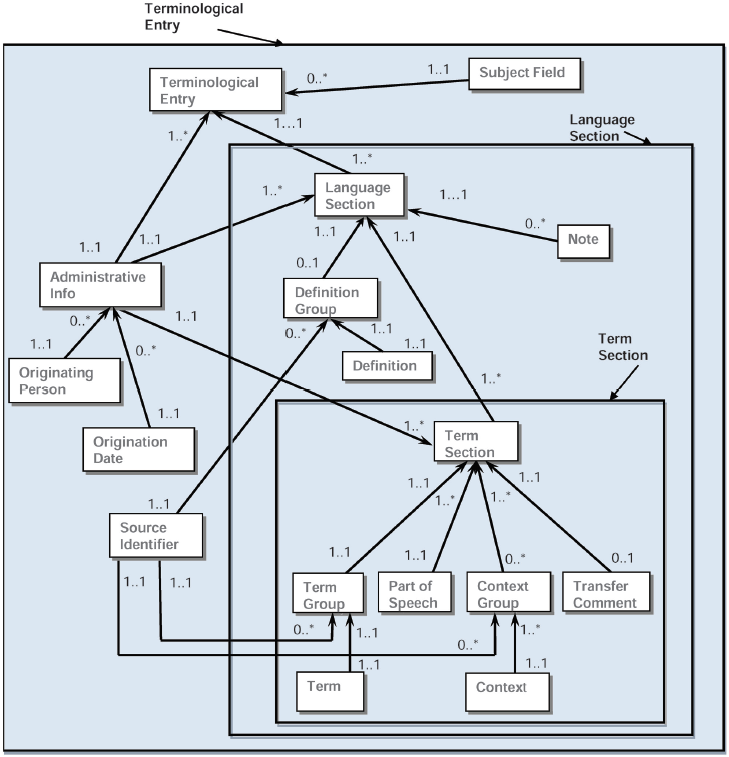
Рисунок 7 - UML изображают схематически для категорий исходных данных
Если TMS должны быть осуществлены, используя систему управления реляционной базой данных, модель данных в рисунке 7 может использоваться, чтобы разработать таблицы базы данных. Рисунок 8 показывает некоторые столы, соответствующие модели в рисунке 7. Названия таблиц и колонок, используемых здесь, соответствуют названиям терминологической метамодели от ИСО 16642 и названиям категорий данных, найденных в DCR.
|

Рисунок 8 - Структура таблицы, соответствующая некоторым классам в модели в рисунке 7
Рисунок 9 показывает DTD, соответствующую диаграмме UML в рисунке 7.
DTD в рисунке 9 отражает структуру, в которой один вход включает одно понятие или два или больше почти эквивалентных понятий без информации об отношениях эквивалентности между понятиями. Пользователи должны обратиться к ISO 30042 и форматам в ISO 16642 (включая Geneter) для стандартного словаря XML. В демонстрационных целях пример определяет фиктивный словарь XML.
|

Рисунок 9 - DTD
Существуют инструменты XML, которые позволяют пользователю написать DTD или схему XML, которая тогда может быть представлена в диаграмме (иерархическое дерево элемента) или потянуть диаграмму, которая тогда может быть представлена в синтаксисе XML. Рисунок 10 содержит иерархическое дерево элемента, отражающее DTD в рисунке 9.
|
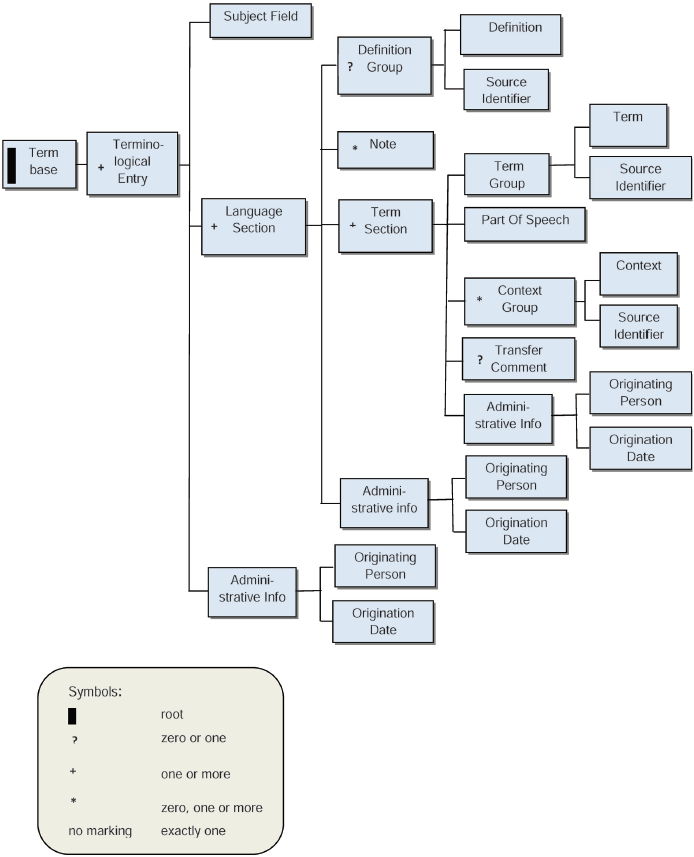
Рисунок 10 - Иерархическое дерево элемента, отражающее DTD на рисунке 9
Рисунок 11 показывает вход от рисунка 4 с признаками XML, соответствующими DTD в рисунке 9 и иерархическому дереву элемента на рисунке 10.
Примечание - В целях простоты и краткости административную информацию не показывают на рисунке 4, и к тому же это не повторено во всех необходимых положениях в данном примере (LanauageSection, TermSection). Это показывают однажды для терминологического входа.
|

|

Рисунок 11 - Завершающий вход от рисунка 4, выполненный с использованием XML
8.5 Составление устаревших данных
Если будет потребность включить устаревшие данные в TMS, то структура и содержание (категории данных) устаревших данных должны будут быть оценены. Соответствующий существующий набор категорий данных? Они приспосабливают принципам, определенным в этом и другом ISO/TC 37 стандартам? Усилие, вовлеченное в изменение категорий данных в устаревших данных, чтобы привести их в соответствие с новыми TMS, должно быть оценено и взвешено против преимуществ. Некоторые категории данных в устаревших данных не могут быть необходимы в новых TMS и могут поэтому быть отказаны, чтобы уменьшить усилие по миграции и сохранять новые TMS незагроможденными. Категории данных в новых TMS, которые требуют значительных модификаций к устаревшим данным, должны быть оценены тщательно, чтобы подтвердить, необходимы ли они, и видеть, могут ли они быть изменены в любом случае, чтобы уменьшить усилие. Может также быть возможно принять стратегию, посредством чего непослушные категории данных в устаревших данных импортированы в новые TMS во временные области только для чтения, которые зарезервированы исключительно для устаревших данных, в то время как недавно введенные данные используют стандартизированные области.
Есть три случая, чтобы рассмотреть:
a) устаревшие данные хранятся в системе управления базой данных, в которой структура сделана явной;
b) устаревшие данные хранятся в плоском файле (например, текстовой процессор или файл электронной таблицы) без явного повышения структуры данных или, возможно, они только существуют в печатной форме, и даже если печатный текст будет просмотрен, то не будет никакого явного логического повышения структуры данных в получающемся файле;
c) устаревшие данные хранятся в XML или другом отмеченном файле, где структура данных явно выражена.
Даже если данные уже хранятся в TMS, в которых структура сделана явной, вероятно, будет необходимым определить новую структуру для новых TMS посредством диаграммы UML, DTD или схемы XML. Старая структура может быть несоответствующей; например, может быть потребность добавить новые категории данных или разделить существующие категории данных.
Если данные уже существуют, но без явного повышения структуры данных [случай b),], моделирование данных потребует выполнения трех шагов:
1) анализ и описание существующих категорий данных и их структуры;
2) создание структуры явных данных, например посредством анализатора или своего рода конверсионной полезности;
3) определение структуры данных, которая должна сформировать основание для осуществления TMS.
Анализ категорий данных в устаревших данных должен быть выполнен при взаимодействии с применением - определенный DCS, описанный в разделе 7. Возможно развить диаграмму UML на основе иерархического дерева элемента в рисунке 10 (представляющий DTD в рисунке 9). Во-первых, все элементы диаграммы от рисунка 10 представлены как классы UML, и информация о разнообразии, которое известно из этой диаграммы, вставлена. Этот процесс приведет к первой диаграмме проекта.
Не вся информация о разнообразии может быть выведена из диаграммы в рисунке 10. Например, одна предметная область назначена на многие понятия, и один человек может быть ответственен за многие понятия. Информация о разнообразии, которое известно из анализа данных, но не представлено в древовидной структуре, должна быть добавлена к диаграмме UML.
В метамодели для ИСО 16642 определения (которые являются своего рода описательной информацией) могут проживать на уровне терминологического входа или на языковом уровне секции. В модели в рисунке 7 определение проживает на языковом уровне секции.
9 Разработка TMS
Разработка TMS имеет место после того, как стадии проекта, описанные в разделе 5, были выполнены. TMS и его подсистемы осуществлены согласно системным требованиям и проектируют приоритеты, развивая новое программное обеспечение или формируя существующий продукт TMS.
Разработчики систем должны работать в тесном сотрудничестве с людьми, ответственными за установление системных требований и описание приоритетов дизайна.
Разработчики систем будут, как правило, также создавать обзор функциональности, который они разовьют, такой как показ макета экранов. Рисунок 12 показывает упрощенный пример такого обзора.
|
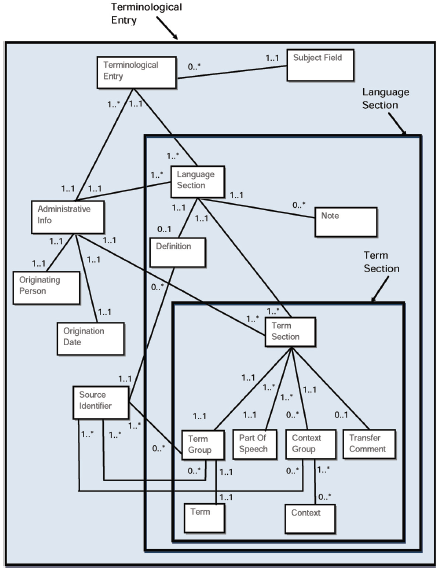
Рисунок 12 - Пример обзора функциональностей в TMS
Разработчики систем будут использовать этот обзор, чтобы создать, например, HTML или страницы PowerPoint, показывая расположение экранов TMS.
Следующий шаг должен фактически развить первый прототип (части) TMS и представить его людям, ответственным за установление системных требований и приоритетов дизайна, а также потенциальным конечным пользователям.
Важно зарегистрировать и проверить компоненты и их функцию в пределах целых TMS, поскольку они осуществлены.
10 Развертывания TMS
10.1 Действия развертывания
Развертывание TMS относится ко всем действиям, которые происходят, позже TMS был развит и проверен, чтобы сделать его полностью готовым к эксплуатации по всей организации. Эти действия включают следующее:
- готовя документацию, помощь онлайн, обучающие программы и образовательные материалы;
- развитие поддержки и плана обслуживания и привлечения необходимых услуг;
- отождествляя любые взаимозависимости с другими частями организации, другими заинтересованными сторонами, и другим программным обеспечением или программами, и гарантируя, что эти взаимозависимости синхронизированы (см. пункты 5 и 6);
- создание предварительного объявления, чтобы предупредить пользователей, что TMS будут выпущены в определенную дату;
- поставка TMS;
- объявление о доступности;
- обеспечение обучения;
- проведение продолжающихся деятельностей по продвижению;
- контроль удовлетворенности пользователей и осуществление отзывов пользователей.
Задачи развертывания фактически должны быть определены и описаны в первоначальном плане для развития TMS, как описано в пункте 5.
Некоторые из этих задач также должны быть выполнены параллельно с этапом разработки, таким как подготовка документации и образовательных материалов, и затрагивающим службу поддержки.
10.2 Подготовка документации, помощи и образовательных материалов
Оптимизировать пользовательское принятие TMS, системных инструкций, вызывает, ответы, функции помощи, и программы обучения должны быть четкими и всесторонними.
Документация, помощь онлайн и образовательные материалы должны быть подготовлены техническим писателем, у которого есть экспертные знания TMS. Писатель - предпочтительно член расширенной группы разработчиков и был вовлечен в проект начиная со стадии проектирования. Писатель должен начать рано и следовать за различными стадиями развития системы. Писатели должны участвовать в обсуждениях дизайна, встречах статуса разработки, сессиях обратной связи удобства использования и маркетинговых планах, чтобы быть хорошо проинформированными обо всех аспектах TMS.
Писатель должен рассмотреть весь текст, который написан разработчиками программного обеспечения, такими как сообщения об ошибках и этикетки пользовательского интерфейса, а также рекламный материал, чтобы гарантировать, что информация ясна и последовательна. Аналогично, другие члены группы разработчиков должны рассмотреть документацию, созданную писателем, чтобы гарантировать техническую точность.
Редактор должен выполнить окончательный обзор документации и других материалов конечного пользователя для стиля и ясности, особенно если несколько писателей создают материалы.
В дополнение к информации о том, как использовать TMS, должна быть описана часть фундаментального понятия управления терминологией и использования терминологии.
10.3 Оказание поддержки и обслуживания
Важно иметь в распоряжении всю поддержку и техническое обслуживание, прежде чем TMS будут развернуты. Это включает штат, подчинение задач и проблемные системы слежения и средство для поставки исправлений и обновлений. Служба поддержки должна быть устроена через формальный контракт, даже если обеспеченный внутренне.
Данные должны систематически прослеживаться для любых проблем, которые возникают, потому что эти данные ценны для прогнозирования будущих требований поддержки.
10.4 Встреча зависимостей заинтересованной стороны
Во время проектирования программного обеспечения и перспективного проектирования были опознаны различные заинтересованные стороны и пользователи TMS (см. разделы 5 и 6).
Перед тем, как TMS будет развернут, важно рассмотреть любые взаимозависимости, которые могут существовать с этими различными заинтересованными сторонами, и принять необходимые меры, чтобы решить их. Например, если TMS предназначены, чтобы быть интегрированными с каким-либо программным обеспечением для перевода или инструментами разработки содержания, план интеграции должен существовать и не должно быть никаких нерешенных проблем, затрагивающих интеграцию. Или, если продавцы перевода будут обязаны использовать TMS, чтобы гарантировать качество перевода, то у них должен все же быть доступ к TMS, как только их обучат пользоваться TMS.
10.5 Реклама и продвижение TMS
Заинтересованные стороны нужно оповестить о фактической дате запуска так, чтобы они могли принять любые необходимые меры в пределах своих собственных команд, чтобы быть готовыми использовать TMS. Объявления должны быть подготовлены загодя и рассмотрены несколькими членами команды.
После первоначальных объявлений некоторая содействующая информация должна быть отослана на периодической основе, чтобы напомнить людям о TMS.
10.6 Поставка TMS
Доставка относится к действиям, требуемым фактически передавать TMS в руки конечных пользователей. Для веб-приложений это означает устанавливать TM на рабочем сервере. Для автономных заявлений это означает упаковывать TMS в СМИ доставки, такие как сжатый файл, который может послать электронная почта или сделать доступным для скачивания в Сети. Функциональность доставки должна также быть проверена, такие как доступ к веб-сайтам, загрузка файлов, уменьшение давления файлов и выполнение установки.
Для автономных заявлений, если обновления должны быть обеспечены на периодической основе, должен быть подготовлен план относительно поставки этих обновлений перед TMS начат.
10.7 Обеспечение обучения
Учебный план должен быть подготовлен как часть оригинального плана разработки программного обеспечения. Учебный план должен конкретизировать типы обучения, которое будет обеспечено, а также состав аудитории, графики, необходимые материалы и т.д.
Более или менее короткие учебные семинары, которые настроены для различных типов пользователей, являются самыми эффективными. Повторите, что сессии потребуются, чтобы приспосабливать доступность людей. Обеспечение загружаемого учебного или записанного заранее учебного представления позволяет пользователям пройти обучение, когда это удобно для них.
10.8 Измерение удовлетворенности пользователей
После развертывания удовлетворенность пользователей должна периодически измеряться, через обзор, например. Результаты должны быть измерены против оригинальных целей TMS и проанализированы для тенденций и образцов. Это поможет утвердить эффективность TMS и определить нуждающиеся области улучшения.
11 Пользовательские интерфейсы
11.1 Проектирование пользовательского интерфейса
Проектирование пользовательского интерфейса является очень важным шагом. Пользовательский интерфейс включает экраны и функции, которые используются людьми, чтобы взаимодействовать с TMS, включая просмотр и обновление терминологических записей, поиск, импортирование, экспорт, создание настроенных профилей пользователя, поддержку системы и т.д. Это также гарантирует, что терминологическая информация представлена соответствующим, однозначным и ясным способом. Хотя общие руководящие принципы и стандарты для проектирования пользовательских интерфейсов для приложений должны сопровождаться, определенные аспекты должны быть приняты во внимание для TMS.
Договариваясь и показывая содержание TMS, типографских соглашений, согласно которым раньше оставляли свободное место в печатных словарях (механизмы сжатия), необходимо избегать, поскольку в ресурсах онлайн есть меньше потребности в компактном показе информации, чем в печатных ресурсах.
Дисплей и механизмы расположения, описанные в следующих подпунктах, представляют разные подходы к проектированию пользовательского интерфейса TMS. Метод, который предпочтен, и наиболее соответствующий целевой группе пользователей, должен быть выбран, и это должно последовательно применяться всюду по целому TMХ. Слишком много изменений между различными методами смутит пользователя, однако различные методы для показа и подготовки терминологических данных могут быть полезны для различных групп пользователей и управленческих задач терминологии.
11.2 Показ терминологических категорий данных
Чтобы показать терминологические категории данных, используйте один из методов, описанных в этой секции.
- Ориентированный на область показ с названием категории данных, предыдущим или помещенным выше области (см. рисунок 13).
|

Рисунок 13 - Название категории Данных, предыдущее и помещенное выше области
- Ориентированный на область показ с названием категории данных в линии сообщения, указывая курсором на область (см. рисунок 14).
|
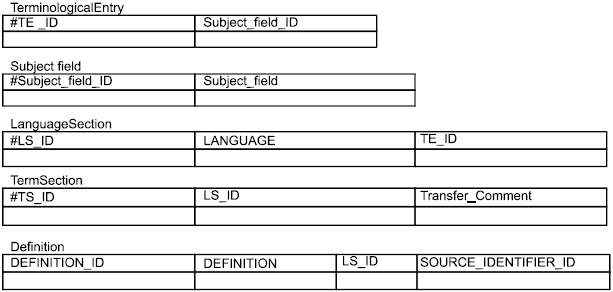
Рисунок 14 - Показ названия категории данных в линии сообщения
- Ориентированный на стол показ с названием категории данных сверху колонки (см. рисунок 15).
Термин | Часть речи | Примечание |
Стек кучи | Существительное | |
Стек памяти | Существительное | |
Стек протокола | Существительное | |
Стек | Существительное | |
Стек связанных протоколов | Существительное |
Рисунок 15 - Ориентированный на стол показ с названием категории данных сверху колонки
- Структурированный показ с текстовым расположением вместо названия категории данных (см. рисунок 16).
|

Рисунок 16 - Используя расположение для различных категорий данных
11.3 Показ и подготовка терминологических записей
Сам терминологический вход - вероятно, самый важный компонент пользовательского интерфейса, так как это используется наиболее часто. Фиксированные шаблоны обычно используются, чтобы устроить информацию о мониторе, но там имеются и другие подходы. Содержание различных категорий данных должно быть представлено в различных областях. Различные расположения показывают 17-21 в цифрах.
|

Рисунок 17 - Фиксированное и определенное расположение
|

Рисунок 18 - Переменное информационное расположение
|

Рисунок 19 - Иерархически структурированное расположение
|

Рисунок 20 - Сжатое расположение
|
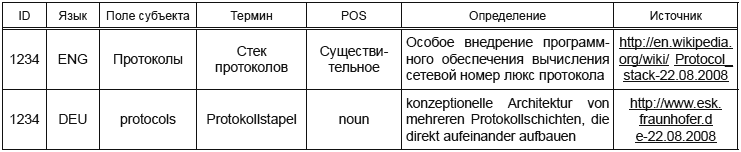
Рисунок 21 - Ориентированный на стол на расположение
12 Ввод и редактирование данных
12.1 Введение данных вручную
TM должны разрешить данным быть введенными вручную. Эта форма ввода данных практична для добавления ограниченных объемов данных. Рисунок 22 показывает типичный пример интерфейса для того, чтобы вручную ввести данные.
|
Рисунок 22 - Пример интерфейса ввода данных
В типовом входе первая секция состоит из Предмета областей (для/subjectField/, связанная с понятием категория данных) и Язык. Следующая секция содержит информацию о термине; эта секция может быть повторена много раз по мере необходимости, чтобы зарегистрировать дополнительные (синонимичные) условия. Третья секция содержит понятие: соответствующая информация (кроме того, чтобы Подвергнуть, который является наверху), то есть, информация, которая действительна для всех синонимичных условий - например, в этом примере, общем определении, ссылке для определения, местоположение (в ссылке) и комментарий.
Идеально, для пользователей должно быть возможно настроить интерфейс ввода данных так, чтобы это содержало только области, в которых они нуждаются. Настраиваемые шаблоны входа могут быть сделаны доступными с этой целью. Несколько шаблонов по умолчанию могли быть сделаны доступными для выбора, основанного на стандартных пользовательских ролях, таких как терминолог, переводчик, технический писатель и т.д.
Рисунок 23 показывает более подробное расположение, которое может подойти для терминолога.
|

Рисунок 23* - Расположение, включающее больше категорий данных
________________
* Рисунок соответствует оригиналу. - .
Интерфейс ввода данных должен разрешить воспроизводимость связанной с термином информации, что означает, что должно быть возможно добавить неограниченное количество условий, включая всю связанную с термином информацию для каждого термина, к терминологическому входу. В интерфейсах, показанных на рисунках 22 и 23, когда пользователь щелкает кнопкой со знаком "плюс" рядом с термином "область", новый набор областей для нового термина добавлен к входу. Эта способность поддерживает принцип автономии термина (см. 7.2.3).
Должно быть возможно изменить заказ условий во входе. В интерфейсе в рисунке 22 термин "заказ" может быть изменен посредством кнопок со стрелкой вверх и стрелкой вниз.
В пользовательском интерфейсе в рисунке 23 возможно добавить новую ссылку, нажимающую на символ карандаша (см. полевую Ссылку для термина в рисунке 23), который откроет страницу для записи информации о ссылке. Это - пример picklist области, где новые ценности должны часто добавляться, даже в момент редактирования входа; поэтому добавление новых ценностей не должно быть ограничено системным администратором. В пользовательском интерфейсе в рисунке 23 также возможно нажать на символ лупы, чтобы искать определенные ссылки. Кроме того, возможно настроить список ссылок при помощи функции, доступной от строки меню. Рисунок 24 показывает изображение экрана для создания ссылки на печатный ресурс. Это - пример общего ресурса.
|
Рисунок 24 - Экран для создания ссылки
Пользовательский интерфейс должен осуществить закрытые категории данных, такие как, например, /предметная область/, /язык/, /часть речи/, и /source/ ссылка посредством picklist областей. Использование picklist областей предотвращает ошибки ввода данных. Системный администратор должен быть в состоянии определить эти ценности picklist, когда база данных первоначально формируется. Администратор должен также быть в состоянии добавить новые ценности и изменить показанный формат ценностей в любое время (см. 12.5 касательно показа ценностей). Создание и модификация большинства типов ценностей picklist должны быть ограничены определенными пользовательскими ролями, такими как системный администратор, чтобы сохранить целостность данных. Рисунок 25 показывает ценности picklist, доступные в вышеупомянутом пользовательском интерфейсе и интерфейсе для обновления набора языковых ценностей.
|

Рисунок 25 - Меню с ценностями разворачивающегося списка и интерфейсом для обновления списка языков
Для TMS важно предотвратить нежелательный двойной вход во время ручного ввода данных. Как минимум сообщение должно быть показано, если пользователь попытается добавить термин, поверхностная форма которого соответствует существующему термину в базе данных. Конечно, должно, тем не менее, быть возможно создать отдельные терминологические записи для условий, у которых есть та же самая поверхностная форма, но различные значения, чтобы приспособить омографы. Если пользователи печатают в двойном термине, система должна помочь им решить, представляет ли термин, который они хотят добавить, новое понятие (то есть это - омограф), или нежелательный doublette, позволяя им проверить существующие записи, которые содержат термин с соответствующей поверхностной формой. Рисунок 26 показывает, как могла бы работать интерактивная проверка doublette. Когда пользователь нажимает на ссылку для существующего термина, существующий вход показан.
|

Рисунок 26 - Интерактивная проверка doublette
12.2 Импортирование данных
Существующие терминологические данные в машиночитаемой форме могут обычно передаваться терминологической базе посредством функции импорта. Данные, вероятно, придется реструктурировать (см. также 8.5).
TMS должны допускать импортирование промышленного стандарта файлы XML для терминологических данных, например, форматы XML, которые выполняют ИСО 16642, такую как семья TBX, форматируют (ИСО 30042):
a) определенный пользователями формат XML;
b) разграниченные текстовые файлы.
Существующие терминологические данные в машиночитаемой форме могут обычно передаваться терминологической базе посредством функции импорта. Данные, вероятно, придется реструктурировать (см. также 8.5).
TM должны допускать импортирование промышленного стандарта файлы XML для терминологических данных, например, форматы XML, которые выполняют ИСО 16642, такую как семья TBX, форматируют (ИСО 30042):
1) приложите новые записи в базу данных;
2) приложите поступающий вход в существующий вход;
3) замените существующий вход поступающим входом;
4) проигнорируйте поступающий вход и сохраните существующий вход в целости;
5) замените данные от базы данных с импортированными данными и синхронизируйте на числах входа и возможно других категориях данных, таких как область предмета//.
Обычно, эти функции учитывают только один язык, как отобрано импортером.
В выборе 2, если вход в файле импорта содержит термин, у которого есть та же самая поверхностная форма, как термин в базе данных, новые категории данных могут быть добавлены к существующему входу. В выборе 3, если вход в файле импорта содержит термин, у которого есть та же самая поверхностная форма, как термин в базе данных, существующий вход будет заменен (переписанный). Это действие также предполагает, что эти две записи описывают то же самое понятие, но в этом случае только информация в файле импорта хранится. В выборе 4, если вход в файле импорта содержит термин, у которого есть та же самая поверхностная форма, как термин в базе данных, будет проигнорирован вход в файле импорта (пропустил), и существующий вход останется неизменным. Это действие могло подходить для одного из двух сценариев: (1) эти две записи описывают то же самое понятие, но информация в базе данных более точна, и информация в файле импорта должна быть проигнорирована, или (2) эти две записи описывают различные понятия, таким образом, существующий вход должен быть сохранен, и вход в файле импорта должен быть добавлен, возможно позже в ручном способе входа. С этой целью установленный порядок импорта должен произвести регистрацию, перечисляющую любые проигнорированные записи импорта.
В выборе 5, файл импорта содержит числа входа, которые соответствуют числам входа в базе данных. Этот выбор, как правило, используется, чтобы импортировать данные, которые были ранее экспортированы от TMS. Иногда более производительно внести глобальные изменения, или партия редактирует к большим количествам записей, редактируя экспортируемый файл вместо того, чтобы пытаться сделать это непосредственно в базе данных. Импортированные записи заменяют существующие, но система сначала проверяет, чтобы удостовериться, что числа входа и любые другие указанные категории данных являются тем же самым, прежде чем сделать замену.
Передовой TMSs должен предоставить средства для интерактивного двойного входа, проверяющего во время импорта, позволив пользователю решить, импортировать ли термин, поверхность которого формируют матчи из другого термина в базе данных.
Пользователь должен быть в состоянии импортировать подмножества категорий данных, которые присутствуют в файле импорта, и игнорируют других. Например, импортируйте только отобранные языки, проигнорируйте категории административной информации, такие как даты или проигнорируйте определения в файле импорта.
12.3 Редактирование данных
Идеально, пользовательский интерфейс для редактирования данных должен быть похожим на интерфейс для ввода данных, и это должно обеспечить те же самые особенности.
При редактировании у пользователя должна быть возможность видеть оригинальный вход без изменений. Оригинальный вход можно, например, показать во всплывающем окне, когда пользователь нажимает кнопку (рассмотрите оригинальный).
Когда вход будет отредактирован одним пользователем, система должна захватить его, чтобы препятствовать тому, чтобы другие пользователи редактировали тот же самый вход.
12.4 Утверждение данных
Функции подтверждения правильности данных необходимы, чтобы минимизировать ошибки во время ввода данных или редактирования. Системы базы данных Most уже предлагают некоторые из этих возможностей, но, если специальное программное обеспечение ввода данных развито, желательно включать функции проверки.
Пример - В качестве примера подтверждения правильности данных:
- проверка двойного входа: решить, что термин сохранен только однажды;
- проверьте правописание: решить, что все терминологические записи выполняют предопределенные правила правописания;
- проверка характера: проверить типы характера, используемые в поле ввода;
- проверка полноты: гарантировать, что данные присутствуют при необходимости;
- проверка формата: решить, что данные соответствуют указанному расположению;
- проверка правдоподобия: решить, что стоимость соответствует указанным критериям;
- проверка достоверности: проверка, основанная на известных условиях или ограничениях, которые относятся к данной информации или результату.
Очень важная особенность регистрирует изменения, которые колеблются от информации в день, на которой вход или область были созданы или обновлены, к личности пользователя, ответственного для разнообразия, к более подробным регистрациям предыдущих версий, дав полную историю всей информации в базе данных. Например, может быть полезно быть в состоянии видеть все предыдущие версии определения.
12.5 Автоматическое воспроизведение или изменение данных
Некоторые данные могут быть автоматически воспроизведены, такие как имя человека, который создал или изменил вход и любые связанные даты.
Должно быть возможно определить значение по умолчанию для некоторых областей, или для данной сессии или через целые TMS. Например, во время сессии работы, если бы терминолог создавал многократные записи понятия в пределах того же самого языка и предметной области, он повысил бы производительность, если/language/область и область предмета / / могли бы быть предварительно заполнены требуемыми значениями. Значение по умолчанию всей системы может быть желательным для определенных областей, которые являются преобладающими во всей системе. Например, у /части речи/ область могло быть значение существительное по умолчанию, если предопределено, что большинство условий в базе данных будет существительными. Это повышает производительность, не требуя, чтобы пользователь выбрал часть речи для каждого входа. Для пользователя должно, конечно, быть возможно изменить эти ценности в любое время.
Должно быть возможно внести изменения в показ ценностей picklist автоматически через все TMS. Кодексы должны использоваться, чтобы определить языки, предметные области, подмножества и другие ценности picklist, внутренне в TMS. Каждый кодекс соответствует легкой в использовании поверхностной форме, которая видима в пользовательском интерфейсе. Например, у потребительского подмножества для Компьютеров Высшей точки могли быть внутренний кодекс AC и поверхностные Компьютеры Высшей точки формы. Эти кодексы и поверхностные формы должны быть сохранены только однажды в TMS. В отдельных терминологических записях ссылки на стоимость picklist сделаны внутренне при помощи кодекса, но пользователь видит и выбирает поверхностную форму. Если название компании изменяется позже, такой относительно Информационных технологий Высшей точки, изменение поверхностной формы внесено только однажды в центральном входе и кодексе, AC остается неизменным. Это позволяет всем поверхностным формам быть автоматически обновленными во всех терминологических записях. См. пример в рисунке 24 и информацию об общих ресурсах в 7.3.5.
12.6 Добавление перекрестных ссылок
Должно быть возможно добавить ссылки к другим терминологическим записям, таким как связь с входом для вызванного термина, который использован в определении или другом текстовом поле, даже если у термина в тексте нет той же самой поверхностной формы как термин в связанном входе. Например, должно быть возможно связать множественную форму "порты" в определении к входу, который содержит термин "порт". Связи могут указать на термин в рамках входа понятия или к самому входу понятия, и они не должны быть неоднозначными, например, при помощи формы термина для резолюции связи (который предотвратил бы "порты" от того, чтобы быть связываемым к "порту"). Слова могут иметь множество значений, когда каждое отдельное значение слова включает различный термин, и каждый должен быть зарегистрирован в отдельном входе. В этом случае использование поверхностной формы термина для резолюции связи приведет к ситуации, где связь указывает на многократные записи. Однозначные связи должны быть установлены при помощи более подробных критериев, таких как комбинация термина ID и ID понятия.
TMS должны предотвратить недействительные перекрестные ссылки и связи. См. также 7.3.6.
12.7 Добавление мультимедийных файлов
Терминологическая структура входа должна позволить связи с мультимедийными файлами и другими ресурсами, например, графика, аудио, AVI (Аудио Видео Интерфейс), видео и т.д. Должно также быть возможно включать гипертекстовые ссылки в Сетевые ресурсы. Включение карт изображения, связывая области изображения к терминологическим записям, может быть желательным. Рисунок 27 показывает вход, который включает мультимедийный файл. Нажатие на символ показывает увеличенную версию файла.
13 Функции поиска
13.1 Функции поиска базы данных
Как во всей базе данных или информационно-поисковых системах, функции поиска в TMS должны позволить пользователям быстро получить доступ к желаемой информации.
Большинство типичных пользователей интересуется нахождением информации о термине или понятии. Например, они хотят прочитать определения термина, чтобы понять его значения, они должны искать выходной язык, эквивалентный для текста, который они переводят, они хотят подтвердить правописание слова или проверить контексты, в которых это используется, или они должны знать, есть ли у термина сокращения или синонимы.
Терминологи и администраторы TMS могут потребовать, чтобы более сложные поиски целей управления данными, например, нашли записи, которые были обновлены в определенную дату или определенным человеком, чтобы найти записи, которые содержат двойной вход, чтобы найти записи, где определенные области пусты, и т.д. Терминологи, заинтересованные в завершении освещения TMS, могут извлечь выгоду из систематических поисков.
Типичные пользовательские сценарии включают:
- переводчики или поиск localizers эквивалентного выходного языка;
- эксперты по предметной области или технические писатели, ищущие определение;
- переводчики или писатели заинтересованы информацией об использовании термина;
- языковые планировщики или люди, ответственные за корпоративный язык компании, кому нужна информация обо всех условиях, представляющих понятие, включая их нормативный статус;
- терминологи, которым нужна любая информация о понятии и его отношениях к другим понятиям;
- администраторы базы данных, которые должны найти терминологические записи согласно широкому диапазону параметров в целях обслуживания базы данных.
Все типы поиска, фильтрации и просмотра возможностей, требуемых всеми пользователями TMS, должны быть определены во время стадии проектирования (см. раздел 6).
Должно быть возможно сохранить поисковые запросы и критерии фильтрации, а также другие определенные для пользователя поисковые параметры настройки (такие, как расположение результатов поиска, см. раздел 14) в профиле пользователя для повторного использования позднее.
Термин | Часть речи | Примечание |
Стек кучи | Существительное | |
Стек памяти | Существительное | |
Стек протокола | Существительное | |
Стек | Существительное | |
Стек связанных протоколов | Существительное |
Согласно //creativecommons.org/licenses/by-sa/3.0/)
Рисунок 27 - Показ мультимедийного файла
13.2 Поиск термина
Большинство поисков выполнено при помощи термина в качестве строки поиска. Так как пользователь не будет знать, какие условия фактически сохранены в TDC, несколько механизмов поиска должны быть сделаны доступными.
- Точное совпадение: пользователь печатает термин, и система показывает вход или все записи, содержащие термин.
- Автоматическое усечение: пользователь печатает начало термина, и система показывает все записи с условиями, которые начинаются со строки поиска. Это автоматическое правильное усечение также поддерживает поиск полученных форм.
- Явное усечение и дикие карты: пользователь включает один или несколько символов группового символа (такой, как * и?) в критерии поиска, чтобы определить положение, где усечение или маскировка должны быть применены. Групповые символы могут быть в начале, в середине или в конце строки поиска, и должно быть возможно использовать больше чем один групповой символ за поиск. В некоторых случаях может быть полезно войти только в звездочку (*) как строка поиска, чтобы восстановить все записи или сочетать эту функцию со сложным поиском (см. 13.4). Обратите внимание на то, что в больших базах данных восстановление всех записей может быть не рекомендовано, так как это может замедлить исполнение системы.
- Нечеткое соответствие: пользователь печатает строку поиска, и система показывает все записи с условиями, которые подобны строке поиска. Этот механизм допускает восстановление орфографических вариантов, склоняемых или полученных форм условий и омофонов. Особенность нечеткого соответствия также необходима для автоматического поиска условий в рамках текста, используя программы извлечения термина или приложения Translation Memory, которые получают доступ к TMS.
- Поиск изолированного слова и перестановка: пользователь печатает критерий поиска мультислова, и система показывает все записи с условиями, которые содержат единственные части (слова) критерия поиска или все части критерия поиска в различном порядке слов. Этот механизм подобен поведению поисковых систем во Всемирной паутине.
- Игнорирование специальных знаков и капитализации: пользователь печатает критерий поиска, и система показывает все записи, содержащие термин, игнорируя различия в случае присутствия дефисов, знаков пробела или диакритических знаков.
Функция поиска должна восстановить все типы условий: полная форма, сокращенные формы термина, орфографические, стилистические и региональные варианты.
Для нечетких поисков и поисков с групповыми символами можно рекомендовать ограничить число восстановленных категорий данных, например позволив только сам термин в списке результатов. Каждый перечисленный термин может включать связь со своим полным входом. Пользователи могут тогда нажать на ссылки, чтобы показать подробную информацию об условиях, которые они хотят видеть. Иначе поиск может возвратить такую информацию, что на системную работу можно повлиять.
13.3 Поиск числом понятия или особенностями
TMS, который делает запись особенностей понятия, отношений понятия, систем понятия или других онтологий, должны показать небуквенные систематические возможности поиска. Систематический поиск включает поиск положением понятия в пределах системы понятия, или одной из ее особенностей, или проводя через графическое представление основной онтологии.
Поиск при помощи числа входа понятия полезен для терминологов, которые управляют TMS. Число входа понятия часто регистрируется в отчетах, которые произведены, чтобы проверить последовательность сбора данных или когда данные импортированы или экспортированы. Терминолог иногда должен искать сбор данных числом входа, чтобы решить проблемы, определенные этими отчетами. С этой целью идентификаторы входа должны быть постоянными.
13.4 Сложная фильтрация и поиск
Сложная фильтрация вместе с поисками часто используется, чтобы ограничить число результатов поиска в большом TDC и определить подмножества целого сбора данных для печати и экспорта данных (см. раздел 14).
Пользователь может только интересоваться понятием от данной предметной области в английском термине, который только использован в Канаде в акрониме, который предпочтен определенной компанией в терминологическом входе, который не является старше трех лет, или в понятии с определением, взятым из определенного документа. Комбинации всех этих критериев фильтра должны быть возможными. Поэтому TMS и его функция фильтра должны позволить доступ к любой категории данных в модели данных, и должно быть возможно объединить условия запроса с логическими операторами, такими как И, ИЛИ и НЕТ. Может быть полезно, если стандартные Булевы операторы расширены дополнительными операторами - такой, как "больше, чем", "меньше, чем", "содержит" и т.д. Например, может быть полезно отфильтровать для всех записей понятия, которые были созданы после или перед определенной датой или всеми записями понятия, которые делают, или не включать определение.
TMS должны допускать комбинацию таких функций, и поставка предназначалась для областей, чтобы помочь пользователям определить поиски, такие как предметная область//, связанные с датой параметры (прежде чем, после, на, и между определенной датой или датами), /географическое использование/, /клиент/, /проект/, /продукт/ и т.д.
13.5 Поиск в текстовых полях
Поиск в текстовых полях позволяет пользователю искать условия или другую информацию в текстовых полях, таких как область определения и область контекста. Этот вид полнотекстового поиска обычно требует больше времени, чем индекс-ориентированный поиск термина.
13.6 Просмотр
Иногда пользователи хотят просмотреть TDC, ничего не ища в особенности и поэтому не определяя критериев поиска. Пользователи должны быть в состоянии просмотреть целый TDC, подмножество данных, определенных, определяя критерии фильтра, или в списке результатов поиска. В зависимости от модели данных и терминологической информации, хранившей в каждом входе понятия, просмотр может быть буквенным или систематическим использованием основной онтологии.
После поиска термина пользователи иногда хотят видеть условия прежде и после него в алфавитном порядке, так называемый "буквенный район" термина.
14 Вывод данных
14.1 Типы вывода данных
Вывод данных включает все манеры, которыми данные представлены вне основной базы данных, включая путь, которым данные показаны после поиска, связались с другими заявлениями и экспортировали в файл.
14.2 Показ результатов поиска
В зависимости от типа поиска и используемых стратегий фильтра, TMS покажут только восстановленный терминологический вход или записи. В некоторых случаях только первые из нескольких терминологических записей, соответствующих критериям поиска пользователя, появятся со средством (таким, как выпадающий список, или отделят список совпадений) перемещения в следующий вход в последовательности. Если есть больше чем один получающийся вход, показывая количество общего количества записей, которые соответствуют, критерии поиска помогает пользователю решить, расширить ли или сузить критерий поиска.*
___________________
* Текст документа соответствует оригиналу. - .
Пользователь должен быть в состоянии настроить показ результатов поиска, например, выбрать языки, категории данных и, до некоторой степени, их договоренность. Эта информация расположения, как правило, хранится в шаблонах расположения или профилях показа. Несколько популярных расположений должны быть предопределены и сделаны доступными. Рекомендуется позволить пользователю предлагать, чтобы новый термин добавил к терминологической базе, когда поиск не возвратил результатов (такой как в предложении, посланном терминологу). С этой целью некоторые TMSs делают запись неудачных вопросов файлу системного журнала, который терминолог может использовать позже, чтобы добавить новые условия к базе данных.
В некотором TMSs результат вопроса показывают в столе обзора или в списке. Пользователи могут выбрать одни или более характеристик выброса, чтобы показать определенные записи понятия со всей релевантной информацией. Например, рисунок 28 показывает обзор понятий в рамках подготовки к почве предметной области.
|

Рисунок 28 - Результат поиска фильтрован для подготовки к почве предметной области
14.3 Сортировка
Некоторые TMSs позволяют пользователям сортировать результаты в данном заказе и производить сортированные распечатки. Это должно быть возможно благодаря содержанию отобранных областей ограниченной стоимости, такого, как предметная область или источник. В терминологических базах, которые содержат онтологические отношения, должно быть возможно сортировать продукцию и в алфавитном порядке и систематически, т.е. согласно положению понятий в системе понятия.
Рисунок 29 показывает пример частичной системы понятия для годовых отчетов. В этой диаграмме коробки представляют записи понятия с разграничиванием особенностей, добавленных ниже. На "основе" особенностей были добавлены критерии подразделения, чтобы разъяснить особенности разграничивания связанных понятий. Поиск годового отчета в термине область, фильтрованная для этических проблем или этичная в полевых характерных особенностях, приведет к входу для понятия этический отчет. Пользователь нажимает на коробку, чтобы показать полное изложение о понятии.
|
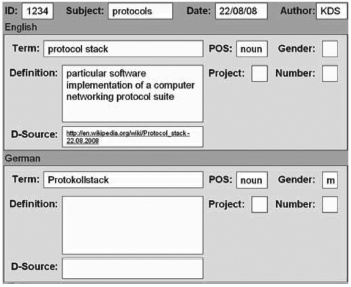
Рисунок 29 - Частичная система понятия для годовых отчетов
Рисунок 30 показывает систематический список, произведенный на основе информации о местонахождении в рисунке 29. Этот вид списка особенно полезен, когда группа терминологов и экспертов предметной области встречается, чтобы обсудить определения понятия определенной предметной области. Используя этот список, возможно видеть определения координационных понятий и проверить последовательность в определениях. Пользователь нажимает на ссылки (условия), чтобы видеть полные записи.
|

Рисунок 30 - Систематический список, соответствующий системе понятия, показанной в рисунке 29
Это должно быть возможно согласно нескольким критериям, например, сначала на основе предметной области и затем в алфавитном порядке. В обзоре результата в рисунке 31 условия, принадлежащие системе понятия в рисунке 29, сортированы в алфавитном порядке.
|
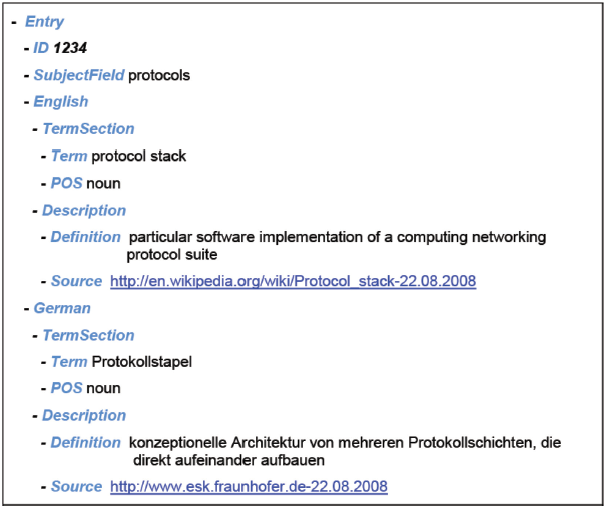
Рисунок 31 - Алфавитный список результатов поиска
14.4 Распечатки
Данные о TM или фильтрованные подмножества этого должны быть пригодными для печатания. Stylesheets может использоваться, чтобы произвести различные расположения от экспорта ХML. Поиски могут использоваться, чтобы произвести алфавитные списки всех понятий, принадлежащих системе понятия, такие как та, что в рисунке 29, и печататься как, показано в рисунке 32.
|
Рисунок 32 - Алфавитный список английских условий с датскими эквивалентами
В некотором TMSs также возможно произвести систематический список для печати целей, как та, что на рисунке 30. Список включает различные формы (аудиторский отчет, аудиторский отчет и отчет аудитора).
|
Рисунок 33 - Алфавитный список английских условий с датскими эквивалентами, определений и комментариев
14.5 Экспорт данных в файл
TMS должны позволить данным экспортироваться в файл. Это полезно не только в определенных целях распределения, но также и потому что экспортируемые данные могут использоваться в качестве резервной копии базы данных (при условии, что файл разработан так, чтобы это могло использоваться, чтобы восстановить базу данных полностью).
Экспорт данных от TMS является распространенным способом предоставить данные другим пользователям или другим заявлениям, которые требуют терминологии. Подходящие механизмы выбора (такие, как выбор определенного языка или фильтрующий для предметной области) должны быть доступными, чтобы ограничить экспортируемые данные подмножеством полных записей в базе данных. Кроме того, должно быть возможно ограничить экспортируемые данные указанным набором категорий данных, например, исключить административную информацию, или информация, такая как контекст приговаривает, источники или ценности части речи.*
___________________
* Текст документа соответствует оригиналу. - .
TMS должны допускать экспорт по крайней мере в один промышленный стандарт формат ХML для терминологических данных, таких как форматы, которые совместимы с TBХ или Geneter. TMS должны также поддержать экспорт в следующие форматы:
- определенный пользователями формат XML;
- RDF;
- разграниченные текстовые файлы;
- пригодный для печатания формат (см. 14.4).
14.6 Экспорт данных для других заявлений
Различные типы экспорта могут требоваться для других заявлений, такой что касается систем управления контентом, внося в указатель инструменты, инструменты разработки, которыми управляют, записывая и контролеров стиля, системы машинного перевода и инструменты CAT.
Во время стадии проектирования должны были быть определены продукты продукции, которые должны быть произведены TMS (см. 6.4). Каждый продукт продукции, вероятно, потребует настроенного экспорта, и некоторые потребуют пост - обрабатывающий добавлять представляемые стили, такие как используемые в глоссариях, которые изданы в Сети. Некоторые TMS поставляют готовые шаблоны, чтобы применить эти стили, но настроили XSLT stylesheets, может приспособить большинство других потребностей.*
___________________
* Текст документа соответствует оригиналу. - .
Некоторые продукты продукции потребуют определенных категорий данных. Например, словари машинного перевода, как правило, запрашивают более подробную морфологическую информацию, чем ориентируемые на пользователя терминологические продукты, и словари для авторских программ, которыми управляют, требуют подробных определителей использования и совета использования. Эти подходы также запрашивают больше информации на общем языке, чем обычно обеспечиваемый терминологическими продуктами.
Экспортные форматы для этих различных заявлений могут колебаться от простых разграниченных запятой текстовых файлов до подробных файлов XML. Некоторые продукты продукции, такие как одноязычные глоссарии и даже некоторые словари CAT, требуют, чтобы ориентированная на слово структура сосредоточилась на пообещанном или термине и его свойствах или переводах. Другие, такой, так управляются авторские словари, требуют ориентированной на понятие структуры, чтобы дать представление писателям при отборе предпочтительных условий, когда сталкиваются с выбором синонимов. См. также 15.6 об обмене.*
___________________
* Текст документа соответствует оригиналу. - .
15 Организация и управление TMS
15.1 Создание плана управления
Организация и управление TMS - сложная задача, которая требует диапазона специальных навыков и опыта. Долгосрочный план управления должен быть определен с учетом всех областей применения и всех групп пользователей и заинтересованных сторон, а также организационных и технических факторов. Все задачи и процедуры должны быть зарегистрированы подробно.
15.2 Важность управления потоком данных
Сложные TMSs требуют сложной степени разделения труда. Терминологические, библиографические и фактические данные для работы TMS созданы, приобретены, пересмотрены, обработаны, объединены, обменены с внешними партнерами, сделаны доступными и для внутренних и для внешних клиентов, и т.д., различных людей. Управление потоком данных избегает дублирования данных и конфликтов данных, несправедливого разделения труда или неэффективного технологического процесса.
Данные в TMS постоянно изменяются. Чем больше людей работает с TMS и больше сбор данных, тем больше управления потоком данных необходимо. Поток данных должен быть выражен в блок-схемах обработки данных, которые показывают переходы между различными процедурами.
15.3 Изменение модели данных
Создатели TMS не могут быть уверены, что модель данных, определенная вначале, будет всегда удовлетворять потребности пользователей. Анализ ошибочных образцов, исправление ошибок, рассмотрение запросов об улучшениях, оценка пользовательских поведений и поддержка новых пользователей или распространение освещения базы данных являются всем продолжающимся техническим обслуживанием, которое может заставить добавлять, изменять или удалять категории данных, изменять структуру записей или, в некоторых случаях, пересматривать целую модель данных.
Изменение модели данных и структур данных обычно требует изменений установленного порядка программного обеспечения, пользовательского интерфейса и процедур управления потоком данных. Любые изменения TMS могут потребовать обновлений системы справочной информации и письменной документации также.
Изменения в модели данных окажут значительные влияния на TMS. Модификации к структурам данных существующего TDC могут вызвать технические проблемы и могут потребовать обширных ручных обновлений записей. Модификации не должны быть сделаны, если они не будут ясно оправданы. Незначительные модификации должны быть отложены для включения в будущее системное обновление.
Модификации к структурам данных существующего TDC нелегко осуществить. Если новые категории данных добавлены, существующие записи должны или быть добавлены соответствующими новыми категориями данных или отмечены как неполные, чтобы гарантировать последовательность данных. Удаление категорий данных может привести к потере данных. Даже если это предназначено, копия TDC должна быть сделана и заархивирована до удаления категорий данных. Трудности, вероятно, возникнут, когда значение или цель категорий данных будут изменены или, когда категории данных слиты или разделены, поскольку может быть тогда необходимо пересмотреть каждый вход. Это может иметь место, если изменения внесены, например, в системе классификации предметной области TDC.
Прежде чем изменить модель данных или структуры данных TDC, резервная копия данных должна быть создана и сохранена в безопасном местоположении. Некоторые TMSs используют экспортный процесс для поддержки данных; другой TMSs может сделать полную резервную копию базы данных без экспорта. Экспортируемые данные, возможно, должны быть изменены, используя внешние утилиты, прежде чем они смогут быть повторно импортированы в недавно структурированную базу данных.
Это неблагоразумно или даже невозможно - работать с двумя различными версиями базы данных в одно и то же время, то есть с новой и старой версией. Во время внедрения новой версии пользователям нельзя разрешить использовать TDC. Любые модификации к структурам данных, модели данных, установленному порядку программного обеспечения и пользовательским интерфейсам должны быть зарегистрированы подробно, с указанием на дату, тип модификации и причины осуществления изменения.
15.4 Обеспечение защиты информации
Защита информации часто путается с защитой данных. Эти тесно связанные понятия относятся к различным аспектам операции по базе данных. В то время как защита данных стремится предотвращать воровство данных или неправильное употребление, защита информации стремится гарантировать целостность данных. Очень важно рассмотреть меры безопасности в фазах планирования и внедрения базы данных и не ждать, пока неудача еще не произошла.
Защита информации TMS может быть подвергнута опасности следующих инцидентов:
- физические угрозы (огонь, воровство, перебой в питании);
- дефекты аппаратных средств (дисковая катастрофа, нечитабельная среда);
- дефекты программного обеспечения (системное расстройство, конфликты данных, вызванные параллельным доступом);
- пользовательская ошибка (неумышленное удаление, неправильные данные).
Меры безопасности против физических угроз обычно обеспечиваются отделом IT, ответственным за операцию окружающей среды базы данных. Меры по противопожарной защите, противоугонные меры, uninterruptable источники энергии и безопасное закрытие, поддерживая резервные копии базы данных и другие меры, которые гарантируют от неудач, - безопасная работа TMS, все улучшает защиту информации. Неудача программного обеспечения и пользовательская ошибка никогда не могут предотвращаться полностью. Чтобы увеличить защиту информации, рекомендуется всестороннее тестирование программ и пользовательского поведения перед тем, как TMS помещен в активное использование. Использование категорий данных с ценностями picklist может предотвратить вход непоследовательных данных. Например, обеспечивая picklist, состоящий из существительного, глагола, прилагательного, для части речи препятствует тому, чтобы пользователи использовали переменное примечание, например, существительное, n., глагол, v, прилагательное, прил., все в той же самой терминологической базе. Использование определенных разрешений и ролей может помочь предотвратить неподходящую модификацию данных.
Самая важная мера по безопасности против любой неудачи - резервная копия сбора данных и системы программного обеспечения. В тот момент, как только будет необходимо поддержать программное обеспечение, прежде чем произойдет модернизация, сбор данных должен быть скопирован на другие СМИ равномерно, иногда даже ежедневно. Должны быть сохранены несколько версий резервных копий, и они должны быть распределены в различных местоположениях так, чтобы они не были все разрушены в случае неожиданных бедствий (огонь, воровство, землетрясения, наводнения и т.д.). Весьма распространено сегодня поддержать критические данные в распределенной Сети или интранет-окружающей среде. Главный TMSs может также управлять скоординированными зеркалами сайта, которые могут также служить безопасными хранилищами данных в случае непредвиденных обстоятельств.
В случае неудачи резервные копии не могут восстановить текущее состояние базы данных. Они могут только восстановить его государство с момента, когда данные были в последний раз поддержаны. Модификации, сделанные после этого пункта, часто трудно воспроизвести. Системы программного обеспечения, используемые в больших базах данных, делают запись каждой модификации данных в файле. Если этот файл все еще доступен после неудачи, последняя резервная копия и файл могут использоваться, чтобы восстановить базу данных.
Быстрое время отклика, предотвращая системные отключения электричества и минимизируя пользовательские ошибки, улучшает пользовательскую уверенность и удовлетворение.
15.5 Управление доступом
Распространено использовать основанные на программном обеспечении процедуры, чтобы управлять доступом к TMS. Механизмы управления доступом особенно важны в многопользовательской окружающей среде. Они регулируют доступ к системе программного обеспечения посредством пользовательской идентификации. Пароли не должны ни быть видимы на экране, ни легко предполагаемыми, и число возможных попыток ввести пароль должно быть ограничено.
Позволенное паролем управление доступом часто связывается с назначенным уровнем доступа к данным, обычно называемым ролью. Роли регулируют точно, какие группы пользователей наделены правом читать или написать, на который части данных.* Таким образом, системные специалисты, терминологи, переводчики, технические писатели или конторский штат могут иметь отличающийся прочитанный, написать и удалить разрешения для различных категорий данных. Когда терминологические данные сделаны доступными через системы общедоступной сети, или когда данными снабдят на CD-ROM или DVD, эти системы и СМИ должны быть разработаны, чтобы предотвратить несанкционированное копирование данных или загрузку больших количеств данных.
___________________
* Текст документа соответствует оригиналу. - .
15.6 Поддержка формата обмена
Важное условие для обмена терминологическими данными состоит в том, чтобы модель данных и категории данных были явными, чтобы надлежащее использование данных в пределах целевого применения получения было гарантировано. Поэтому TMS должны поддержать стандартный формат обмена, такой как TBX (ИСO 30042) или Geneter. Поддержка формата обмена промышленного стандарта снижает риск, что данные станут несовместимыми с другими заявлениями или использованием, даже непредвиденными. Это также освобождает TMS от ограничений собственных форматов.
15.7 Укомплектование персоналом TMS
Обеспечение - это достаточный штат, чтобы управлять и поддержать TMS, что важно. Сотрудники обязаны управлять сообщениями об ошибке и запросами об улучшениях, предоставлять услуги помощи, решать проблемы, осуществлять новые функции, управлять развитием новых выпусков и развивать и поставлять документацию и обучение. Когда коммерческое управленческое программное обеспечение терминологии используется, эти задачи по большей части выполнены поставщиками программного обеспечения.
Штат должен также быть доступным, чтобы управлять аппаратными средствами, включая периферию. В больших TMS эти задачи выполнены техническим штатом отдела поддержки IT, в то время как менеджерам меньших TMS, вероятно, придется выполнить эти задачи самим.
Квалифицированные терминологи обязаны управлять терминологическими данными. Терминологи также отвечают на запросы информации и советы пользователей. В зависимости от размера и сложности организации и миссии рабочей группы, эти роли могут быть распределены среди различных людей и групп. Технический персонал может складываться из множества существующих ролей в организации: технические писатели, информационные специалисты, переводчики, терминологи и люди с навыками IT могут быть скоординированы, чтобы создать настроенные команды.
Продвижение и обучение, возможно, должны быть повторены на периодической основе. См. также 10.2.
15.8 Управление затратами и руководящими ресурсами
Стратегический контроль затрат может включить следующие шаги:
- анализ затрат и преимуществ;
- анализ организационных дефицитов;
- анализ максимальных и минимальных мощностей;
- предоставление для инноваций и роста;
- продукт и сервисные стратегии;
- анализ сторонних зависимостей;
- анализ риска, основанного на сравнении между текущим состоянием и целевым государством.
Заключительный анализ рентабельности должен быть выполнен, как только TMS полностью готовы к эксплуатации. Если проект был хорошо запланирован с самого начала, и никакие неожиданные подрывные факторы не затронули его прогресс, окончательную стоимость - анализ прибыли должен отразить предсказания в начальном анализе рентабельности. Однако подробный анализ рентабельности, который выполнен, когда TMS полностью осуществлен, может показать непредвиденные факторы, или положительные или отрицательные. Эти факторы должны быть тщательно проверены, и, при необходимости, могут требоваться некоторые организационные изменения, например, чтобы укомплектовать уровни или распределить задачи. Если оказывается, что некоторые терминологические продукты или услуги находятся в большем требовании, чем ожидалось, меры должны собираться вместе и иметь дело с этим требованием.*
___________________
* Текст документа соответствует оригиналу. - .
Как со всеми формами финансового контроля, будет также требоваться продолжающийся учет издержек. Идеально анализ учета издержек должен быть встроен в TMS, чтобы автоматически представить отчеты о регулярной основе.
Анализ затрат-выгод может привести к планированию дальнейших улучшений, дополнительных продуктов или услуг, но планы развития должны быть умерены с анализом степени риска возможных исходов, если рост происходит слишком быстро или слишком медленно.
Контроль затрат включает:
- идентификацию и выполнение минимального объема проекта;
- достижение удовлетворенности потребителя самым эффективным развертыванием ресурсов;
- вычисление доходности терминологических продуктов и услуг;
- развитие дальнего обнаружения сигнализирует для узких мест относительно мощностей штата;
- планирование аппаратного и программного обеспечения инноваций и модернизации, чтобы поддержать удовлетворенность потребителя, а также обновив методы, продукты и услуги;*
___________________
* Текст документа соответствует оригиналу. - .
- обеспечение продолжающейся подготовки кадров, чтобы гарантировать непрерывность соответственно квалифицированного персонала.
Чтобы гарантировать долгосрочный успех, TM и его полная инфраструктура должны учитывать:
- количество данных об увеличении и качество;*
___________________
* Текст документа соответствует оригиналу. - .
- развитие терминологических продуктов и услуг, которые пользуются спросом, и постепенное сокращение тех, которые не пользуются спросом;
- постоянное улучшение его собственной организации;
- систематическое развитие внешних совместных отношений;
- действие рентабельным способом.
Приложение A
(справочное)
Тематические исследования: категории данных и моделирование данных
Типовой список категорий данных:
/entryNumber/
/subjectField/
/languagelD/ (ISO 639 language code, repeatable by language)
/term/ (group repeatable for all synonyms and equivalents)
/transferComment/
/degreeOfEquivalence/
/partOfSpeech/
[Closed data category: /noun/, /verb/, /adjective/, /adverb/]
/grammaticalGender/
[Closed data category: /masculine/, /feminine/, /neuter/, as needed]
/grammaticaINumber/
[Closed data category: /singular/, /plural/, /dual/, as needed]
/termType/
[for instance: /full form/, /transcribed form/, /symbol/, /variant/, /abbreviation/, as needed]
/register/
/termStatus/
/definition/
/context/
/example/
Категории данных, повторяющиеся и соединяющиеся в течение входа
/note/
/graphic/
/sourceldentifier/(or/source/)
/terminologyTransaction/
[for instance, /origination/, /input/, /modification/, /check/, /approval/]
/responsibility/
/date/
Многоязычный терминологический вход:
|
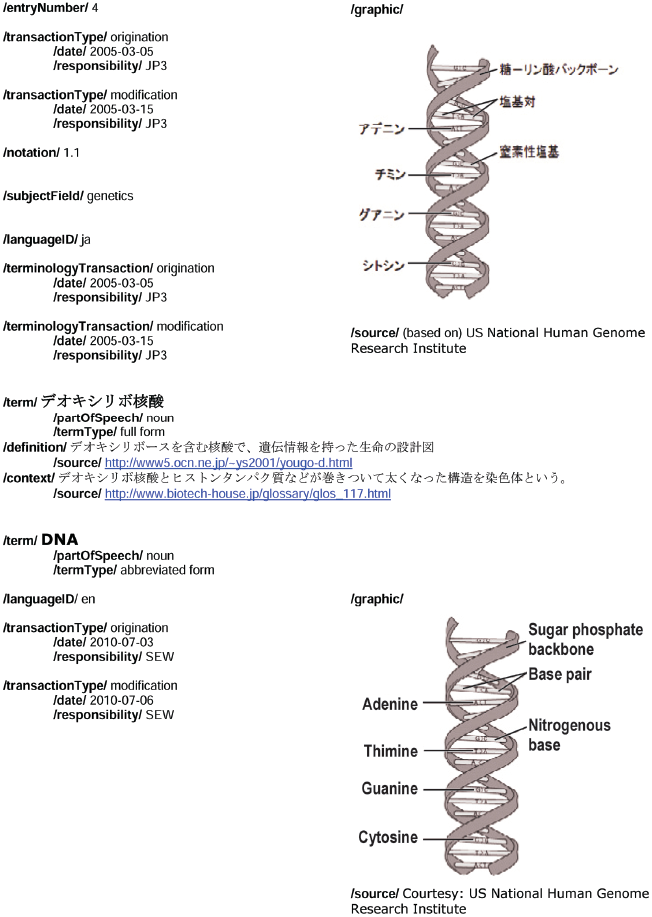
|

Приложение ДА
(справочное)
Сведения о соответствии ссылочных международных стандартов национальным стандартам
Таблица ДА.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование соответствующего национального стандарта |
ISO 704 | IDT | ГОСТ Р ИСО 704-2010 "Терминологическая работа. Принципы и методы" |
ISO 12620 | IDT | ГОСТ Р ИСО 12620-2012 "Терминология, другие языковые ресурсы и ресурсы содержания. Спецификация категорий данных и ведение реестра категорий данных для языковых ресурсов" |
ISO 16642 | - | * |
ISO 30042 | IDT | ГОСТ Р ИСО 30042-2016 "Системы управления терминологией, базами знаний и контентом. Обмен терминологическими базами [(TermBase eXchange (ТВХ)]" |
* Соответствующий национальный стандарт отсутствует. До его принятия рекомендуется использовать перевод на русский язык данного международного стандарта. Примечание - В настоящей таблице использовано следующее условное обозначение степени соответствия стандартов: - IDT - идентичные стандарты. | ||
Библиография
[1] | ISO 1087-1:2000*, Terminology work - Vocabulary - Part 1: Theory and application. (Терминологическая работа. Словарь. Часть 1. Теория и применение) |
________________ | |
[2] | ISO 1087-2:2000**, Terminology work - Vocabulary - Part 2: Computer applications. (Терминологическая работа. Словарь. Часть 2. Применение вычислительной техники) |
________________ ** Отменен. | |
[3] | ISO 10241-1, Terminological entries in standards. Part 1: General requirements and examples of presentation. (Терминологические статьи в стандартах. Часть 1. Общие требования и примеры представления) |
[4] | ISO/IEC 10646:2003***, Information technology - Universal Coded Character Set (UCS). (Информационные технологии. Универсальный многооктетный набор кодированных символов (UCS)) |
________________ *** Заменен на ISO/IEC 10646:2017.
| |
[5] | ISO/IEC 11179-3:2003 |
________________
| |
[6] | ISO 12616:2002, Translation-oriented terminography. (Терминография, ориентированная на перевод) |
[7] | ISO 24613:2008, Language resource management - Lexical markup framework (LMF). (Управление лингвистическими ресурсами. Схема лексической разметки) |
[8] | ISO/IEC 11179-1:2004 |
________________
| |
[9] | Geneter, доступен на: //www.geneter.org/ |
[10] | The Unicode Standard, available at: //www.unicode.org/versions/Unicode5.0.0/ |
УДК 658:562.014:006.354 | ОКС 01.020 |
35.240.60 | |
Ключевые слова: терминологический ресурс, системы управления терминологией, терминологическая база, терминологический вход, эквивалентное понятие, двойной вход | |
Электронный текст документа
и сверен по:
, 2020

{kind=link}