ГОСТ Р ИCO/HL7 27951-2016
Группа П85
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Информатизация здоровья
ОБЩИЕ ТЕРМИНОЛОГИЧЕСКИЕ СЛУЖБЫ
Выпуск 1
Health informatics. Common terminology services. Release 1
ОКС 35.240.80
ОКСТУ 4002
Дата введения 2018-01-01
Предисловие
Предисловие
1 ПОДГОТОВЛЕН Федеральным государственным бюджетным учреждением "Центральный научно-исследовательский институт организации и информатизации здравоохранения Министерства здравоохранения Российской Федерации" (ЦНИИОИЗ Минздрава) на основе собственного перевода на русский язык англоязычной версии международного стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 468 "Информатизация здоровья" при ЦНИИОИЗ Минздрава - постоянным представителем ISO/TC 215
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 30 ноября 2016 г. N 1894-ст
4 Настоящий стандарт идентичен международному стандарту ISO/HL7 27951:2009* "Информатизация здоровья. Общие терминологические службы. Выпуск 1" (ISO/HL7 27951:2009 "Health informatics - Common terminology services, release 1", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым здесь и далее по тексту, можно получить, перейдя по ссылке на сайт . - .
Наименование настоящего стандарта изменено относительно наименования указанного международного стандарта для приведения в соответствие с ГОСТ Р 1.5 (подраздел 3.6)
5 ВВЕДЕН ВПЕРВЫЕ
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ежемесячном информационном указателе "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
1 Область применения. Общие терминологические службы (ОТС)
Содержание настоящего стандарта должно стать основной международной платформы* разработки интерфейса прикладных программ API (Application Programming Interface), который может использоваться программным обеспечением обработки сообщений для доступа к терминологическому содержанию. Сам по себе такой интерфейс не обеспечит полную терминологическую службу. Стандарты Health Level Seven (HL7) Версии 3 (использующие язык XML) основаны на эталонной информационной модели RIM (Reference Information Model), обладающей общей и гибкой структурой. Представление информации в этой модели опирается на доступность терминологических ресурсов, которые могут использоваться для наполнения свойств модели требуемым семантическим содержанием. По возможности стандарт HL7 Версии 3 использует существующие терминологические ресурсы, а не создает новые внутри себя.
_______________
* Текст документа соответствует оригиналу. - .
Поскольку внешние терминологические ресурсы могут значительно различаться как по содержанию, так и по структуре, ОТС идентифицируют общие функциональные характеристики, которые может предоставлять внешняя терминология. Например, терминологическая служба, совместимая со стандартом HL7, должна быть способной определить, является ли данный код понятия действительным в конкретном ресурсе. Вместо описания таблицы, строки которой содержат идентификаторы ресурса и коды понятий, спецификация ОТС описывает вызов интерфейса прикладных программ API (Application Programming Interface), который может на входе получить идентификатор ресурса и код понятия, а на выходе возвратить значение true (истинный) или false (ложный). Каждый разработчик терминологии свободен реализовать этот вызов API по собственному усмотрению.
Спецификация ОТС не рассчитана на нижеследующее:
- текущая версия не предназначена к использованию в качестве полной терминологической службы. Ее область применения ограничена функциональностью, необходимой для конструирования, реализации и развертывания пакетов программ, соответствующих стандарту HL7 Версии 3. В той же степени, как язык XML связан с языком SGML, ОТС HL7 рассчитаны на представление достаточного подмножества функций, которые могут быть предоставлены более сложными API, например, теми, что соответствуют спецификации TQS организации OMG;
- она не предназначена для использования в качестве языка запросов общего назначения. В ней определены только конкретные службы, необходимые для реализации стандарта HL7;
- в ней не задан способ реализации службы. В ней намеренно опущены требования к информированию о службе и к ее обнаружению, к установке соединений и к управлению ими, а также требования к доставке и маршрутизации сообщений. Предполагается, что реализация ОТС будет использовать нижележащую архитектуру, наиболее подходящую для конкретных условий реализации.
Разработка спецификации ОТС HL7 основана на следующих общих принципах:
1) должно быть нетрудно написать программу, использующую ОТС HL7;
2) ОТС HL7 предназначены для описания только базовых требований;
3) конструкция ОТС HL7 должна быть формальной и точной;
4) первичная технология реализации ОТС HL7 должна быть основана на языке XML;
5) ОТС HL7 должны быть совместимы с номенклатурой, моделью и подходом, представленными в документе HL7 Vocabulary, модели RIM стандарта HL7 Версии 3 и производными структурами;
6) по возможности ОТС HL7 должны оставаться согласованным подмножеством Служб терминологических запросов TQS (Terminology Query Services) организации Object Management Group (OMG), пока это не противоречит другим принципам конструирования ОТС HL7. Если будет обнаружено, что модель TQS противоречит принципам конструирования ОТС HL7 или является неполной либо некорректной, то должны быть предприняты все необходимые шаги, чтобы уведомить об этом соответствующую рабочую группу по пересмотру;
7) ОТС HL7 должны ограничиться теми предположения о форме и структуре терминологии, которая необходима для поддержки реализации стандартов HL7.
Хотя общераспространенного стандарта терминологических служб не существует, на эту тему есть несколько источников материала:
- спецификация OMG Terminology Query Services (TQS).
Спецификация TQS описывает полную терминологическую службу, но она широко не реализована и ее поддержка со стороны производителей программного обеспечения минимальна. Некоторые считают, что она слишком "тяжеловесна" и при этом опирается на конкретное техническое решение (CORBA). Поскольку стандарт HL7 не предполагает опираться на стандарт TQS, то необходим более общий подход к терминологическим службам, по крайней мере в тех областях, где стандарт HL7 зависит от терминологии;
- DAML + OIL и язык Web Ontology Language (OWL).
Эти документы не являются спецификациями терминологического сервера, но при этом они содержат элементы представления онтологических аспектов, релевантные некоторым масштабным терминологиям, например, SNOMED Clinical Terms, NHS Clinical Terms Version 3 и GALEN. Однако это предложение, основанное на веб-технологиях, также является тяжеловесным и вряд ли приведет к ранней широко распространенной реализации;
- спецификации API, рассчитанные на конкретные терминологии.
Примером может служить спецификация API "Read Code - Version 3", разработанная по проекту клинической терминологии NHS Clinical Terms в 1996 году и пересмотренная в 1998 году. На основе похожих принципов ведется работа по созданию API SNOMED СТ. Неофициально признается, что этот конкретный API сольется с ОТС или будет использовать подходящие элементы ОТС там, где это целесообразно. Реализация этого API на основе технологии СОМ обеспечивается по меньшей мере одной свободно распространяемой машиной кодирования (CLUE). Спецификации этого типа идентифицируют многие общие функции, необходимые для доступа к терминологии. Однако они неизбежно специфичны для нужд конкретной терминологии. Явная поддержка единственной определенной модели терминологии позволяет обеспечить ее эффективную реализацию в операционной среде в ущерб гибкости, требуемой для доступа к другим терминологиям;
- интерфейсы к системам реляционных баз данных, включая SQL и ODBC.
Для "элементарных" списков кодов простой запрос на языке SQL может оказаться наиболее эффективным способом извлечения кода. Однако многие схемы кодирования в дополнение к парам "значение кода" - "описание значения" имеют другие релевантные свойства, которые могут быть доступными только с помощью вторичной службы. Это не препятствует применению языка SQL, но требует описания общей модели, в соответствии с которой могут исполняться запросы, и эффективных средств, возвращающих требуемые свойства. Такие дополнительные свойства присущи как всей схеме, так и отдельным элементам терминологии;
- язык терминологических запросов TQL (Terminology Query Language).
Язык TQL, ранее основанный на синтаксисе, подобном языку SQL, в настоящее время реализуется на основе унифицированных идентификаторов ресурсов URI, специфичных для терминологических серверов, разработанных Майклом Хогартом (Michael Hogarth) и его коллегами в Калифорнийском университете. В языке TQL предусмотрен богатый механизм, предназначенный для оперирования общими свойствами и отношениями в терминологических моделях. Работающая реализация языка TQL на платформе Java может быть бесплатно загружена из сети Интернет.
2 Нормативные ссылки
В настоящем стандарте использованы ссылки на следующие документы* (для датированных ссылок следует использовать только указанное издание, для недатированных - последнее издание указанного документа, включая все поправки):
_______________
* Таблицу соответствия национальных стандартов международным см. по ссылке. - .
ISO/HL7 21731:2006, Health informatics - HL7 Version 3 - Reference information model - release 1 (Информатизация здоровья. HL7, Версия 3. Эталонная информационная модель. Выпуск 1)![]()
_______________
![]() В настоящее время действует версия ISO/HL7 21731:2014.
В настоящее время действует версия ISO/HL7 21731:2014.
HL7 2008, Datatype Specification. Abstract Data Types (Спецификация типов данных. Абстрактные типы данных)
3 Термины и определения
Следует обратить внимание, что существует большое число терминов, используемых для описания базовых понятий в здравоохранении, приведенных в публикациях организаций ИСО, CEN, HL7 и других международных и национальных организаций для разных целей. Термины и определения, приведенные в настоящем стандарте, не претендуют на замену ранее данных. Они предназначены для совместного использования с национальными или региональными требованиями, и в случае конфликта национальные/региональные требования должны иметь приоритет. Для целей настоящего стандарта к терминологическим ресурсам, используемым в среде электронной передачи сообщений, применяются приведенные ниже термины и определения. Их выбор обусловлен задачей доступа к терминологическим ресурсам в среде электронной передачи сообщений.
3.1 интерфейс прикладных программ (application programming interface, API): Совокупность функций, процедур, методов или классов, предоставляемых операционной системой, библиотекой или службой для использования во внешних программных продуктах.
3.2 система кодирования (code system): В целях настоящего стандарта под "системой кодирования" понимается система кодов, обозначений, свойств и отношений. К другим общим именам этой сущности относятся "словарь", "терминология", "схема кодирования", "схема классификации" и "онтология".
3.3 ограничение (constraint): Логическое выражение, накладывающее ограничение на значения объектов, принадлежащих некоторому множеству, и тем самым задающее логическое подмножество этого множества.
3.4
язык описания интерфейсов (interface description language, IDL): Язык описания интерфейсов используется для описания интерфейса компонента программного обеспечения. Языки IDL описывают интерфейсы способом, не зависящим от языка программирования, чтобы компоненты программного обеспечения, написанные на разных языках, могли обмениваться данными. |
3.5 идентификатор объекта (object identifier): Число, постоянное, присвоенное объекту и используемое для его уникальной идентификации в коллекции объектов.
3.6 эталонная информационная модель (reference information model, RIM): Информационная модель, разработанная комитетом HL7, используемая для построения всех других информационных моделей, например, уточненных информационных моделей сообщений RMIM и самих сообщений.
3.7 уточненная информационная модель сообщений (refined message information model, RMIM): Структура информации, используемая в стандарте передачи сообщений HL7 Версии 3, описывающая требования к комплексу сообщений.
3.8 стандарт (standard): Техническая спецификация требований к процессам деятельности, реализованная в конкурентоспособной промышленной продукции и в необходимых случаях признаваемая официальными органами стандартизации, например, ИСО.
3.9
терминология (terminology): Любое организованное множество кодов, включая сущности, обычно называемые "наборами кодов", "онтологиями", "словарями", "системами классификации" и т.д. |
3.10
язык описания веб-служб (Web services description language, WSDL): WSDL представляет собой формат описания сетевых служб на языке XML, представляющего эти службы как совокупность конечных точек, оперирующих сообщениями, содержащими информацию, ориентированную на документы или процедуры. Операциям и сообщениям дается абстрактное описание; для определения конечной точки они привязываются к конкретному сетевому протоколу и формату сообщений. Конкретные логически связанные конечные точки объединяются в абстрактные конечные точки (службы). Для целей описания конечных точек и их сообщений независимо от форматов сообщений или сетевых протоколов, используемых для обмена данными, язык WSDL является расширяемым. При этом описание того, как использовать конкретную конечную точку в сочетании с SOAP 1.1, HTTP GET/POST и MIME, задается исключительно в привязках. |
4 Условные обозначения и сокращения
В настоящем стандарте используются следующие сокращения:
API | - интерфейс прикладных программ (Application Programming Interface); |
ОТС | - общая терминологическая служба (Common Terminology Service, CTS); |
CEN | - Европейский комитет по стандартизации, федерация из 28 национальных органов стандартизации, которые также входят в ИСО ( |
EU | - Европейский союз (European Union); |
HL7 | - Health Level Seven Inc.; |
HMD | - иерархическое описание сообщения (Hierarchical Message Description); |
IDL | - язык описания интерфейсов (Interface Description Language); |
ITS | - спецификация реализуемой технологии (Implementable Technology Specification); |
ICH | - Международная конференция по гармонизации технических требований к регистрации лекарственных препаратов для человека (The International Conference on Harmonisation of Technical Requirements for Registration of Pharmaceuticals for Human Use); |
ИСО | - International Organization for Standardization, ISO; |
ОИДо | - объектный идентификатор (Object IDentifier); |
RIM | - эталонная информационная модель (Reference Information Model); |
RMIM | - уточненная информационная модель сообщений (Refined Message Information Model); |
SDO | - Организация по разработке стандартов (Standards Development Organization); |
SGML | - стандартный обобщенный язык разметки (standardized generalized markup language). Стандарт ИСО по платформенно-независимому описанию структурированной информации; |
SNOMED | - систематизированная номенклатура терминов медицины и ветеринарии (The Systematized Nomenclature of Human and Veterinary Medicine); |
SNOMED-CT | - систематизированная номенклатура терминов клинической медицины (Systematized Nomenclature of Medicine-Clinical Terms Medicine); |
UML | - унифицированный язык моделирования (Unified Modelling Language); |
W3C | - Консорциум всемирной паутины (World Wide Web Consortium); |
XML | - расширяемый язык разметки (eXtensible Markup Language). |
5 Модули ОТС
5.1 API сообщений и словаря
Между целевыми словарями и программами обработки сообщений, соответствующих стандарту HL7 Версии 3, предусмотрены два различных уровня, показанных на рисунке 1. Верхний уровень, API сообщений, взаимодействует с программами обработки сообщений в терминах словарных доменов, контекстов, наборов значений, кодированных атрибутов и других артефактов модели сообщений HL7. Нижний уровень, API словаря, взаимодействует с программным обеспечением терминологических служб в терминах систем кодирования, кодов понятий, обозначений, отношений и других сущностей, специфичных для терминологий.
Рисунок 1 - API сообщений и словаря
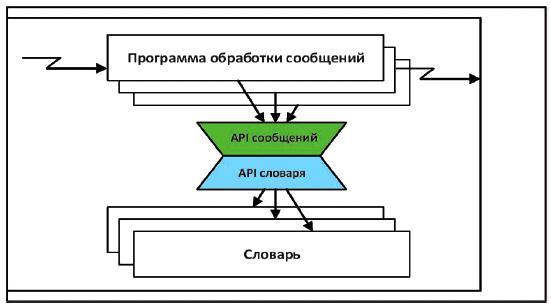
Рисунок 1 - API сообщений и словаря
API сообщений специфичен для HL7. Его основная цель - обеспечить широкому спектру программ обработки сообщений удобные и воспроизводимые возможности создания, проверки и преобразования типов данных, произведенных от типа CD (coded data - кодированные данные).
API словаря рассчитан на общее применение![]() . Он позволяет прикладным программам осуществлять запросы к различным терминологиям
. Он позволяет прикладным программам осуществлять запросы к различным терминологиям![]() хорошо определенным, согласованным способом. API сообщений включает в себя применение API словаря. На рисунке 2 показан пример взаимодействия программы обработки сообщений со словарем. В этом примере программа обработки сообщений обращается к службе времени исполнения уровня сообщений для заполнения детальных сведений об атрибуте, имеющем тип данных, произведенный от типа CD. Эта служба, в свою очередь, выполняет несколько обращений к службе уровня словаря для получения обозначений кода понятия, имен системы кодирования, версий ее выпусков и т.д.
хорошо определенным, согласованным способом. API сообщений включает в себя применение API словаря. На рисунке 2 показан пример взаимодействия программы обработки сообщений со словарем. В этом примере программа обработки сообщений обращается к службе времени исполнения уровня сообщений для заполнения детальных сведений об атрибуте, имеющем тип данных, произведенный от типа CD. Эта служба, в свою очередь, выполняет несколько обращений к службе уровня словаря для получения обозначений кода понятия, имен системы кодирования, версий ее выпусков и т.д.
_______________
![]() Хотя API словаря и рассчитан на общее применение, он представляет некоторое подмножество тех возможностей, которые должен обеспечивать общий словарный API. Кроме того, значительная часть номенклатуры, используемой в API словаря ОТС, так или иначе связана со стандартами HL7, и для более общего применения может потребоваться преобразование этого API.
Хотя API словаря и рассчитан на общее применение, он представляет некоторое подмножество тех возможностей, которые должен обеспечивать общий словарный API. Кроме того, значительная часть номенклатуры, используемой в API словаря ОТС, так или иначе связана со стандартами HL7, и для более общего применения может потребоваться преобразование этого API.
![]() В контексте данного документа слово "терминология" означает описание любого организованного множества кодов, включая сущности, обычно называемые "наборами кодов", "онтологиями", "словарями", "системами классификации" и т.д.
В контексте данного документа слово "терминология" означает описание любого организованного множества кодов, включая сущности, обычно называемые "наборами кодов", "онтологиями", "словарями", "системами классификации" и т.д.
Рисунок 2 - Пример взаимодействия с API сообщений и словаря
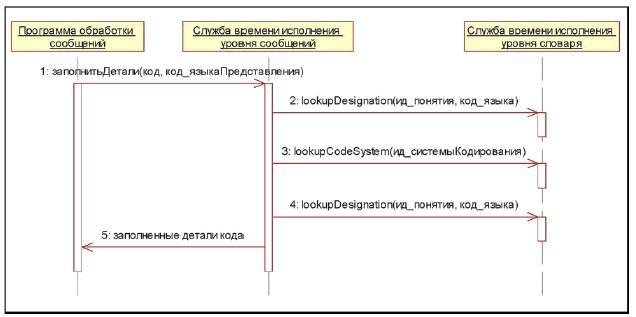
Рисунок 2 - Пример взаимодействия с API сообщений и словаря
5.2 Функции времени исполнения и обозревания
5.2.1 Общие классы пользователей (действующих лиц) ОТС HL7
Классы действующих лиц, предполагаемых пользователями API ОТС HL7, включают в себя:
Программное обеспечение создания сообщений - программное обеспечение, создающее сообщения, соответствующие стандарту HL7. С точки зрения применения словарей процесс создания сообщений включает в себя преобразование внутренних структур сообщений и данных в синтаксис и семантику сообщений стандарта HL7 Версии 3.
Программное обеспечение обработки сообщений - программное обеспечение, получающее и декодирующее сообщения стандарта HL7 Версии 3 и действующее в соответствии с содержанием сообщений. Процесс обработки сообщений включает в себя шаги проверки и преобразования сообщений, а также принятие решений о дальнейших действиях.
Разработчики модели RIM - сочетание людей и инструментальных средств, создающих содержание и определения сообщений стандарта HL7.
Разработчики программного обеспечения - люди, создающие программное обеспечение, создающее, проверяющее и обрабатывающее сообщения стандарта HL7 Версии 3.
Трансляторы словарей - сочетание людей и инструментальных средств, преобразующих абстрактную спецификацию стандарта HL7 Версии 3 в структуры и термины, используемые конкретными приложениями обработки данных.
5.2.2 Раздельные профили требований
Первые два класса действующих лиц - создатели и обработчики сообщений - имеют особый профиль требований, включающий в себя следующие три группы:
1) требования к производительности. Высокая пропускная способность и масштабируемость являются крайне важными при создании и обработке сообщений. Процессы преобразования словарей и моделирования гораздо менее чувствительны к вариабельным и потенциально субоптимальным временам ответа;
2) требования к надежности. Программное обеспечение, создающее и обрабатывающее сообщения, должно быть очень надежным, в то время как среда обработки словарей и среда моделирования могут допускать некоторую степень снижения надежности и случайных сбоев;
3) требования к функциональности. После согласования функциональные требования к программному обеспечению создания и обработки сообщений остаются фиксированными. Любые дополнительные возможности сверх этих требований использоваться не будут. В то же время в процессах разработки словарей и моделирования будут постоянно возникать различные новые запросы к извлечению и просмотру информации, для удовлетворения которых время от времени могут создаваться любые (полезные) функциональные возможности.
В дальнейшем изложении профиль требований к созданию и обработке сообщений будет именоваться профилем времени исполнения, а профиль разработки словаря и моделирования - профилем обозревателя.
5.2.3 Трансляция
Необходимо выделить еще одну дополнительную функциональную область - трансляцию, то есть преобразование кодов понятий из одной системы кодирования в другую. Возможность трансляции наборов кодов для различных областей применения является существенной частью API сообщений. Она определена как отдельный интерфейс на уровне словаря, поскольку она не специфична для конкретного словаря. Службы трансляции потенциально могут разрабатываться независимо от одной или нескольких терминологий, охваченных процессом трансляции.
5.2.4 Отдельные компоненты спецификации
При сочетании уровней сообщения и словаря с двумя профилями требований образуются пять отдельных модулей, указанных в таблице 1.
Таблица 1 - Компоненты спецификации
Платформа времени исполнения | Обозреватель | |
API сообщений | Платформа сообщений | Обозреватель сообщений |
API словаря | Платформа словаря | Обозреватель словаря |
Преобразование | Преобразование словаря |
Стиль изложения, принятый в настоящем документе, позволяет независимую реализацию требований каждой из этих областей, сохраняющую интероперабельность. Некоторые разработчики терминологических систем предпочтут сконцентрироваться на реализации API словаря, другим может понадобиться только реализация платформ времени исполнения. Теоретически API сообщений достаточно реализовать только один раз, поскольку структура сообщений HL7, положенных в основу этого API, опубликована и доступна каждому специалисту. Однако на практике для достижения желаемой производительности может понадобиться более тесная привязка платформы сообщений к платформе словаря.
6 Краткий обзор функций модулей
Следующие подразделы содержат краткий обзор функций каждого из пяти модулей, указанных в таблице 1. В целях большей наглядности некоторые параметры и вспомогательные функции опущены. Здесь даны только обзорные сведения, а в следующих разделах настоящего документа все функции, перечисленные в таблицах 2-6, будут описаны гораздо детальнее.
6.1 Функции платформы времени исполнения, предназначенной для уровня сообщений
Модуль платформы времени исполнения, предназначенной для уровня сообщений, предоставляет службы, используемые программным обеспечением создания, обработки и преобразования сообщений. Функции этих служб перечислены в таблице 2.
Таблица 2 - Функции платформы времени исполнения, предназначенной для уровня сообщений
Функция | Входные параметры | Выходные данные | Описание |
getServiceName | Имя службы | Возвращает имя, присвоенное службе ее поставщиком | |
getServiceVersion | Идентификатор версии | Возвращает текущую версию программного обеспечения службы | |
getServiceDescription | Описание службы | Возвращает описание функции службы, авторов, сведений об авторских правах и т.д. | |
getHL7ReleaseVersion | Идентификатор версии | Возвращает идентификатор версии выпуска стандарта HL7, которая в настоящее время поддерживается службой | |
getCTSVersion | Старший и младший номер версии | Возвращает номер версии ОТС, реализованной службой | |
getSupportedMatch Algorithms | Список алгоритмов совпадения | Возвращает список алгоритмов совпадения строк, реализованных данной службой | |
getSupportedVocabulary Domains | Поисковый образец и алгоритм совпадения, ограничения времени и размера | Список имен словарных доменов | Возвращает список словарных доменов, распознаваемых данной службой, имена которых совпадают с переданным образцом |
validateCode | Имя словарного домена, проверяемый код, прикладной контекст (область применения), признак, указывающий, должны ли в проверке участвовать только активные понятия, а также признак, указывающий, надо ли определять ошибки и предупреждения или только ошибки | Список ошибок и предупреждений | Сравнивает значение кодированного атрибута с заданным словарным доменом и его контекстом |
validateTranslation | Имя словарного домена, кодированный атрибут, содержащий одно или более проверяемых преобразований, прикладной контекст (область применения), признак, указывающий, должны ли в проверке участвовать только активные понятия, а также признак, указывающий, надо ли определять ошибки и предупреждения или только ошибки | Список ошибок и предупреждений | Сравнивает компоненты преобразования, если таковые присутствуют в переданном значении типа CD, с заданным словарным доменом и его контекстом |
translateCode | Имя словарного домена, преобразуемый кодированный атрибут, целевая система кодирования и целевой прикладной контекст (область применения) | Преобразование кодированного атрибута | Преобразование значения заданного кодированного атрибута в форму, использующую целевую систему кодирования или ту систему кодирования, которая является наиболее подходящей для заданного контекста |
filllnDetails | Кодированный атрибут и код целевого языка | Значение кодированного атрибута с дополнительными деталями | Заполняет необязательные компоненты значения кодированного атрибута, например, изображаемое имя понятия, имя и версию системы кодирования |
subsumes | Родительский кодированный атрибут, дочерний кодированный атрибут | True/False | Определяет, действительно ли значение переданного родительского кодированного атрибута охватывает (или включает в себя) переданное значение дочернего атрибута |
areEquivalent | Первый кодированный атрибут, второй кодированный атрибут | True/False | Определяет, являются ли значения двух кодированных атрибутов эквивалентными |
lookupValueSet Expansion | Имя словарного домена, прикладной контекст (область применения), язык текста расширения, признак, указывающий, выполнить ли полное расширение или только расширение на один уровень, ограничения времени и размера | Иерархическое расширение набора значений, ассоциированного с доменом в переданном контексте | Возвращает иерархический список понятий, выбираемых для заданного словарного домена и контекста |
expandValueSet ExpansionContext | Непрозрачный контекст расширения, возвращенный ранее вызванными функциями lookupValueSetExpansion или expand ValueSetExpansion Context | Дальнейшее иерархическое расширение набора значений, ассоциированного с доменом в переданном контексте | Возвращает дальнейшее расширение вложенного содержания набора значений |
6.2 Функции платформы времени исполнения, предназначенной для уровня словаря
Функции, перечисленные в таблице 3, используются службой времени исполнения на уровне сообщений и службой обозревателя уровня сообщений, а также службой обозревателя уровня словаря. Они используются как самостоятельные.
Таблица 3 - Функции платформы времени исполнения, предназначенной для уровня словаря
Функция | Входные параметры | Выходные данные | Описание |
getServiceName | Имя службы | Возвращает имя, присвоенное службе ее поставщиком | |
getServiceVersion | Идентификатор версии | Возвращает текущую версию программного обеспечения службы | |
getServiceDescription | Описание службы | Возвращает описание функции службы, авторов, сведений об авторских правах и т.д. | |
getCTSVersion | Старший и младший номер версии | Возвращает номер версии ОТС, реализованной службой | |
getSupportedCode Systems | Ограничения времени и размера | Список систем кодирований и их версий, поддерживаемых данной реализацией службы | Возвращает идентификаторы, имена и идентификаторы выпусков всех систем кодирования, которые поддерживаются данной службой |
lookupCodeSystemlnfo | Имя или идентификатор системы кодирования | Сведения о системе кодирования, включая имя, идентификатор, версию, поддерживаемые языки, поддерживаемые отношения, поддерживаемые свойства и т.д. | Возвращает детальную информацию об указанной системе кодирования |
isConceptldValid | Идентификатор системы кодирования, код понятия и признак, указывающий, считаются ли неактивные понятия допустимыми | True/False | Определяет, является ли код понятия допустимым для текущей версии заданной системы кодирования |
lookupDesignation | Идентификатор системы кодирования, код понятия и код целевого языка | Текст обозначения понятия | Возвращает предпочтительное обозначение кода понятия на указанном языке |
areCodesRelated | Идентификатор системы кодирования, код исходного понятия, код целевого понятия, код отношения, квалификаторы отношения и признак, указывающий, использовать ли только непосредственно связанные коды или транзитивное замыкание отношения | True/False | Определяет, существует ли поименованное отношение между понятиями, заданными исходным и целевым кодом |
6.3 Функции отображения кодов
Функции отображения кодов перечислены в таблице 4.
Таблица 4 - Функции отображения кодов
Функция | Входные параметры | Выходные данные | Описание |
getServiceName | Имя службы | Возвращает имя, присвоенное службе ее поставщиком | |
getServiceVersion | Идентификатор версии | Возвращает текущую версию программного обеспечения службы | |
getServiceDescription | Описание службы | Возвращает описание функции службы, авторов, сведений об авторских правах и т.д. | |
getCTSVersion | Старший и младший номер версии | Возвращает номер версии ОТС, реализованной данной службой | |
getSupportedMaps | Список именованных наборов, строки которого состоят из идентификатора, имени и версии исходной системы кодирования, идентификатора, имени и версии целевой системы кодирования, а также описания отображения исходной системы на целевую | Возвращает список отображений, обеспечиваемых данной службой | |
mapConceptCode | Идентификатор исходной системы кодирования, код понятия в этой системе, идентификатор целевой системы кодирования и имя ресурса отображения | Соответствующий код понятия в целевой системе кодирования и признак качества отображения | Возвращает представление в целевой системе кодирования кода понятия, взятого из исходной системы кодирования, полученное с помощью поименованного ресурса отображения |
6.4 Функции обозревателя уровня сообщений
Функции обозревателя уровня сообщений перечислены в таблице 5.
Таблица 5 - Функции обозревателя уровня сообщений
Функция | Входные параметры | Выходные данные | Описание |
getServiceName | Имя службы | Возвращает имя, присвоенное службе ее поставщиком | |
getServiceVersion | Идентификатор версии | Возвращает текущую версию программного обеспечения службы | |
getServiceDescription | Описание службы | Возвращает описание функции службы, авторов, сведений об авторских правах и т.д. | |
getHL7ReleaseVersion | Идентификатор версии | Возвращает идентификатор версии выпуска стандарта HL7, которая в настоящее время поддерживается службой | |
getCTSVersion | Старший и младший номер версии | Возвращает номер версии ОТС, реализованной службой | |
getSupportedMatch Algorithms | Список алгоритмов совпадения | Возвращает список алгоритмов совпадения строк, реализованных данной службой | |
lookupVocabularyDomain | Имя словарного домена | Имя домена, описание, список доменов, ограниченных данным доменом, список атрибутов модели RIM, использующих данный домен, и список наборов значений, представляющих данный домен | Извлечение всей информации, известной о заданном словарном домене |
lookupValueSet | Идентификатор или имя набора значений | Детальные сведения о наборе значений, включая имя, идентификатор, описание, список наборов значений, использованных для составления данного набора, наборы значений, в определении которых участвует данный набор, список кодов понятий, на которые ссылается данный набор, и т.д. | Извлечение детальной информации о наборе значений (включая словарные домены, конструкторы и т.д.) |
lookupCodeSystem | Идентификатор или имя системы кодирования | Имя, идентификатор, авторские права, выпуск и информация о регистрации | Извлечение детальной информации о системе кодирования |
lookupValueSet ForDomain | Имя словарного домена и прикладной контекст (область применения) | Имя и идентификатор набора значений, использованного для данного словарного домена | Возвращает идентификатор набора значений, который мог бы использоваться в заданном контексте (если таковой существует) |
lookupVocabularyDomain | Имя словарного домена | Имя домена, описание, список доменов, ограниченных данным доменом, список атрибутов модели RIM, использующих данный домен, и список наборов значений, представляющих данный домен | Извлечение всей информации, известной о заданном словарном домене |
lookupValueSet | Идентификатор или имя набора значений | Детальные сведения о наборе значений, включая имя, идентификатор, описание, список наборов значений, использованных для составления данного набора, наборы значений, в определении которых участвует данный набор, список кодов понятий, на которые ссылается данный набор, и т.д. | Извлечение детальной информации о наборе значений (включая словарные домены, конструкторы и т.д.) |
lookupCodeSystem | Идентификатор или имя системы кодирования | Имя, идентификатор, авторские права, выпуск и информация о регистрации | Извлечение детальной информации о системе кодирования |
lookupValueSetFor Domain | Имя словарного домена и прикладной контекст (область применения) | Имя и идентификатор набора значений, использованного для данного словарного домена | Возвращает идентификатор набора значений, который мог бы использоваться в заданном контексте (если таковой существует) |
isCodelnValueSet | Идентификатор или имя набора значений, идентификатор системы кодирования и код понятия, а также признак, включать ли такой "ведущий код" в состав набора значений | True/False | Определяет, является ли указанный код понятия допустимым для заданного набора значений |
6.5 Функции обозревателя уровня словаря
Функции обозревателя уровня словаря перечислены в таблице 6.
Таблица 6 - Функции обозревателя уровня сообщений
Функция | Входные параметры | Выходные данные | Описание |
getServiceName | Имя службы | Возвращает имя, присвоенное службе ее поставщиком | |
getServiceVersion | Идентификатор версии | Возвращает текущую версию программного обеспечения службы | |
getServiceDescription | Описание службы | Возвращает описание функции службы, авторов, сведений об авторских правах и т.д. | |
getCTSVersion | Старший и младший номер версии | Возвращает номер версии ОТС, реализованной службой | |
getSupportedMatch Algorithms | Список алгоритмов совпадения | Возвращает список алгоритмов совпадения строк, реализованных данной службой | |
getSupportedAttributes | Поисковый образец и алгоритм совпадения, ограничения времени и размера | Список атрибутов модели RIM, известных обозревателю | Возвращает список атрибутов модели RIM, известных обозревателю, чьи имена совпадают с заданным образцом |
getSupported CodeSystems | Поисковый образец и алгоритм совпадения, ограничения времени и размера | Список систем кодирования, известных обозревателю | Возвращает список систем кодирования, известных обозревателю, чьи имена совпадают с заданным образцом |
lookupConcept CodesByDesignation | Идентификатор системы кодирования, поисковый образец и алгоритм совпадения, код целевого языка, признак, указывающий, должны ли извлекаться неактивные понятия, ограничения времени и размера | Список идентификаторов систем кодирования и кодов понятий | Возвращает список кодов понятий, чьи обозначения совпадают с заданным образом на заданном языке, если таковые найдены |
lookupConcept CodesByProperty | Идентификатор системы кодирования, поисковый образец и алгоритм совпадения, код целевого языка, признак, указывающий, должны ли извлекаться неактивные понятия, необязательный список типов среды (mime) свойств, ограничения времени и размера | Список идентификаторов систем кодирования/кодов понятий | Возвращает список кодов понятий, чьи свойства соответствуют заданным критериям |
lookupComplete CodedConcept | Идентификатор системы кодирования и код понятия | Все, что известно о понятии (обозначения, свойства, отношения и т.д.) | Возвращает полное описание заданного кода понятия |
lookupDesignations | Идентификатор системы кодирования и код понятия, поисковый образец и алгоритм совпадения, целевой язык | Список обозначений | Возвращает все обозначения заданного кода понятия, соответствующие заданным критериям |
lookupProperties | Идентификатор системы кодирования и код понятия, поисковый образец и алгоритм совпадения, список кодов искомых свойств, список типов среды (mime), участвующих в поиске совпадений, код целевого языка | Список свойств понятия (код свойства, значение, язык, тип среды) | Возвращает свойства заданной системы кодирования/кода понятия, соответствующих заданным критериям |
lookupCodeExpansion | Идентификатор системы кодирования и код понятия, код отношения, признак направления отношения, код целевого языка, ограничения времени и размера | Иерархический список расширения кода | Рекурсивно перечисляет коды понятий, связанных отношением с данным понятием, включая предпочтительные обозначения кодов |
7 Модель API сообщений ОТС
7.1 Введение
В настоящем разделе описана модель, положенная в основу API сообщений ОТС. Она определяет отношения между кодированными атрибутами HL7 и словарем. Она основана на метамодели HL7_V3_Meta-Model Version 1.16 и, исключая цветовое кодирование, по возможности остается совместимой с ее нотацией и типами данных. В настоящем стандарте не представлена полная или глубокая модель всех логических сущностей, образующих систему кодирования![]() . Его основная цель - описать классы и отношения, имеющие прямое отношение к содержанию кодированных атрибутов HL7 с точки зрения метамодели.
. Его основная цель - описать классы и отношения, имеющие прямое отношение к содержанию кодированных атрибутов HL7 с точки зрения метамодели.
_______________
![]() В настоящем стандарте термин "система кодирования" означает систему кодов, описаний, обозначений, свойств и отношений. К другим общим именам этой сущности относятся "словарь", "терминология", "схема кодирования", "схема классификации" и "онтология".
В настоящем стандарте термин "система кодирования" означает систему кодов, описаний, обозначений, свойств и отношений. К другим общим именам этой сущности относятся "словарь", "терминология", "схема кодирования", "схема классификации" и "онтология".
Модель API словаря описывает модель ОТС с точки зрения словаря и предусматривает дополнительную информацию о кодах понятий, обозначениях, отношениях и т.д.
7.1.1 Нотация
На приведенных ниже диаграммах те классы, за чьи экземпляры полностью отвечают группы моделирования HL7, выделены зеленым цветом, а классы, представляющие содержание, контролируемые комитетом HL7 либо другим поставщиком терминологии, выделены бледно-желтым цветом. Авторы настоящего документа не обладают сколько-нибудь существенным контролем над содержанием или структурой этих существующих классов - они включены в модель исключительно для ссылок.
Обозначения, принятые в настоящей модели, используют полуформальную нотацию, основанную на содержании модели:
- имена классов выделены полужирным шрифтом (например, VocabularyDomain, ValueSet);
- имена атрибутов выделены курсивом (например, vocabularyDomain_name, valueSet_id);
- имена отношений подчеркнуты (например, экземпляр класса VocabularyDomain представлен нулем или более экземплярами классов VocabularyDomainValueSets).
При необходимости кратности отношений выражаются приведенными ниже формами или близкими к ним:
- 1..1 "экземпляр класса Class 1 должен иметь отношение ровно с одним экземпляром класса Class 2";
- 0..1 "экземпляр класса Class 1 может иметь отношение не более чем с одним экземпляром класса Class 2";
- 1..* "экземпляр класса Class 1 должен иметь отношение с одним или несколькими экземплярами класса Class 2";
- 1 ..* "экземпляр класса Class 1 может иметь отношение с нулем или несколькими экземплярами класса Class 2".
7.2 Словарный домен
Словарный домен служит связующим звеном между кодированным атрибутом HL7 и набором (наборами) допустимых кодов понятий этого атрибута. Словарный домен представляет абстрактное концептуальное пространство наподобие "страны мира", "пол лица, используемый для административных целей" и т. д.
На рисунке 3 показано отношение между словарными доменами и атрибутами HL7.
Рисунок 3 - Атрибуты модели RIM и словарные домены

Рисунок 3 - Атрибуты модели RIM и словарные домены
Экземпляр класса Attribute_domain_constraint (ограничение домена атрибута) должен ограничивать допустимые значения ровно одного экземпляра класса Attribute (атрибута модели RIM). Он ограничивает допустимые значения атрибута теми, что описаны ровно одним экземпляром класса VocabularyDomain (словарный домен). Экземпляр класса VocabularyDomain может описывать допустимые значения одного или нескольких экземпляров класса Attribute_domain_constraint (ограничение домена атрибута). Экземпляр класса DIM_attribute_row (строка атрибута модели DIM) должен быть основан ровно на одном экземпляре класса Attribute, взятом из модели HL7, и используется для указания на присутствие атрибута в специфичной информационной модели домена DIM (domain information model). Экземпляр класса DIM_attribute_row наследует все ограничения экземпляра класса Attribute, на котором он основан, и, в свою очередь, может быть ограничен нулем или более экземплярами класса DIM_attribute_domain_constraint (ограничение домена атрибута модели DIM).
Иерархическое описание сообщения HMD (hierarchical message description) полностью определяет структуру совокупности сообщений. Экземпляры класса HMD_attribute_row (строка атрибута в HMD) являются компонентами HMD, и каждый экземпляр класса HMD_attribute_row основан ровно на одном экземпляре класса DIM_attribute_row. Экземпляр класса HMD_attribute_row наследует все ограничения соответствующего экземпляра класса DIM_attribute_row и может быть далее ограничен не более чем одним экземпляром класса HMD_domain_constraint (ограничение домена HMD).
Каждый экземпляр класса VocabularyDomain имеет уникальное имя (атрибут vocabularvDomain_name), а также описание пространства понятий (атрибут description), которое он представляет. Экземпляры класса VocabularyDomain, которые описывают допустимые значения экземпляров класса DIM_attribute_domain_constraint или класса HMD_domain_constraint, ограничивают пространство понятий соответствующего экземпляра класса DIM_attribute_domain или класса Attribute_domain_constraint, на котором основан домен.
Пример, приведенный в таблице 7, показывает, каким образом словарные домены могут быть ограничены в зависимости от атрибута, строки атрибута модели DIM или строки иерархического описания сообщения HMD.
Таблица 7 - Ограничения словарных доменов
Атрибут | Словарный домен | Описание | Ограничиваемый домен |
sourceCountry | Country | Страна мира | - |
sourceCountry(DIM) | HL7MemberCountry | Страна - официальный член комитета HL7 | Country |
sourceCountry(HMD) | EUHL7MemberCountry | Европейская страна - официальный член комитета HL7 | HL7MemberCountry |
7.2.1 Дополнительные ограничения
Примечание - В этом контексте ограничение относится к самой модели, а не к доменам атрибутов.
1. Экземпляр класса Attribute должен быть ограничен ровно одним экземпляром класса Attribute_domain_constraint в том и только том случае, если атрибут имеет кодированный тип данных.
2. Любой экземпляр класса VocabularyDomain, описывающий допустимые значения экземпляра класса DIM_attribute_domain_constraint, должен быть основан на экземпляре класса VocabularyDomain, соответствующем экземпляру класса Attribute.
3. Любой экземпляр класса VocabularyDomain, описывающий допустимые значения экземпляра класса RIM_attribute_domain_constraint, должен быть основан на экземпляре класса VocabularyDomain, соответствующем экземпляру класса DIM_attribute_row, если таковой существует, либо экземпляру класса Attribute.
7.3 Набор значений
Словарный домен описывает "понятийное пространство", из которого могут быть взяты значения атрибута. Но прежде чем атрибут может быть использован в сообщении, необходимо определить фактический список кодов понятий. Список допустимых кодов понятий называется набором значений. Структура набора значений и его ассоциации показаны на рисунке 4.
Экземпляр класса VocabularyDomain может быть представлен нулем или несколькими экземплярами класса ValueSet (набор значений). Хотя абстрактные атрибуты моделей RIM и DIM не обязаны быть представлены какими-либо экземплярами класса ValueSet, экземпляр класса VocabularyDomain, описывающий допустимые значения кодированных экземпляров класса Attribute, используемых в фактических сообщениях, должен быть представлен не менее чем одним экземпляром класса Value_set.
Рисунок 4 - Наборы значений
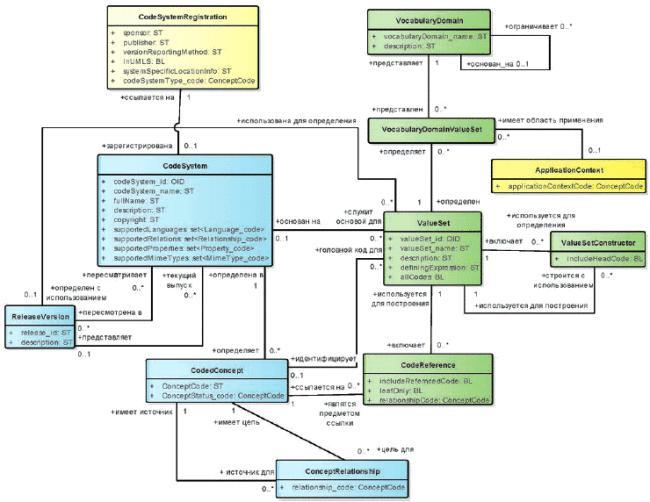
Рисунок 4 - Наборы значений
7.3.1 Связи между словарными доменами и наборами значений
Экземпляр класса VocabularyDomainValueSet (набор значений в словарном домене) представляет ассоциацию ровно между одним экземпляром класса VocabularyDomain и одним экземпляром класса ValueSet. Каждая ассоциация между экземпляром класса VocabularyDomain и экземпляром класса ValueSet может применяться в нуле или более экземпляров класса ApplicationContext (контекст применения). Экземпляр класса ApplicationContext именует конкретную геополитическую единицу (например, Европейский союз, Канада) и/или отрасль (например, ветеринарную медицину, общественное здоровье) и т.д. и может служить областью применения для нуля или более ассоциаций, представленных экземплярами класса VocabularyDomainValueSet.
7.3.2 Определение наборов данных
Экземпляр класса ValueSet может включать в себя список, состоящий из нуля и более экземпляров класса CodedConcept (кодированное понятие), взятых из одного и того же экземпляра класса CodeSystem (система кодирования). Экземпляр класса ValueSet может представлять:
- все кодированные понятия CodedConcept, определенные ровно в одной системе кодирования CodeSystem;
- конкретный список кодированных понятий CodedConcept, определенных ровно в одной системе кодирования CodeSystem;
- совокупность кодированных понятий CodedConcept, представленных другим набором значений ValueSet.
Детальные сведения о каждой из этих форм приведены в следующих подразделах. Вначале будут описаны характеристики, общие для всех наборов значений.
Ожидается, что наборов значений столь много, что просто невозможно присвоить каждому из них уникальную мнемонику или значащее имя. Основным идентификатором экземпляра класса ValueSet является атрибут valueSet_id, имеющий числовое значение, не имеющее смысловой нагрузки![]() . При необходимости атрибут valueSet_name может также содержать уникальный "смысловой" идентификатор набора значений. Этот атрибут предназначен для коммуникаций между углеродными формами жизни.
. При необходимости атрибут valueSet_name может также содержать уникальный "смысловой" идентификатор набора значений. Этот атрибут предназначен для коммуникаций между углеродными формами жизни.
_______________
![]() В качестве такого значения, скорее всего, будет использоваться объектный идентификатор ИСО с корнем, 2.16.840.1.113883.1.11, но это решение окончательно не принято.
В качестве такого значения, скорее всего, будет использоваться объектный идентификатор ИСО с корнем, 2.16.840.1.113883.1.11, но это решение окончательно не принято.
Класс ValueSet имеет атрибут description (описание), описывающий назначение и цель создания набора значений. Он имеет также атрибут definingExpression (определяющее выражение), предназначенный для хранения формального машиночитаемого выражения, которое может использоваться для конструирования набора значений. Значение и интерпретация этого выражения в данном документе не обсуждаются. Оба атрибута (description и definingExpression) не обязательны. Еще один атрибут класса ValueSet, а именно, allCodes (все коды), описан ниже.
7.3.3 Определение содержания набора значений
Набор значений ValueSet может быть построен из одного другого набора значений ValueSet либо может быть основан ровно на одной системе кодирования CodeSystem, либо может быть построен из того и другого![]() . Система кодирования CodeSystem определяет нуль или более кодированных понятий CodedConcepts, которые, в свою очередь, обозначают релевантные классы или сущности в конкретной области интереса. Системы кодирования могут ранжироваться от простой таблицы пола человека до классификаторов типа МКБ-9 и до семантически богатых систем, основанных на логических представлениях, например, OpenGalen или SNOMED-CT. Поскольку многие системы кодирования регулярно пересматриваются, полезно регистрировать версию выпуска ReleaseVersion, использованную для определения данного набора значений ValueSet в конкретный момент времени. Набор значений ValueSet может быть определен с использованием не более одной версии ReleaseVersion. Определение с помощью отношения служит исключительно для справочных целей и для представления содержания набора значений службы ValueSet могут использовать более позднюю версию системы кодирования
. Система кодирования CodeSystem определяет нуль или более кодированных понятий CodedConcepts, которые, в свою очередь, обозначают релевантные классы или сущности в конкретной области интереса. Системы кодирования могут ранжироваться от простой таблицы пола человека до классификаторов типа МКБ-9 и до семантически богатых систем, основанных на логических представлениях, например, OpenGalen или SNOMED-CT. Поскольку многие системы кодирования регулярно пересматриваются, полезно регистрировать версию выпуска ReleaseVersion, использованную для определения данного набора значений ValueSet в конкретный момент времени. Набор значений ValueSet может быть определен с использованием не более одной версии ReleaseVersion. Определение с помощью отношения служит исключительно для справочных целей и для представления содержания набора значений службы ValueSet могут использовать более позднюю версию системы кодирования![]() . Более детальное обсуждение систем кодирования приведено ниже, в подразделе, описывающем API словаря ОТС.
. Более детальное обсуждение систем кодирования приведено ниже, в подразделе, описывающем API словаря ОТС.
_______________
![]() Можно сконструировать набор значений, ссылающийся на другие наборы значений, извлеченные более чем из одной системы кодирования. Однако конкретный набор значений может напрямую ссылаться только на понятия, извлеченные из единственной системы кодирования.
Можно сконструировать набор значений, ссылающийся на другие наборы значений, извлеченные более чем из одной системы кодирования. Однако конкретный набор значений может напрямую ссылаться только на понятия, извлеченные из единственной системы кодирования.
![]() Настоящий документ не содержит обсуждение того, как указать конкретную версию системы кодирования или состояние набора значений в определенный момент времени. Соответствующие разделы появятся в следующих выпусках документа.
Настоящий документ не содержит обсуждение того, как указать конкретную версию системы кодирования или состояние набора значений в определенный момент времени. Соответствующие разделы появятся в следующих выпусках документа.
7.3.3.1 Представление всего содержания системы кодирования
Присвоив значения TRUE атрибуту allCodes, можно указать, что в данный набор значений ValueSet должны быть включены все кодированные понятия CodedConcept, определенные в системе кодирования CodeSystem, на которой основан этот набор. Такой набор значений ValueSet не может дополнительно включать в себя ссылки на кодированные понятия CodeReference. Пример набора значений, представляющего всю систему кодирования, приведен в таблице 8.
Таблица 8 - Набор значений, представляющий все содержание системы кодирования
valueSet_id | valueSet_name | description | allCodes | CodeSystem | Версия |
2.16.840.1.11 | AdministrativeGender | Пол лица, используемый для административных целей (в отличие от клинического пола) | True | 2.16.840.1.11 | 5 |
7.3.3.2 Представление частей содержания системы кодирования
Набор значений ValueSet может включать в себя нуль или более кодированных понятий CodedConcept, определенных в системе кодирования CodeSystem, на которой он основан. Это выполняется с помощью включения в набор значений одной или нескольких ссылок CodeReference. Такая ссылка связывает кодированное понятие CodedConcept с набором значений ValueSet. Она должна ссылаться ровно на одно кодированное понятие CodedConcept. При этом атрибут relation_code подразумевает неявные ссылки на все кодированные понятия CodedConcept, являющиеся целью отношения ConceptRelationship к явно включенному кодированному понятию CodedConcept. В ссылке CodeReference можно указать, что само это ссылочное понятие CodedConcept включено в набор значений или исключено из него. С помощью отношения ConceptRelationship можно включить все целевые коды понятий или только конечные узлы (листья). Эти различные возможности отражены в значениях атрибутов includeReferencedCode, relationship_code и leafOnly, приведенных в таблице 9.
Таблица 9 - Варианты значений атрибутов, управляющих ссылками на понятия
allCodes | includeReferencedCode | relationship_code | leafOnly | Описание |
True | - | - | - | Включает в набор значений все коды, описанные в системе кодирования |
False | True | - | - | Включает в набор значений только ссылочный код понятия |
False | True | hasSubtype | False | Включает в набор значений ссылочный код и все его подтипы |
False | False | hasSubtype | False | Включает в набор значений все подтипы ссылочного кода, но не сам этот код |
False | False | hasSubtype | True | Включает в набор значений только листовые подтипы ссылочного кода |
Иные сочетания значений атрибутов, кроме тех, что перечислены в таблице 9, не допустимы. По возможности значения атрибута relation_code должны браться из системы кодирования HL7 RelationshipCode.
7.3.4 Включение в набор значений других наборов значений
Набор значений ValueSet может быть также построен, используя нуль или более дополнительных наборов значений. Включение в его состав набора значений ValueSet означает, что все кодированные понятия CodedConcept, представленные включаемым набором, должны стать частью результирующего набора. Класс ValueSetConstructor (конструктор набора значений) служит двум целям:
1) С его помощью можно включать наборы значений по ссылке, что позволяет всем изменениям этих наборов автоматически отражаться в результирующем наборе.
2) Использование этого класса позволяет включать в результирующий набор ValueSet кодируемые понятия CodedConcept, взятые более чем из одной системы кодирования CodeSystem.
В таблице 10 приведен пример конструирования набора значений HL7Conformancelnclusion, включающего в себя набор значений InclusionNotMandatory, который, в свою очередь, включает в себя набор InclusionNotRequired.
Таблица 10 - Пример конструирования наборов значений
usedToBuildSet | (имя) | includedSet | (имя) | includeHeadCode |
2.16.840.1.1138 | HL7Conformancelnclusion | 2.16.840.1.1138 | InclusionNot Mandatory | False |
2.16.840.1.1138 | InclusionNotMandatory | 2.16.840.1.1138 | InclusionNot Required | True |
7.3.5 Головные коды
Набор ValueSet значений ссылается на совокупность кодированных понятий CodedConcept. Нередко ассоциация между набором значений ValueSet и коллекцией кодированных понятий CodedConcept означает категоризацию, отношение "часть - целое" или иное иерархическое отношение, в котором сам набор значений представляет "целое" (родителя), а коды понятий - отдельные "части" (потомки). В этом случае в системе кодирования может существовать соответствующий код понятия, представляющий подобное понятие "целого" или "родителя". Такой код будет именоваться "головным кодом" ассоциированного набора значений. Многие кодированные атрибуты модели HL7 RIM могут иметь разные степени общности. В примере набора значений, указанном в таблице 10, набор значений InclusionNotRequired имеет головной код NR (не требуется) и два подчиненных кода - X (исключен) и RE (требуется, но может быть пустым). Значение True атрибута includeHeadCode, указанное во второй строке этой таблицы, означает, что для этого набора допустимыми значениями могут быть X (исключен), RE (требуется, но может быть пустым) и NR (включение не требуется по неспецифичной причине).
Если набор значений используется для построения другого набора, то головной код может быть или не быть частью включаемого набора. Тем самым обеспечивается возможность того, что сообщество HL7 называет "абстрактными" и "специализируемыми" наборами значений. Набор значений ValueSet может быть идентифицирован не более чем одним кодированным понятием, называемым "головным кодом". Кодированное понятие CodedConcept может служить головным кодом для нуля и более наборов значений ValueSet.
7.4 Зарегистрированная система кодирования
Многие системы кодирования, используемые в стандартах HL7, предоставляются внешними организациями. Класс CodeSystem, который будет определен в этом документе позже, представляет характеристики, общие для всех систем кодирования, используемых в среде HL7. Комитет HL7 ведет также внутренний регистр систем кодирования, содержащий их метаданные. Цель этого регистра - служить центральным хранилищем метаданных всех систем кодирования, которые могут использоваться в сообщениях, соответствующих стандартам HL7, вне зависимости от того, являются ли они внутренними для места реализации или системы либо общепринятыми и санкционированными для ряда систем.
С точки зрения комитета HL7, регистрация не означает "санкционирование". Она является просто ссылкой. В процессе регистрации системе кодирования присваивается объектный идентификатор (ОИД), если его у нее еще не было. На рисунке 5 показана диаграмма классов зарегистрированной системы кодирования.
Рисунок 5 - Зарегистрированная система кодирования
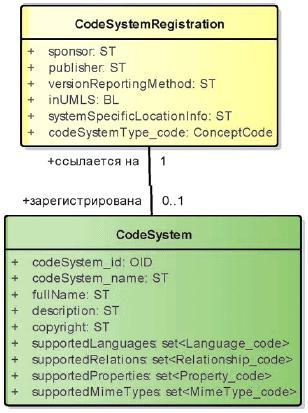
Рисунок 5 - Зарегистрированная система кодирования
Класс CodeSystemRegistration (регистрация системы кодирования) имеет следующие атрибуты:
- sponsor - именование, адрес и другие подобные данные лица либо организации, которая официально спонсирует эту систему кодирования для комитета HL7;
- publisher - наименование, адрес и другие подобные данные организации, ответственной за создание и ведение этой системы кодирования;
- versionReportingMethod - описание того, как и сколь часто создаются и распространяются новые версии;
- licensinglnformation - описание требуемых лицензий, цены и способа приобретения;
- inUMLS - значение TRUE указывает, что кодированные термины, определенные в этой системе кодирования, включены в Унифицированную систему медицинского языка UMLS (Unified Medical Language System);
- systemSpecificLocatorlnfo - информация, специфичная для издателя системы кодирования. Она служит для определения или идентификации конкретной системы кодирования. Комитет HL7 может иногда использовать атрибут systemSpecificLocatorlnfo для идентификации соответствующей таблицы стандарта HL7 2.x, если таковая имеется;
- codeSystemType_code - код, имеющий значения I (система кодирования является внутренней, ведется и распространяется комитетом HL7), Е (ведется и распространяется третьей стороной), EI (ведется третьей стороной, но распространяется комитетом HL7).
8 Спецификация API сообщений ОТС
8.1 Введение
API сообщений ОТС (CTSMAPI - CTS Message API) состоит из двух разделов - раздел времени исполнения, определяющий комплекс функций, необходимых для каждодневных операций программного обеспечения, обрабатывающего сообщения, соответствующие стандарту HL7 Версии 3, и раздел обозревателя, определяющего функции, предназначенные для разработки и конструирования этих сообщений. Программному обеспечению, использующему функции обозревателя, может понадобиться доступ к функциям времени исполнения, в то время как программное обеспечение времени исполнения может не иметь доступа к функциям обозревателя.
8.2 Общие элементы сообщений ОТС
8.2.1 Основные элементы данных
В следующем пункте определены основные типы данных, используемые в API сообщений ОТС. Все типы, имена которых имеют префикс "types::", основаны на стандарте HL7 Версии 3 Data Types и далее здесь не обсуждаются.
Основные типы данных в API сообщений ОТС включают в себя:
- CTSVersionld - структура, содержащая старшую и младшую части номера версии спецификации ОТС. У текущей версии старшая часть равна 1, младшая - равна 0 (1.0);
- CodeSystemld - уникальный идентификатор системы кодирования. В контексте стандартов HL7 им должен быть объектный идентификатор ИСО (ОИД), присвоенный комитетом HL7, если таковой имеется. Другие виды идентификаторов, например UUID, определенный для среды распределенных вычислений DCE (Distributed Computing Environment), и т.д., могут использоваться в качестве идентификаторов систем кодирования вне среды применения стандартов HL7. В этих случаях разработчик должен предупреждать любые конфликты пространств имен, которые могут возникать между ОИД и другими идентификаторами;
- CodeSystemName - имя системы кодирования. Как идентификатор системы кодирования, так и ее имя уникальны в пространстве имен, контролируемом стандартом HL7 Версии 3, но в общем случае уникальность не гарантируется;
- ConceptCode - код, уникально представляющий класс или понятие в данной системе кодирования;
- VocabularyDomainName - уникальное имя словарного домена HL7;
- ReleaseVersionld - идентификатор, уникально обозначающий выпуск/версию в контексте системы кодирования;
- ValueSetld - объектный идентификатор ИСО (ОИД), уникально идентифицирующий набор значений HL7;
- ValueSetName - уникальное имя или мнемокод набора значений. Не у всех наборов значений есть и идентификатор, и имя, но если таковые имеются, то они должны быть уникальны;
- Conceptld - сочетание идентификаторов системы кодирования и кода понятия, являющееся глобально уникальным именем понятия;
- ReleaseVersionld - уникальный идентификатор версии или выпуска одной или нескольких систем кодирования;
- ExpansionContext - непрозрачный большой двоичный объект, используемый для передачи контекстной информации между сервером и клиентом.
8.2.2 Коды понятий
В API сообщений используется следующий ряд кодированных атрибутов:
- LanguageCode - код разговорного или письменного языка, конструируемый по правилам, описанным в документе IETF RFC 3066 - Tag for Identification of Languages (теги идентификации языка). Этот код состоит из нескольких субтегов, разделенных дефисами ("-"). Первый субтег идентифицирует основной код языка. По возможности он должен быть взят из ИСО 639-1 "Codes for the representation of names of languages - Part 1: Alpha-2 code" (Коды для представления названий языков. Часть 1. Двухбуквенный код). Если двухбуквенный код отсутствует, то надо взять код из ИСО 639-2 "Codes for the representation of names of languages - Part 2: Alpha-3 code" (Коды для представления названий языков. Часть 2. Трехбуквенный код). Существует также дополнительный механизм спецсимволов, который в настоящем стандарте не описан.
Второй субтег не обязателен. Если он присутствует, то должен иметь длину от 2 до 8 символов. Если его длина равна двум, то он должен содержать двухбуквенный код страны, взятый из ИСО 3166-1 "Codes for the representation of names of countries and their subdivisions - Part 1: Country codes" (Коды для представления названий стран и единиц их административно-территориального деления. Часть 1. Коды стран). Если длина субтега от 3 до 8 символов, то он должен содержать код, взятый из регистра тегов языков организации IANA. Дополнительные субтеги используются, если надо уточнить информацию о языке;
- RelationshipCode - код понятия, уникально определяющего конкретное отношение, имеющее место в системе кодирования. По возможности коды отношений должны браться из системы кодирования HL7 ConceptRelationship;
- ApplicationContextCode - код, идентифицирующий контекст или область применения, например, геополитическое образование, профессию или другую сферу.
- DataTypeCode - код, идентифицирующий тип данных атрибута модели RIM (например, CD, СЕ, CS, BIN, ST и т.д.).
- CodingStrengthCode - код, указывающий, как должны трактоваться некодированные значения атрибута, определенного в стандарте HL7 (CWE - кодированный с разрешением исключений, CNE - кодированный без исключений);
- ValueSetNodeTypeCode - код, определяющий тип набора значений, возвращаемого в виде иерархического списка. Коды имеют следующие значения: А (абстрактный) означает, что набор значений не может быть выбран; S (специализируемый) означает, что набор значений может быть выбран, но имеет дальнейшие уточнения; L (list) означает, что узел представляет выбираемый код понятия, которое не имеет дальнейших уточнений;
- CodeSystemTypeCode - код, имеющий значения I (система кодирования является внутренней, которая ведется комитетом HL7), Е (ведется третьей стороной), EI (ведется третьей стороной, но в распоряжение комитета HL7 предоставлена внутренняя копия);
- MatchAlgorithmCode - код, идентифицирующий алгоритм совпадения строк, используемый во внутренних функциях поиска.
В таблице перечислены системы кодирования и идентификаторы ОИД, используемые в MAPI сообщений, предоставляемом ОТС.
Таблица 11 - Идентификаторы ОИД и имена кодируемых элементов данных
Элемент данных MAPI | ОИД системы кодирования | Имя системы кодирования | Описание |
LanguageCode | 2.16.840.1.11388 | ISO 639-1 Two character Alpha Language Codes | Двухсимвольные коды языков ИСО 639-1 |
LanguageCode | 2.16.840.1.11388 | ISO 639-2 Three character Alpha Language Codes | Трехсимвольные коды языков ИСО 639-2 |
RelationshipCode | 2.16.840.1.11388 | ConceptCodeRelationship | Отношения кодов понятий |
ApplicationContextCode | 2.16.840.1.11388 | VocabularyDomainQualifier. RealmOfUse | Квалификатор словарного домена - область применения |
DataTypeCode | 2.16.840.1.11388 | DataType | Тип данных |
CodingStrengthCode | 2.16.840.1.11388 | VocabularyDomainQualifier | Квалификатор словарного домена |
ValueSetNodeTypeCode | 2.16.840.1.11388 | ConceptGenerality | Степень общности понятия |
CodeSystemType | 2.16.840.1.11388 | CodeSystemType | Тип системы кодирования |
MatchAlgorithmCode | 2.16.840.1.11388 | MatchAlgorithm | Алгоритм совпадения |
8.2.2.1 Алгоритмы совпадения строк
Некоторым описанным ниже функциям могут передаваться строковые значения в качестве критериев поиска. Этим значениям сопутствует "код алгоритма совпадения", определяющий, как будут применяться эти значения. В таблице перечислен список предопределенных алгоритмов совпадения. Если в графе "Обязателен" указано значение TRUE, то все реализации службы, объявляющие совместимость с данным стандартом, должны использовать этот алгоритм. Если в графе "Обязателен" указано значение FALSE, то служба не обязательно должна реализовать этот алгоритм, но если реализует, то в качестве его идентификатора должна использовать код, указанный в таблице 12. Данный список алгоритмов совпадения не является исчерпывающим. При необходимости реализация службы может расширить этот список собственными алгоритмами совпадения, но в целях будущей интероперабельности разработчикам службы настоятельно рекомендуется зарегистрировать код алгоритма в комитете HL7.
Таблица 12 - Коды алгоритмов совпадения
Код алгоритма совпадения | Описание | Обязателен |
IdenticallgnoreCase | Целевой текст, представленный в нижнем регистре, должен точно совпадать с представлением параметра matchText в нижнем регистре | TRUE |
Identical | Целевой текст должен точно совпадать со значением параметра matchText | FALSE |
StartsWithlgnoreCase | Целевой текст, представленный в нижнем регистре, должен начинаться с подстроки, совпадающей с представлением значения параметра matchText в нижнем регистре | TRUE |
StartsWith | Целевой текст должен начинаться с подстроки, совпадающей со значением параметра matchText | FALSE |

{kind=link}