ГОСТ Р ИСО 21090-2016
Группа П85
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Информатизация здоровья
ГАРМОНИЗИРОВАННЫЕ ТИПЫ ДАННЫХ ДЛЯ ОБМЕНА ИНФОРМАЦИЕЙ
Health Informatics. Harmonized data types for information interchange
ОКС 35.240.80
ОКСТУ 4002
Дата введения 2018-01-01
Предисловие
Предисловие
1 ПОДГОТОВЛЕН на основе официального перевода на русский язык англоязычной версии указанного в пункте 4 стандарта, который выполнен Федеральным государственным учреждением "Центральный научно-исследовательский институт организации и информатизации здравоохранения Министерства здравоохранения Российской Федерации" (ЦНИИОИЗ Минздрава РФ) и Обществом с ограниченной ответственностью "Корпоративные электронные системы"
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 468 "Информатизация здоровья" при ЦНИИОИЗ Минздрава РФ - постоянным представителем ISO/TC 215
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 29 ноября 2016 г. N 1840-ст
4 Настоящий стандарт идентичен международному стандарту ИСО 21090:2011* "Информатизация здоровья. Гармонизированные типы данных для обмена информацией" (ISO 21090:2011 "Health Informatics - Harmonized data types for information interchange", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым здесь и далее по тексту, можно получить, перейдя по ссылке на сайт . - .
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные межгосударственные стандарты, сведения о которых приведены в дополнительном приложении ДА
5 ВВЕДЕН ВПЕРВЫЕ
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ежемесячном информационном указателе "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
1 Область применения
Настоящий стандарт:
- содержит комплекс определений типов данных, предназначенных для представления и передачи основных понятий, широко используемых при обмене информацией в сфере здравоохранения;
- определяет комплекс специфичных типов данных, пригодных для использования в информационных системах здравоохранения, используемых в различных условиях оказания медицинской помощи;
- определяет семантику этих типов данных с помощью терминологии, нотации и типов данных, определенных в ИСО/МЭК 11404, тем самым расширяя комплекс типов данных, специфицированных в этом стандарте;
- приводит определения этих же типов данных на языке UML, используя терминологию, нотацию и типы данных, определенные в спецификации унифицированного языка моделирования (Unified Modeling Language, UML) версии 2.0;
- приводит представления этих типов данных на языке XML (eXtensible Markup Language).
Требования, определяющие область применения, в основном позаимствованы из HL7 версии 3, ИСО/МЭК 11404, а также из CEN/TS 14796, ИСО 13606 (все части) и предшествующей работы в ИСО над типами данных, используемых в сфере здравоохранения.
Хотя настоящий стандарт может внести практический и полезный вклад в стандартизацию внутренней архитектуры медицинских информационных систем, он в первую очередь предназначен для использования при проектировании внешних интерфейсов или сообщений, обеспечивающих взаимодействие этих систем.
2 Нормативные ссылки
В настоящем стандарте использованы ссылки на следующие документы* (для датированных ссылок следует использовать только указанное издание, для недатированных ссылок следует использовать последнее издание указанного документа, включая все поправки).
_______________
* Таблицу соответствия национальных стандартов международным см. по ссылке. - .
ISO 4217, Codes for the representation of currencies and funds (Коды для представления валют и фондов)
ISO/IEC 8601 Data elements and interchange formats - Information interchange - Representation of dates and times (Элементы данных и форматы для обмена информацией. Обмен информацией. Представление дат и времени)
ISO/IEC 8824:1990 Information technology - Open Systems Interconnection - Specification of Abstract Syntax Notation One (ASN.1) [Информационные технологии. Взаимодействие открытых систем. Нотация абстрактного синтаксиса версии 1 (ASN.1)]![]()
_______________
![]() Это издание было заменено на серию стандартов ИСО/МЭК 8824:2008 (все части).
Это издание было заменено на серию стандартов ИСО/МЭК 8824:2008 (все части).
ISO/IEC 11404:2007, Information technology - General-Purpose Datatypes (GPD) [Информационные технологии. Типы данных общего назначения (GPD)]
ISO/TS 22220, Health informatics - Identification of subjects of health care (Информатизация здоровья. Идентификация субъектов медицинской помощи)
IETF RFC 1738 - Uniform Resource Locators (URL) (Унифицированные указатели ресурсов)
IETF RFC 1950 - ZLIB Compressed Data Format Specification version 3.3 (Спецификация формата сжатия данных ZLIB версии 3.3)
IETF RFC 1951 - DEFLATE Compressed Data Format Specification version 1.3 (Спецификация формата сжатия данных DEFLATE версии 1.3)
IETF RFC 1952 - GZIP File Format Specification version 4.3 (Спецификация формата сжатия файлов GZIP версии 4.3)
IETF RFC 2045 - Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies [Многоцелевые расширения электронной почты в Интернете (MIME). Часть 1. Формат тела сообщений в Интернете]
IETF RFC 2046 - Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types [Многоцелевые расширения электронной почты в Интернете (MIME). Часть 2. Типы среды]
IETF RFC 2396 - Uniform Resource Identifiers (URI): Generic Syntax [Унифицированные идентификаторы ресурсов (URI). Общий синтаксис]
IETF RFC 2806 - URLs for Telephone Calls (Представление телефонных номеров в форме URL)![]()
_______________
![]() Заменен на документ IETF RFC 3966.
Заменен на документ IETF RFC 3966.
IETF RFC 3066 - Tags for the Identification of Languages (Теги для идентификации языков)
FIPS PUB 180-1 - Secure Hash Standard (Стандарт безопасной хеш-функции)
FIPS PUB 180-2 - Secure Hash Standard (Стандарт безопасной хеш-функции)![]()
_______________
![]() Редакция документа FIPS PUB 180-1.
Редакция документа FIPS PUB 180-1.
Open Group, CDE 1.1 - Remote Procedure Call specification, Appendix А (Спецификация вызова удаленной процедуры. Приложение А)
HL7 V3 Standard, Data Types - Abstract Specification (R2) (Типы данных. Абстрактная спецификация. Выпуск 2)
Regenstrief Institute, Inc. and the UCUM Organization The Unified Code for Units of Measure (Regenstrief Institute, Inc. and the UCUM Organization Унифицированные коды единиц измерения)![]()
_______________
![]() Regenstrief Institute, Inc. and the UCUM Organization, Indianapolis, Indiana, USA. - //aurora.regenstrief.org/ucum (ссылка от 23 августа 2010 г.).
Regenstrief Institute, Inc. and the UCUM Organization, Indianapolis, Indiana, USA. - //aurora.regenstrief.org/ucum (ссылка от 23 августа 2010 г.).
XML W3C Recommendation, XML Digital Signature (Рекомендации консорциума W3C. Электронная подпись)![]()
_______________
![]() World Wide Web Consortium (W3C). - https://www.w3.org/TR/xmldsig-core/ (ссылка от 23 августа 2010 г.).
World Wide Web Consortium (W3C). - https://www.w3.org/TR/xmldsig-core/ (ссылка от 23 августа 2010 г.).
3 Термины и определения
В настоящем стандарте применены следующие термины с соответствующими определениями:
3.1 атрибут (attribute): Характеристика объекта, которому присвоены тип и имя.
Примечание - Значение атрибута может меняться в течение жизненного цикла объекта.
3.2 класс (class): Дескриптор множества объектов, обладающих аналогичной структурой, поведением и связями.
3.3 код (code): Кодированное представление, опубликованное автором системы кодирования в качестве части системы кодирования и являющееся элементом данной системы кодирования.
3.4 система кодирования (code system): Управляемая коллекция идентификаторов понятий (обычно кодов), но иногда являющаяся более сложной системой правил и ссылок.
Примечание - Нередко системы кодирования описываются как коллекции уникально идентифицируемых понятий и ассоциированных с ними представлений, отношений и смысловых значений.
Примеры - МКБ-9, LOINC и SNOMED.
3.5 понятие (concept): Унитарное мысленное представление реальной или абстрактной сущности; атомарная единица мышления.
Примечания
1 Понятие должно быть уникальным в данной системе кодирования.
2 Понятие может иметь синонимы в терминах представления и может быть простым или составным термином.
3.6 соответствие (conformance): Выполнение указанного требования; соответствие элемента обработки информации требованиям одной или нескольких специфичных спецификаций стандарта.
3.7 тип данных (datatype): Множество различных значений, характеризуемое свойствами этих значений и операциями над этими значениями.
3.8 перечисление (enumeration): Тип данных, экземпляры которого являются множествами литералов перечисления, задаваемых пользователем.
Примечание - Литералы имеют относительное упорядочение, но никакая алгебра над ними не определена.
3.9 генерализация (generalization): Отношение таксономии между более общим классом, интерфейсом или понятием и менее общим классом, интерфейсом или понятием.
Примечания
1 Каждый экземпляр специфичного элемента является также экземпляром общего элемента. Поэтому специфичный элемент обладает всеми свойствами более общего элемента.
2 Более специфичный элемент полностью совместим с более общим элементом и содержит дополнительную информацию.
3 Экземпляр более специфичного элемента может быть использован там, где допустимо использование более общего элемента.
3.10 элемент обработки информации (information processing entity): Любая сущность, обрабатывающая информацию и содержащая понятие типа данных, включая другие стандарты, спецификации, средства и службы обработки данных.
3.11 наследование (inheritance): Механизм, с помощью которого более специфичные элементы наследуют структуру и поведение более общих элементов.
3.12 интерфейс (interface): Спецификация внешне видимой операции класса, не включающая в себя описание внутренней структуры.
3.13 инвариант (invariant): Правило о свойстве класса, которое всегда должно быть истинным.
3.14 операция (operation): Услуга, которая может быть запрошена у экземпляра класса.
Примечание - Операция имеет имя и список аргументов, которым присвоены имена и типы. Операция возвращает значение определенного типа.
3.15 специализация (specialization): Отношение таксономии между более общим классом, интерфейсом или понятием и менее общим классом, интерфейсом или понятием, при котором у более специфичной сущности появляются новые свойства или переопределяются имеющиеся свойства с помощью ограничений, накладываемых на их возможное поведение.
3.16 набор строковых символов (string character set): Набор символов, используемых в стандарте для всего строкового содержания.
3.17 набор значений (valueSet): Сущность, представляющая уникально идентифицируемое множество допустимых представлений понятий, позволяющая проверить для любого представления понятия, принадлежит оно набору значений или нет.
Примечание - Понятие может быть представлено с помощью отдельного кода или с помощью посткоординируемого сочетания кодов.
4 Сокращения
Для целей настоящего документа применяются следующие сокращения терминов:
CEN | - |
CNE | - Coded no exceptions (кодированный без исключений); |
CWE | - Coded with exceptions (кодированный с исключениями); |
GPD | - General-Purpose Datatypes (типы данных общего назначения); |
HL7 | - Health Level 7; |
IETF | - Internet Engineering Task Force (Инженерный совет Интернета); |
OID | - Object Identifier (объектный идентификатор); |
OMG | - Object Management Group (группа управления объектами); |
UML | - Unified Modelling Language (унифицированный язык моделирования); |
W3C | - World Wide Web Consortium (консорциум World Wide Web); |
XML | - eXtensible Markup Language (расширяемый язык разметки). |
5 Соответствие
5.1 Общие сведения
Программа, система, элемент либо иная сущность, обрабатывающая информацию, может соответствовать настоящему стандарту либо непосредственно используя описанные в нем типы данных соответствующим образом, либо косвенно с помощью отображения внутренних типов данных, используемых сущностью, на типы данных, описанные в настоящем стандарте.
Примечание - Термин "элемент обработки информации" используется в соответствии с определением 3.10. Аналогичным образом он описан в разделе 4 ИСО/МЭК 11404:2007, а именно: это определение охватывает прикладные программы, а также другие стандарты и спецификации.
5.2 Непосредственное соответствие
5.2.1 Определение непосредственного соответствия
Элемент обработки информации, непосредственно соответствующий данному стандарту, должен:
a) указывать, какие типы данных, указанные в разделе 7, предусмотрены элементом, а какие не предусмотрены;
b) определять пространства значений типов данных, предназначенных для здравоохранения и используемых этим элементом, которые идентичны пространствам значений, описанным в настоящем стандарте;
c) указывать, в какой мере пространства значений типов данных ограничены при использовании в контексте этого элемента;
d) определять операции над типами данных, предназначенных для здравоохранения, отличающиеся от перемещения или преобразования значений, таким образом, чтобы они или выводились из характеристических операций, описанных в настоящем стандарте, или соответствовали им каким-либо иным образом;
e) если для представления этих типов данных в элементе применяется язык XML, то использовать XML-представления, приведенные в настоящем стандарте;
f) публиковать (что необязательно) формальный профиль соответствия, позволяющий точно описать соответствие, или ссылаться на профиль, опубликованный другим элементом обработки информации.
Приведенные выше требования препятствуют использованию спецификатора типа, определенного в настоящем стандарте в целях обозначения любого другого типа данных (однако следует учесть обсуждение области применения имен типов данных, приведенное в 6.2). Другие ограничения на определение элементом обработки информации дополнительных типов данных из них не вытекают. Например, элемент обработки информации, непосредственно соответствующий настоящему стандарту, может продолжать использовать типы данных общего назначения, определенные в ИСО/МЭК 11404, в дополнение к типам данных, предназначенным для здравоохранения.
Из требования d) не следует, что должны быть реализованы все характеристические операции. Могут быть предусмотрены дополнительные операции. Намерение состоит в разрешении таких дополнительных семантических интерпретаций типов данных, которые не конфликтуют с интерпретациями, приведенными в настоящем стандарте. Такие конфликты могут возникнуть только в том случае, когда элемент предоставляет для данного типа такие операции, при которых конкретная характеристическая операция не может быть реализована или не является конструктивной.
Примерами элементов, для которых может быть обеспечено непосредственное соответствие, служат языковые определения или спецификации, выпускаемые для сферы здравоохранения, их натации, а также определения, приведенные в настоящем стандарте. Кроме того, не должен запрещаться буквальный перевод синтаксиса и определений типов данных, приведенных в настоящем стандарте, с помощью программных средств или пакетов прикладных программ.
Элементы обработки информации, объявляющие непосредственное соответствие настоящему стандарту, не обязаны всегда использовать для представления понятий те типы данных, которые определены в настоящем стандарте, хотя бы потому, что из наличия типа данных адреса не следует, что он всегда должен использоваться для представления адреса. Однако типы данных, определенные в настоящем стандарте, обязательно должны использоваться в тех случаях, когда они применяются в контексте интероперабельности.
Элементы обработки информации, объявляющие непосредственное соответствие настоящему стандарту, могут накладывать дополнительные ограничения на домены значений любого типа данных в контексте его использования. В объявлении соответствия должны быть точно описаны применение этих ограничений элементом обработки информации и алгоритм обработки тех значений, которые не соответствуют наложенным ограничениям.
С помощью этих критериев можно оценить совместимость характеристических операций, определенных элементом, соответствующим настоящему стандарту. Если операции имеют то же имя, что и операция, определенная в настоящем стандарте, то они совместимы с ней, если операция, вызванная с теми же самыми параметрами, возвращает тот же самый результат. Она может иметь другие параметры, но либо для них должны быть предусмотрены значения по умолчанию, либо должно быть дано дополнительное определение одноименной операции с другим списком параметров.
В элементах обработки информации, объявляющих непосредственное соответствие настоящему стандарту, не обязательно должны присутствовать все типы данных, определенные в настоящем стандарте, либо определенный тип данных. В них могут использоваться другие термины, например, "структуры данных".
5.2.2 Объявления соответствия
Для элемента обработки информации, объявляющего непосредственное соответствие настоящему стандарту, должно быть составлено объявление соответствия.
Предполагается, что другие органы стандартизации составят объявления соответствия настоящему стандарту как в общем смысле, так и в смысле принятия определенных в нем типов данных в конкретном стандарте. Кроме того, предполагается, что в некоторых странах будут опубликованы профили этих типов данных в качестве справочного или нормативного документа. Наконец, производители и заказчики информационных систем здравоохранения могут найти полезным создание, совместное использование и публикацию таких объявлений соответствия.
Настоящий стандарт не предписывает ни какую-либо определенную форму объявления, ни способ публикации. Однако объявление соответствия должно иметь точные формулировки, формальное представление и предоставляться всем заинтересованным сторонам, имеющим отношение к области применения данного элемента обработки информации.
Наряду с требованиями, что объявления соответствия должны содержать формальные объявления о соответствии требованиям, указанным в пунктах а)-d) 5.2.1, настоящий стандарт дополнительно устанавливает следующие правила о том, что в этих объявлениях должно быть упомянуто, или рекомендуется упомянуть, или может быть выбрано.
Следующие правила обязательны для объявлений непосредственного соответствия:
a) указание используемого набора символов и кодировки; по умолчанию - Unicode (см. 6.7.5);
b) если для ведения истории изменений и аудита данных использован альтернативный способ, то описание его отображения на информацию об изменении и аудите типов данных (см. 7.1.3);
c) пояснение способа указания кратности атрибутов и коллекций (см. 7.1.5);
d) описание применения атрибутов nullFlavor, updateMode и flavorld типа данных ANY (см. подраздел 7.3.3);
e) если использованы типы данных физических величин, приведение точного описания того, как и когда в типе данных QTY применены атрибуты expression, originalText и атрибуты различных неопределенностей;
f) пояснение, какие методы могут быть использованы для альтернативных определений уникальности дискретного множества (см. 7.9.3);
g) если использованы типы данных структурированных документов, описание области применения контекста документов и приведение точного описания того, каким образом разрешаются ссылки внутри этого контекста (см. 7.12);
h) описание, в какой мере приемлем формат XML и указание используемого в нем пространства имен (см. А.1).
Следующие правила рекомендованы для объявлений непосредственного соответствия:
a) определение правил по умолчанию языка (см. 7.4.2.3.7);
b) указание, какие языки могут быть использованы в свойстве QTY.expression (см. 7.8.2.3.1);
c) указание, какие коды могут быть использованы в свойстве QSC.code (см. 7.10.8.3);
d) если использованы типы данных структурированных документов, описание, каким образом обеспечивается версионность в том контексте, где она применяется (см. 7.12.12.2.1).
В объявлениях непосредственного соответствия можно также придерживаться следующих правил:
a) определять дополнительные атрибуты тонкости типов данных или указывать дополнительные уполномоченные органы в определениях атрибутов тонкости (см. 6.7.6);
b) приводить дополнительные описания применения производных данных и интерпретации значения DER свойства nullFlavor (см. 7.1.4);
c) определять, каким образом используется свойство controlnformationRootExtension типа данных HXIT (см. 7.3.2.3.4);
d) пояснять, как выбираются телекоммуникационные и почтовые адреса, предназначенные для конкретных целей (см. 7.6.2.3.2);
e) указывать системы кодирования, используемые для различных компонентов типов данных фамилии, имени, отчества и адреса (см. 7.7.3.6 и 7.7.5.6).
5.3 Косвенное соответствие
5.3.1 Определение косвенного соответствия
Элемент обработки информации, косвенно соответствующий настоящему стандарту, должен:
a) предусматривать отображение своих внутренних типов данных на типы данных, используемые в здравоохранении и соответствующие спецификациям раздела 7;
b) указывать, для каких типов данных, описанных в разделе 7, отображаемый тип является частным случаем, более общим случаем,и для каких типов отображение не предусмотрено;
c) указывать, используется ли представление типов данных в формате XML, описанное в настоящем стандарте, если типы данных представляются в этом формате, или, что не обязательно, предложить в XML-представлении альтернативное пространство имен;
d) публиковать (что необязательно) формальный профиль соответствия, позволяющий точно описать соответствие, или ссылаться на профиль, опубликованный другим элементом обработки информации.
Примерами элементов, для которых может быть обеспечено непосредственное соответствие, служат спецификации, выпускаемые для сферы здравоохранения, спецификации прикладных программ, средств разработки программного обеспечения и другие спецификации интерфейсов, а также многие другие элементы, оперирующие понятием, и существующие для них нотации.
Поскольку настоящий стандарт в большей мере рассчитан на косвенное, а не непосредственное соответствие, то в будущем необходимо предложить стандарты для существующих спецификаций, используемых в сфере здравоохранения.
Элементы обработки информации, объявляющие непосредственное соответствие настоящему стандарту, не обязаны всегда использовать для представления понятий те типы данных, которые определены в настоящем стандарте, хотя бы потому, что из наличия типа данных адреса не следует, что он всегда должен использоваться для представления адреса. Однако типы данных, определенные в настоящем стандарте, обязательно должны использоваться в тех случаях, когда они применяются в контексте интероперабельности.
В элементах обработки информации, объявляющих косвенное соответствие настоящему стандарту, не обязательно должны присутствовать все типы данных, определенные в настоящем стандарте, либо определенный тип данных. В них могут быть использованы другие термины, например, "структуры данных".
5.3.2 Объявления соответствия
Для элемента обработки информации, объявляющего косвенное соответствие настоящему стандарту, должно быть составлено объявление соответствия.
Настоящий стандарт не предписывает ни какую-либо определенную форму объявления, ни способ публикации. Однако объявление соответствия должно точные формулировки*, иметь формальное представление и предоставляться всем заинтересованным сторонам, имеющим отношение к области применения данного элемента обработки информации.
_______________
* Текст документа соответствует оригиналу. - .
Наряду с требованиями, что объявления соответствия должны содержать формальные объявления о соответствии требованиям, указанным в пунктах а)-d) 5.3.1, настоящий стандарт устанавливает следующие дополнительные правила о том, что в этих объявлениях должно быть упомянуто, или рекомендуется упомянуть, или может быть выбрано:
a) указание используемого набора символов и кодировки; по умолчанию - Unicode (см. 6.7.5);
b) описание, какие применяются отношения эквивалентности и каким способом (см. 7.1.2);
c) поясание способа указания кратности атрибутов и коллекций, если таковое имеет место (см. 7.1.5);
d) если использование типы данных структурированных документов, описание области применения контекста документов и приведение точного описания того, каким образом разрешаются ссылки внутри этого контекста (см. 7.12).
Следующие правила рекомендованы для объявлений косвенного соответствия:
a) определение правил по умолчанию языка (см. 7.4.2.3.7);
b) описание отображения между электронной подписью, определенной в спецификации организации W3C, и альтернативными реализациями, если таковые имеют место (см. 7.4.5.1).
В объявлениях непосредственного соответствия можно также придерживаться следующих правил:
a) определять дополнительные атрибуты тонкости типов данных или указывать дополнительные уполномоченные органы в определениях атрибутов тонкости (см. 6.7.6);
b) приводить дополнительные описания применения производных данных и интерпретации значения DER свойства nullFlavor (см. 7.1.4);
c) определять, каким образом используется свойство controlnformationRootExtension типа данных HXIT (см. 7.3.2.3.4);
d) пояснять, как выбираются телекоммуникационные и почтовые адреса, предназначенные для конкретных целей (см. 7.6.2.3.2);
e) указывать системы кодирования, используемые для различных компонентов типов данных фамилии, имени, отчества и адреса (см. 7.7.3.6 и 7.7.5.6);
f) указывать, какие языки могут использоваться в свойстве QTY.expression (см. 7.8.2.3.1);
g) указывать, какие коды могут использоваться в свойстве QSC.code (см. 7.10.8.3);
h) если используются типы данных структурированных документов, описывать, каким образом обеспечивается версионность в том контексте, где она применяется (см. 7.12.12.2.1).
6 Обзор типов данных
6.1 Что такое тип данных?
В ИСО/МЭК 11404 тип данных определен как множество различных значений, характеризуемое свойствами этих значений и операциями над этими значениями (ИСО/МЭК 11404:2007, подраздел 3.12).
Тип данных образован тремя основными свойствами:
- пространство значений;
- множество свойств;
- множество характеристических операций.
В общем случае определения области применения типа данных вращаются вокруг того или иного из следующих понятий;
- неизменность (свойства типа данных не могут меняться, если только не создан новый экземпляр: у типов данных нет жизненного цикла);
- тождество эквивалентности и идентичности (если два типа данных эквивалентны, то они являются одним и тем же экземпляром);
- связность отдельного понятия (каждый тип данных должен представлять пространство отдельных понятий).
Поскольку применение этих понятий к домену информации, используемой в здравоохранении, и к их влиянию на область применения типов данных представляется предметом перспективы, то критерии отбора типов данных для включения в настоящий стандарт основаны на множестве типов, которое образовалось в результате дебатов с различными участвовавшими органами стандартизации, занимающимися разработкой стандартов информатизации здоровья. Поскольку ожидается, что в стандартах и спецификациях информатизации здоровья будет предусмотрено отображение на типы данных, определенных в настоящем стандарте, то процесс отбора был преднамеренно включающим. При развитии других стандартов может быть принято решение представлять эти типы данных с помощью более сложных структур, но при этом должно быть дано разъяснение, как преобразовать эти структуры в типы данных, определенные в настоящем стандарте.
6.2 Определения типов данных
В настоящем стандарте определен комплекс именованных типов данных. С каждым из них связаны и короткое, и длинное имя. Формальным именем типа данных является короткое имя. Каждый тип данных определен двумя разными способами:
- в терминах языка спецификации типов данных и других типов, определенного в ИСО/МЭК 11404;
- на языке UML, используя примитивные типы данных из пакета, представляющего ядро UML.
Определения в терминах ИСО/МЭК 11404 приведены для обеспечения преемтвенности между данным стандартом и документами общего назначения ИСО/МЭК 11404, а определения на языке UML предназначены для облегчения реализации типов данных программными средствами. Определения в терминах ИСО/МЭК 11404 являются по своей природе семантическими и абстрактными, а определения на языке UML являются определениями конкретных структур. В настоящем стандарте акцент сделан на определения конкретных структур, поэтому определения на языке UML обладают приоритетом над определениями в терминах ИСО/МЭК 11404, которые приведены в целях преемственности с этим стандартом.
Типы данных, определенные в настоящем стандарте, представляют собой реализацию спецификации абстрактных типов данных HL7 V3 Abstract Data Types (R2). Это означает, что можно реализовать обмен информацией, основанный на определениях этой спецификации, используя типы данных, определенные в настоящем стандарте. В приложении В показано, как эти типы данных соотносятся с типами данных, определенным в спецификации HL7 V3 Abstract Data Types (R2).
Типы данных, определенные в настоящем стандарте, не ограничены свойствами, описанными в спецификации HL7 V3 Abstract Data Types (R2), и для реализации этих типов указанная спецификация не требуется. Приведенные в ней семантические определения могут использоваться разработчиками для лучшего понимания применения этих типов данных.
6.3 Имена типов данных и повторное использование общераспространенных имен типов данных
Некоторые имена этих типов данных имеют чрезвычайное сходство с именами, определенными в других спецификациях. Например, в настоящем стандарте определен вещественный тип данных REAL, в ИСО/МЭК 11404 определен тип Real, в ядре UML тоже есть тип данных с именем Real (см. примечание 1 в В.2.7, где обсуждаются числовые типы с плавающей точкой).
В настоящем стандарте не делаются попытки переопределить или заменить вещественные типы данных, описанные в ИСО/МЭК 11404 или в языке UML. Вместо этого в нем введен новый тип данных, который представляет собой "обертку" соответствующего "примитивного" типа данных, построенную на основе функциональности этого типа и включающую его в общую базовую архитектуру.
Существует много спецификаций, языков и технологий реализации, которые определяют аналогичные типы, используя либо указанные выше "примитивные" типы, либо тип REAL, определенный в настоящем стандарте, но присваивая им различные имена, перефразируя общую тему Real, Float, Decimal или Double.
Настоящий стандарт не использует новые, ранее не употреблявшиеся имена для определенных в нем типов данных, представляющих такие базовые понятия. Вместо этого им присваиваются общераспространенные имена. Опять-таки в настоящем стандарте не делается попытка переопределить или заменить любые другие определения, используя эти имена.
Если имена типов данных, определенных в настоящем стандарте, входят в противоречие с именами, использованными в других спецификациях, то разработчикам рекомендуется использовать некоторую форму присваивания им пространства имен, например, с помощью указания префикса в виде некоторой строковой константы в случае, если среда разработки не поддерживает присваивание типам данных пространства имен.
Такой шаблон "обертки примитивного типа данных" используется для типов данных BL, ST, INT, REAL, SET, LIST и BAG, определенных в настоящем стандарте.
6.4 Отображение на настоящий стандарт типов данных
Подобно ИСО/МЭК 11404, в настоящем стандарте предполагается, что определенные в нем типы данных будут использоваться в других спецификациях. В этих спецификациях должно быть указано, каким образом реализованы типы данных и свойства, описанные в настоящем стандарте. Эти типы данных могут использовать непосредственно, отображать на другие типы или структуры данных, определенные в разных местах, либо вообще не поддерживаться преобразование данных между спецификациями.
6.5 Соответствие ИСО/МЭК 11404
Настоящий стандарт объявляет соответствие ИСО/МЭК 11404. Хотя настоящий стандарт можно считать поддерживающим все типы данных общего назначения, в действительности в нем использованы только следующие типы данных:
- boolean;
- enumerated;
- characterstring;
- integer;
- Real;
- class;
- set;
- bag;
- sequence;
- octet.
Типы данных, предназначенные для здравоохранения, представляют собой конструкции классов, построенные из этих базовых примитивных типах данных. Типы данных, предназначенные для здравоохранения, частично определены с помощью языка определения типов данных, описанного в ИСО/МЭК 11404. Поскольку в нем отсутствуют отношения генерализации/специализации, то все эти типы данных не могут быть определены на языке, описанном в ИСО/МЭК 11404, поскольку в их определениях эти отношения занимают важное место.
6.6 Ссылки на язык UML 2
В настоящем стандарте типы данных определены, используя язык UML. Все эти типы данных являются специализациями класса Classifier, определенного в этом языке, и определены или построены на следующих типах данных, включенных в ядро Kernel языка UML и определенных в спецификации языка ограничений объектов OCL 2:
- enumeration;
- boolean;
- integer;
- string;
- collection;
- sequence;
- set;
- bag.
6.7 Моделирование типов данных
6.7.1 Общие сведения
В настоящем стандарте отношения между отдельными типами данных описаны с помощью Униязыка UML версии 2. Этот способ моделирования обеспечивает следующие возможности:
- свойства, общие для группы типов данных, которые могут быть определены однократно;
- реализацию механизма, с помощью которого один специфицированный тип данных может быть заменен на другой.
6.7.2 Определения атрибутов
Если не указано иное, все атрибуты и ассоциации имеют значение по умолчанию nil.
6.7.3 Генерализация/специализация
В настоящем стандарте определен ряд представлений типов данных, предназначенных для здравоохранения, в виде классов. Для этих классов широко используются отношения генерализации/специализации. Эти отношения трактуются обычным образом, и любой экземпляр класса может быть заменен на экземпляр специализации этого класса. Однако в некоторых спецификациях, основанных на настоящем стандарте, могут накладываться дополнительные ограничения на то, какие специализации допустимы в конкретном контексте.
6.7.4 Определения перечислений
В настоящем стандарте определен ряд атрибутов, имеющих перечислимые множества допустимых значений. Каждое значение представляет определенное терминологическое понятие. В терминологиях могут быть отношения генерализации/специализации. В настоящем стандарте перечисления определяются тремя способами:
- список кодов в форме перечислений, определяемых в соответствии с ИСО/МЭК 11404;
- список кодов в форме перечислений, определены в соответствии с языком UML;
- таблица, в которой перечисления определяются в текстовом виде.
Такая таблица имеет четыре столбца: Level (уровень), Code (код), Title (описание) и Definition (определение), описание которых приведено в таблице 1.
Таблица 1 - Структура таблицы перечисления
Вид строки | Описание |
Уровень | Уровень понятия в терминологической иерархии. |
Код | Код, представляющий понятие. |
Описание | Краткое человекочитаемое описание понятия |
Определение | Краткое определение назначения понятия |
Иерархия внутри перечисления является важной частью спецификации. Хотя в ИСО/МЭК 11404 и в языке UML перечисления определены как линейные списки, каждый элемент обработки информации, объявляющий о непосредственном или косвенном соответствии настоящему стандарту, должен принимать во внимание отношение иерархии при оценке значения (смысла) перечисления. Кроме того, при определении результата некоторых операций настоящий стандарт время от времени использует отношения, определенные в табличных описаниях перечислений.
За исключением перечисления типов частей адреса AddressPartType, иерархии отражают отношения генерализации/специализации (известного также как категоризация). В этих иерархиях дочерние коды имеют более специальное значение по отношению к родительскому. Перечисление AddressPartType по своей природе является композицией; в нем дочерние коды описывают части понятия, представленного родительским кодом.
Для примера в таблице 2 приведено подмножество определения перечисления NullFlavor (причина пустоты).
Таблица 2 - Перечисление NullFlavor, ОИД![]() : 2.16.840.1.113883.5.1008 (подмножество)
: 2.16.840.1.113883.5.1008 (подмножество)
_______________
![]() ОИД = объектный идентификатор.
ОИД = объектный идентификатор.
Уровень | Код | Описание | Определение |
1 | NI | Nolnformation | Отсутствует какая бы то ни было информация, которую можно вывести из данного исключительного значения. Это наиболее общее исключительное значение, оно также использовано по умолчанию |
2 | UNK | unknown | Правильное значение имеется, но оно не известно |
3 | ASKU | asked but unknown | Информация запрошена, но ответ не получен (например, пациенту задали вопрос, а ответ он не знает) |
4 | NAV | temporarily unavailable | Информация в данное время недоступна, но может стать доступной позже |
3 | NASK | not asked | Эта информация не запрашивалась (например, пациенту вопрос не задавался) |
2 | MSK | masked | Информация об этом элементе имеется, но не предоставлена отправителем по причине безопасности, конфиденциальности и т.д. Для получения доступа к этой информации могут существовать альтернативные механизмы. |
2 | NA | not applicable | В данном контексте правильного значения не существует (например, последний менструальный период у мужчины) |
В этой таблице все коды понятий после NI указаны с отступом и имеют более высокий уровень, т.е. эти понятия являются специализациями понятия с кодом NI. Понятия с кодами ASKU, NAV и MASK являются специализациями понятия с кодом UNK, а понятия с кодами UNK, MSK и NA являются братскими и представляют собой не что иное, как специализации понятия с кодом NI. Соответственно, перечисляемое значение ASKU подразумевает, что может быть использовано также перечисляемое значение UNK.
Если иное не указано, то все перечисления, приведенные в настоящем стандарте, управляются организацией HL7, которая на регулярной основе публикует обновления соответствующих таблиц. Смысл значений, приведенных в настоящем стандарте, неизменен, хотя в будущих редакциях они могут быть запрещены. Когда эти обновленные таблицы публикуются организацией HL7 или ISO, то вновь введенные значения перечислений могут быть предварительно согласованы в партнерском соглашении до выпуска новой редакции настоящего стандарта.
ОИД системы кодирования, присвоенный ей организацией HL7, публикуется для ссылки и для облегчения передачи этих перечисляемых значений в терминологические подсистемы, которые могут использовать ОИД в целях однозначной ссылки на код.
6.7.5 Строковые типы данных и кодирование символов
В настоящем стандарте даются ссылки как на тип данных characterstring, определенный в ИСО/МЭК 11404, так и на тип String, определенный в ядре языка UML. Для целей настоящего стандарта оба этих типа определяют одну и ту же функциональность, а именно: неизменную последовательность известной длины, состоящую из нуля или большего числа логических символов. В тексте этот тип данных далее обозначается просто как String.
Примечания
1 Как ИСО/МЭК 11404, так и ядро языка UML определяют дополнительные характеристические операции, которые могут быть полезны при реализации типа данных и считаться применимыми, но не представляют непосредственного интереса для настоящего стандарта.
2 В настоящем стандарте определен также тип данных ST, представляющий собой оболочку типа данных String и предлагающий дополнительную функциональность того, как понятие неизменной последовательности символов укладывается в общий комплекс типов данных, предназначенный для здравоохранения и оперирующий ассоциированными понятиями неопределенности, ненадежности и соответствия.
Тип данных String содержит последовательность логических символов, отличающуюся от последовательности байтов, кодирующих последовательность логических символов.
Примечание 3 - Разработчики должны аккуратно учитывать различие между этими двумя понятиями при реализации этих типов данных.
По умолчанию тип данных String содержит символы в кодировке Unicode. Рекомендуется, чтобы все элементы обработки информации, объявляющие непосредственное или косвенное соответствие настоящему стандарту, указывали, что набор символов Unicode используется во всех строковых типах данных, взятых из настоящего стандарта.
Однако существует несколько наборов символов, которые недостаточно хорошо отображаются на Unicode. В связи с этим несколько стран или территорий юрисдикции могут предписывать другие наборы символов, отличающиеся от Unicode. В этих случаях рекомендуется, чтобы стандарты и спецификации, объявляющие непосредственное или косвенное соответствие настоящему стандарту, обеспечивали использование наборов символов, отличающихся от Unicode, и содержали явное указание, какие именно наборы символов поддерживаются и как они представлены.
Примечание 4 - Естественно, использование наборов символов, отличающихся от Unicode, приводит к росту затрат на реализацию. Поэтому на территориях юрисдикции, выбирающих использование наборов символов, отличающихся от Unicode, должны полностью учесть это обстоятельство.
Набор символов, применяемый в конкретной среде реализации, будь то Unicode или какой-либо другой, будет именоваться в настоящем стандарте как "строковый набор символов".
Вне зависимости от того, используется в качестве строкового набора символов Unicode или иной набор, при кодировании примитивного строкового типа в определенном наборе символов могут использоваться управляющие байты, изменяющие интерпретацию текста. Предполагается, что любая операция со строковым типом учитывает такую возможность. Но поскольку все операции, описанные в настоящем стандарте, применены к логической последовательности символов, эти вопросы далее не обсуждаются.
6.7.6 Атрибуты тонкости
В дополнение к базовым типам данных настоящий стандарт определяет также ряд атрибутов тонкостей типов данных, которые сами по себе не являются типами данных и не определяются ни как классы UML, ни как типы на языке XML-схем. Вместо этого атрибуты тонкости описывают общие шаблоны ограничений типов данных. Поэтому они не могут быть представлены в виде новых атрибутов, новых кодов, значений по умолчанию или других вновь определяемых элементов. Они могут только описывать правила того, какие существующие свойства класса могут быть использованы и каким образом.
Поскольку атрибуты тонкости типов данных не могут представлять новые свойства или новое значение и сами по себе не существуют как независимые классы, то для правильной обработки информации элементы обработки информации не должны учитывать ее атрибуты тонкости. Поэтому любой элемент, объявляющий непосредственное или косвенное соответствие настоящему стандарту, может определять атрибуты тонкости типов данных или ссылаться на определения атрибутов тонкостей, данные другим уполномоченным органом, при условии выполнения правил именования, принятых в стандарте, а именно:
- имена должны состоять из последовательности допустимых символов, то есть букв, цифр, подчеркиваний и точек; непробельные символы Unicode могут использоваться по усмотрению элемента обработки информации;
- имена должны начинаться с имени типа, от которого они произведены, после которого следуют точка, пространство имен, другая точка, а за ними любые дополнительные допустимые символы;
- пространства имен используются для предотвращения конфликта между именами атрибутов тонкостей, описанных разными источниками; пространство имен должно представлять собой или код страны согласно ИСО 3166-1, или допустимый идентификатор территории применения (realm), определенный организацией HL7, или DNS-имя.
Примеры
TS.CA.BIRTH | Правила для дат рождения, опубликованные соответствующим уполномоченным органом Канады. |
TS.NPFIT.NHS_NUMBER | Атрибут тонкости идентификатора пациента (NHS Number flavor, фиксированный корень имени), опубликованный в документации по программе NPFIT в Великобритании. |
ED.AU.KESTRAL.DOCUMENT | Правила формата документов, допустимого для австралийской фирмы Kestral. |
Для атрибутов тонкостей типов данных, определенных в настоящем стандарте, пространство имен указывать не требуется.
Приложения не должны отвергать экземпляр типа данных на том основании, что в атрибуте flavorld указан идентификатор атрибута тонкости, неизвестный приложению. Приложения могут отвергать экземпляр типа данных, который ссылается на атрибут тонкости, не относящийся к этому типу, но не обязаны это делать.
Атрибуты тонкости, определенные в настоящем стандарте, не обязаны быть реализованными элементами обработки информации, объявляющими непосредственное или косвенное соответствие настоящему стандарту, и использоваться в соответствии с этими элементами.
6.7.7 Примеры
Для большинства типов данных приведены примеры, предназначенные для иллюстрации различных аспектов, связанных с использование этих типов.
Все примеры приведены в виде XML-фрагментов в соответствии с формой, документированной в приложении А. Примеры составлены в предположении, что содержащий их документ или элемент XML использует набор символов UTF-8. Для явного указания типа данных в большинстве примеров использована спецификация типа xsi:type, но это не требуется, если тип данных полностью определен контекстом использования или XML-схемой.
При обсуждении примеров могут даваться ссылки на содержание, опубликованное не ИСО или HL7, а другими разработчиками стандартов. Это содержание не является нормативной частью настоящего стандарта.
7 Типы данных
7.1 Общие свойства
7.1.1 Неизменность
Эти типы данных концептуально неизменны. Для типов данных не вводится понятие жизненного цикла, у них нет операций, позволяющих изменить существующий тип данных. Однако в настоящем стандарте типы данных определены как классы с атрибутами, что позволяет значению типа данных изменяться после его создания.
Хотя это может оказаться полезным для реализации, в намерение разработчиков настоящего стандарта не входило определение типов данных, допускающих изменение семантики. В спецификациях, использующих типы данных, определенные в настоящем стандарте, следует исходить из постулата неизменности типов данных. В частности, разработчики должны усердно предотвращать эффекты совмещения имен, которые могут возникать в случаях, когда свойствам типа данных разрешается изменяться после того, как этот тип данных введен в действие.
7.1.2 Равенство
Существуют два аспекта равенства, а именно: "являются ли эти два значения данных одним и тем же экземпляром?" и "представляют ли эти два значения данных одно и то же семантическое понятие?".
Для отражения этих двух аспектов равенства в языках UML/OCL использовано два свойства. Первое обозначается как "=" и означает, что эти два значения являются одним и тем же экземпляром, а второе обозначается "equals" и означает, что эти типы представляют одно и то же понятие. Для примитивных типов данных языка OCL, например integer, эти два свойства имеют одно и то же значение. Для классов языка UML значения этих свойств могут различаться.
В настоящем стандарте для каждого типа данных приведены критерии равенства. Они определяют вторую форму равенства, а именно представляют ли эти два значения данных одно и то же понятие? Эти определения равенства тщательно сконструированы, чтобы удовлетворять критерию, согласно которому операция равенства должна быть рефлексивной, симметричной и транзитивной:
рефлексивность: | "х equals х" должно быть истинно; |
симметричность: | если "х equals у" истинно, то "у equals х" должно быть истинно; |
транзитивность: | если "х equals у" истинно и "у equals z" истинно, то "х equals z" должно быть истинно. |
Поскольку эта форма равенства носит сугубо семантический характер, то определения равенства могут зависеть от типа данных и установление равенства может оказаться непростым. Элементы обработки информации, объявляющие непосредственное соответствие настоящему стандарту, должны удовлетворять этим определениям равенства. Элементы обработки информации, объявляющие косвенное соответствие настоящему стандарту, должны точно указывать, что определения равенства применимы.
Атрибуты тонкости типов данных не влияют на определение равенства.
7.1.3 История и журнал изменений
Базовый тип данных HXIT определяет свойства, используемые для указания интервала времени validTime, в течение которого значение было, есть или будет действительно, а также для указания идентификации события, ассоциированного с изменениями, известной как контрольная информация.
Свойство validTime используется не для регистрации изменений, а для отслеживания того, когда конкретная система ассоциировала конкретную версию данных с понятием; оно позволяет делать утверждения о периоде времени, в течение которого элемент данных был правильным описанием понятия. Например, во многих странах лицо может изменить свою фамилию при замужестве или иными законными способами, поэтому конкретная фамилия ассоциируется с лицом в течение ограниченного времени. Аналогично, адреса и другая контактная информация лица могут изменяться при его переезде в другое место.
Контрольная информация представляет собой идентификатор некоторого события, произошедшего в информационной системе, ассоциируемый с контрольной информацией об изменении в системе этого элемента данных. Эта информация специфично связана с привязкой в системах значения этого элемента данных к понятию, которое его описывает. Контрольная информация может использоваться для ведения журнала изменений значений при многократной передаче из одной системы в другую. Дополнительные детали см. в 7.3.2.
Различные спецификации, использующие настоящий стандарт, могут предлагать альтернативные способы представления этой истории и состава журнала изменений, особенно второй части, относящейся к журналу изменений. В таких случаях спецификации должны содержать указание, обычно в своем объявлении соответствия, каким образом эта информация обработана и потенциально отображена на свойства, определенные в настоящем стандарте.
Типы данных неизменны - их значение не может измениться. Понятия срока действия и контрольной информации не применимы к типам данных. Поэтому в тех случаях, когда тип данных повторно использована как тип атрибута другого типа данных, инвариантные выражения будут указывать, что атрибуты срока действия и контрольной информации должны быть пустыми.
7.1.4 Пустые значения и атрибут причины пустоты nullFlavor
В описании базового типа ANY введено понятие, называемое nullFlavor (атрибут тонкости, описывающий причину пустоты). Хотя это понятие имеет некоторую связь с пустым значением null, определенным в языках UML и OCL, это не одно и то же, и для правильной реализации настоящего стандарта необходимо понимать связь и различия между этими двумя понятиями.
Любой экземпляр класса, определенного в настоящем стандарте, может быть пустым. Это соответствует понятию null, определенному в языках UML и OCL. Пустой экземпляр представляет собой экземпляр типа OclVoid и соответствует всем типам данных. Он не несет никакой другой информации кроме той, что факт отсутствует. Для задания ограничений на использование этой формы пустоты в атрибутах типов данных, определенных в настоящем стандарте, использованы операции ocllsDefined и ocllsUndefined языка OCL.
С другой стороны, может быть создан экземпляр класса, и его причине пустоты nullFlavor может быть присвоено одной из значений, входящих в перечисление NullFlavor.
В этом случае значение класса называется исключительным типа nullFlavor. Это означает, что такое значение представляет собой исключение из нормального домена значений этого типа. Но из этого не следует, что экземпляр класса, представляющий исключение, не связан правилами, определенными в настоящем стандарте; он тем не менее должен удовлетворять описанным в стандарте инвариантам. Однако для исключительных значений многие из этих правил отличаются, поскольку эти значения представляют собой семантическое исключение из нормальных данных. Все исключительные значения должны иметь причину пустоты nullFlavor, которая предоставляет более точную информацию о том, почему значение является исключением из правил. Противоположностью исключительного значения является правильное значение, то есть значение, у которого отсутствует причина пустоты nullFlavor.
Поскольку для наличия причины пустоты nullFlavor экземпляр типа данных должен быть создан, его другим атрибутам могут быть присвоены значения. Тем самым этот экземпляр отличается от пустого объекта null, определенного в языках UML/OCL. Этот объект не существует и не может иметь непустые атрибуты. Если причина пустоты nullFlavor присутствует, то другим атрибутам могут быть присвоены значения, однако при этом не требуется, чтобы элемент обработки информации использовал какое-либо из этих значений, за исключением следующих случаев, которые следует правильно понимать в ситуации, когда они применимы:
- значение ОТН из перечисления NullFlavor для кодируемого типа данных CD;
- значения NINF и PINF для типа данных CD из перечисления NullFlavor соответственно для нижней и верхней границы интервала;
- значение ОТН из перечисления NullFlavor для типа данных идентификатора II, у которого нет корня root, но есть расширение extension.
Перечисление NullFlavor описано в таблице 3.
Таблица 3 - Перечисление NullFlavor, ОИД: 2.16.840.1.113883.5.1008
Уровень | Код | Описание | Определение |
1 | NI | Nolnformation | Отсутствует какая бы то ни было информация, которую можно вывести из данного исключительного значения. Это наиболее общее исключительное значение, оно также используется по умолчанию |
2 | INV | Invalid | Значение, представленное в экземпляре, не принадлежит ограниченному домену значений переменной |
3 | ОТН | Other | Фактическое значение не является элементом ограниченного домена значений переменной (например, в используемой системе кодирования данное понятие отсутствует) |
4 | PINF | Positive infinity | Положительная бесконечность чисел |
4 | NINF | Negative infinity | Отрицательная бесконечность чисел |
3 | UNC | Unencoded | Попытки правильной кодировки информации не предпринимались, но некодированное исходное значение представлено (обычно в атрибуте originalText) |
3 | DER | Derived | Фактическое значение может существовать, но оно должно быть произведено из предоставленной информации (обычно выражение задается непосредственно) |
2 | UNK | Unknown | Правильное значение имеется, но оно неизвестно |
3 | ASKU | Asked but unknown | Информация запрошена, но ответ не получен (например, пациенту задали вопрос, а ответ он не знает) |
4 | NAV | Temporarily unavailable | Информация в данное время недоступна, но может стать доступной позже |
3 | NASK | Not asked | Эта информация не запрашивалась (например, пациенту вопрос не задавался) |
3 | QS | Sufficient quantity | Конкретная величина неизвестна, но известно, что она ненулевая и не указана, поскольку образована из большого объема вещества. "Добавить 10 мг ингредиента X, 50 мг ингредиента Y и достаточное количество воды до 100 мл". Эта причина пустоты может использоваться для представления количества воды |
3 | TRC | Trace | Содержание отлично от нуля, но слишком мало, чтобы можно было узнать его количество |
2 | MSK | Masked | Информация об этом элементе имеется, но не предоставлена отправителем по причине безопасности, конфиденциальности и т.д. Для получения доступа к этой информации могут существовать альтернативные механизмы. |
2 | NA | not applicable | В данном контексте правильного значения не существует (например, последний менструальный период у мужчины) |
В стандарте ИСО/МЭК 11404 определено понятие сигнального значения (sentinel value), представляющего собой значение в пространстве значений типа данных, к которому применимы не все характеристические операции этого типа. Хотя между значениями nullFlavors и sentinel существуют определенные концептуальные сходства, экземпляры типа данных ANY, у которых заданы причины пустоты nullFlavor, не являются сигнальными значениями. Характеристические функции к этим экземплярам применимы, однако результатом их применения будет некоторая разновидность (flavor) пустого значения null. Вследствие сходства с поведением значения null, определенного в языке OCL, данное свойство получило имя "nullFlavor".
Если специально не оговорено, все операции, определенные в настоящем стандарте, имеют одинаковое поведение, а именно:
- если операция выполнена над пустым значением null, определенным в языках UML/OCL, то результатом является null;
- если операция выполнена над значением, имеющими причину пустоты nullFlavor, то имеет место следующее:
- если у операции нет параметров, то она возвращает значение nullFlavor. Обычно этим значением будет NA (не применимо), но в зависимости от семантики причины пустоты nullFlavor могут возвращаться и другие значения. При выполнении операций над значениями, имеющими причину пустоты nullFlavor, следует рассматривать семантический смысл этого атрибута тонкости;
- если у операции есть параметры и какой-либо из них имеет значение null, определенное в языках UML/OCL, то результатом является null;
- если в выполнение операции вовлечено значение null или значение, имеющее причину пустоты nullFlavor, то результирующим значением должно быть null или значение, имеющее причину пустоты nullFlavor. Из этого правила могут быть исключения, если семантика типов данных и причины пустоты nullFlavor не требует иного. В настоящем стандарте описано несколько исключений для специфичных операций;
- если операция выполняется над правильным значением:
- если у операции есть параметры и какой-либо из них имеет значение null, определенное в языках UML/OCL, то результатом является null;
- если в выполнение операции вовлечено значение null или значение, имеющее причину пустоты nullFlavor, то результирующим значением должно быть null или значение, имеющее причину пустоты nullFlavor. Из этого правила могут быть исключения, если семантика типов данных и причины пустоты nullFlavor не требует иного. В настоящем стандарте описано несколько исключений для специфичных операций;
- в остальных случаях операция выполняется, как предписано.
Некоторые специфичные операции отклоняются от этих правил. Эти отклонения документируют для каждой такой операции.
Один из особых случаев возникает при сравнении различных значений, имеющих причину пустоты nullFlavor, на предмет равенства. Два значения, у которых причина пустоты nullFlavor имеет значение NA (не применимо), считаются равными. В то же время два значения, у которых причина пустоты имеет значение NINF (отрицательная бесконечность), не равны, равно как и два значения, у которых причина пустоты имеет значение PINF (положительная бесконечность), поскольку фактическое значение неизвестно. Очевидно также, что значение, у которого причина пустоты имеет значение NINF (отрицательная бесконечность), не равно значению, у которого причина пустоты имеет значение PINF. В остальных вариантах обычно небезопасно возвращать что-либо, кроме значения с причиной пустоты nullFlavor (обычно NI - нет информации).
Значение любого типа, имеющее причину пустоты nullFlavor, равную NI, у которого все другие атрибуты имеют пустое значение null или которое удовлетворяет данному условию рекурсивно, семантически эквивалентно значению null, определенному в языках UML/OCL, и при необходимости эти формы могут быть взаимно преобразованы. Большинство простых атрибутов объявлено, используя типы данных языков UML или OCL, например, строковый тип String, и при необходимости они могут быть преобразованы в соответствующие комплексные эквиваленты, например ST, у которых причина пустоты nullFlavor будет иметь значение NI.
Поскольку атрибут может быть или пустым, или обладать причиной пустоты nullFlavor, многие инварианты приобретают форму (x.ocllsDefined and x.isNotNull) implies {условие}. Для некоторых инвариантов такое правило не является необходимым, поскольку из промежуточного результата null (которому равно значение x.isNotNull, если х равен null) следует, что окончательный результат также null, и такой инвариант благополучно не будет выполнен, но в других случаях должна осуществляться защита от пустого значения null, чтобы во всех случаях можно было получить правильный результат.
Понятие nullFlavor представляет собой общую основу для обработки неполных данных, которые нередко встречаются при сборе, обработке и анализе информации, используемой в здравоохранении. Это понятие может также играть особую роль при объявлении соответствия в спецификациях, использующих такие типы данных.
Не все значения причины пустоты nullFlavor могут использоваться с любыми типами данных. Значения PINF и NINF могут использоваться только со специфичными типами (INT, REAL, PQ и TS). Значение UNC может использоваться только в типах данных, имеющих атрибут исходного текста originalText (CD, QTY, QSET и их специализации). Значения QS и TRC могут использоваться только в типе данных PQ.
Два значения причины пустоты ОТН и INV, а также другие их специализации отражают различие между действительным значением и значением, представленным в экземпляре. Некоторые из типов значений могут использоваться в качестве представления значения, которое требует последующего преобразования, генерирующего действительное значение. Например, может быть предоставлено выражение, обеспечивающее генерацию фактического значения, принадлежащего требуемому домену значений экземпляра. Другим примером служит некодированное значение типа CD, у которого задан только атрибут originalText. При значениях причины пустоты INV, DER и UNC существует возможность, что некоторое преобразование, основанное на дополнительной информации или дополнительном знании, может сгенерировать правильное значение. А значение причины пустоты ОТН и его специализации представляют собой утверждение, что никакого лучшего значения, скорее всего, не существует. Отсюда возникают вопросы доверия - насколько надежен источник, утверждающий, что лучшей информации нет, насколько надежна обработка, доверяющая такому источнику? Однако эти вопросы не разрешимы. Поэтому различие не должно приниматься как абсолютное, его надо трактовать как заявление о намерении со стороны источника.
Хотя значение причины пустоты INV и его специализации представляют исключительные значения в контексте их использования, оно является исключительным только в параметрах, определенных настоящим стандартом. Фактические значения всегда должны соответствовать правилам, определенным настоящим стандартом.
Значение причины пустоты DER должно использоваться только в том случае, когда из контекста, в котором оно применяется, точно известно, как фактическое значение может быть получено из представленной информации. В настоящем стандарте предусмотрено свойство QTY.expression (см. 7.8.2.3.1). В других элементах обработки информации могут быть сделаны иные описания использования значения DER, включенные в их объявления соответствия.
Примечание - Чаще всего правильным значением причины пустоты будет NI, и на разработчиков не возлагается дополнительная обязанность выбора или сохранения правильного значения причины пустоты. Во всех случаях сомнения, какое значение причины пустоты применимо за пределами тех технических требований, которые точно прописаны в настоящем стандарте в части использования значений NA, INV, DER, ОТН, PINF и NINF, разработчики вполне безопасно могут использовать значение NI. В частности, если пользователь не ввел значение в поле ввода процедуры сбора данных или данные отсутствуют по какой-то неизвестной причине, значение NI может оказаться наиболее подходящим.
В таблице 4 приведены примеры выбора значений причин пустоты.
Таблица 4 - Примеры выбора значений причин пустоты
Сценарий | Выбранное значение причины пустоты |
Пользователь не ввел значение в поле ввода экранной формы | NI |
Источник не сконфигурирован для кодирования текстового значения в требуемой системе кодирования (codeSystem) | UNC |
Источник не способен закодировать данное введенное текстовое значение в требуемой системе кодирования, поскольку в ней нет кодов, эквивалентных этому значению | ОТН |
Пациент в бессознательном состоянии и не может назвать свою фамилию | NAV |
Система не поддерживает данный элемент | NI |
Дозировка не указана, но предоставлено выражение, с помощью которого система-получатель может вычислить правильную дозировку по весу пациента | INV |
У пациента нет адреса - нет постоянного места жительства или бездомный | NA |
Отчет о длительности продолжающегося побочного действия с помощью типа данных IVL<TS> | IVL.high = NA, поскольку действие продолжается - понятие даты завершения неприменимо |
Отчет о длительности побочного действия с помощью типа данных IVL<TS>, если неизвестно, завершилась ли она | IVL.high = UNK - дата завершения неизвестна |
Система-источник возвращает персональные данные пациента, но в соответствии с примененной политикой безопасности/конфиденциальности исключает из них адрес. | MSK |
7.1.5 Соответствие
Соответствие в том виде, как оно описано в разделе 5, акцентировано на соответствии элементов обработки информации настоящему стандарту. Но есть и другой аспект, который также нередко называют соответствием, который акцентирован на правилах, применяемых к типам данных элементами обработки информации, например другими стандартами, при использовании этих типов.
Любой элемент обработки информации, использующий эти типы данных, может ограничить их применение правилами, представленными на некотором человеческом языке или на некотором формальном машинно-обрабатываемом языке, например, OCL. Кроме того, в настоящем стандарте описаны два дополнительных средства, с помощью которых можно ограничить возможные значения типов данных, а именно "обязательность" (mandatory) и "кратность" (cardinality).
Любому внешнему атрибуту, присвоенному типу данных, описанному в настоящем стандарте, может быть также присвоен номинальный признак "обязателен" с булевским значением true. Если в контексте использования этому признаку присвоено значение true, то экземпляр типа данных должен иметь непустое допустимое значение, не иметь причины пустоты nullFlavor, соответствовать всем ограничениям, предписанным настоящим стандартом и дополнительным ограничениям на домен значений, описанным в модели. Если этому признаку не присвоено значение true и экземпляр типа данных не удовлетворяет ограничениям, описанным в модели ограничений, то этот экземпляр либо должен быть маркирован, используя некоторую форму причины пустоты nullFlavor (хотя другая информация тем не менее может быть указана), либо должен быть полностью опущен. В последнем случае применяется значение причины пустоты по умолчанию (обычно NI).
В контексте использования может также задаваться кратность атрибута. Кратность состоит из минимального значения, выраженного целым числом, и максимального значения, выраженного целым числом или символом "*". Кратность обычно представляется в виде "[минимальное значение]. [максимальное значение]", например, 0..1 или [1 ..*]. Смысловые значения кратности у атрибутов, основанных на коллекциях, и других атрибутов отличаются.
Для атрибутов, имеющих тип коллекций (<dtref ref="dt-COLL"/> и его специализации), кратность указывает, сколько элементов может содержать коллекция. Максимальное значение кратности * означает, что число элементов коллекции не ограничено.
Примечания
1 Отсюда не следует, что элементы обработки информации должны оперировать бесконечно большими коллекциями данных, просто в самой спецификации не накладывается никаких ограничений на размер коллекции. Минимальное значение кратности указывает, сколько элементов должно быть в коллекции как минимум.
2 В случае коллекции, имеющей атрибут "обязательна", коллекция должна содержать не менее одного непустого элемента (то есть не равного null и не имеющего какой-либо причины пустоты nullFlavor).
Другим атрибутам могут быть присвоены только значения кратности 0..0, 0..1 или 1 ..1. Кратность 0 означает, что атрибут не должен быть представлен в экземпляре и неявно имеет значение причины пустоты NI. Кратность 1 означает, что атрибут имеет значение, хотя оно может иметь некоторое значение пустоты, но только в том случае, если этот атрибут не объявлен обязательным.
Обязательный атрибут должен иметь минимальное значение кратности 1 или более.
Примечание - Такое использование кратности несколько отличается от стандартного описания кратности атрибутов в языке UML. Если в этом языке атрибуту присвоены тип DSET(CS) и кратность 2..3, то это означает, что должно быть два или три множества значений типа данных. Эти варианты использования кратности не являются несовместимыми, оба могут использоваться элементами обработки информации, объявляющими непосредственное или косвенное соответствие. Из документации должно точно следовать, какой именно из этих вариантов использован.
Рисунок 1 - Модель верхнего уровня
|
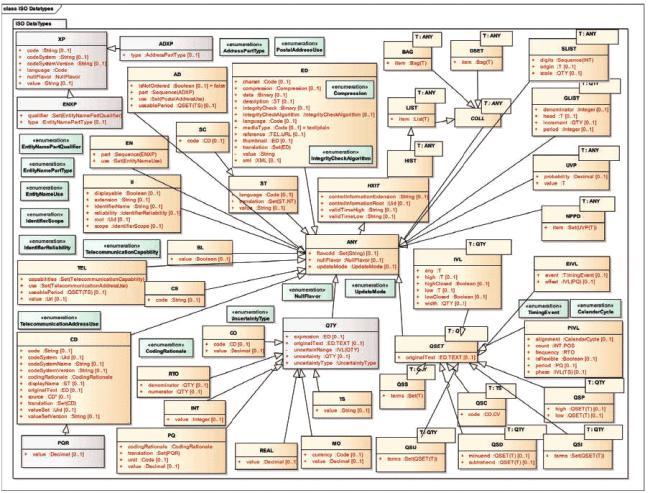
Рисунок 1 - Модель верхнего уровня
7.2 Модель верхнего уровня
Для удобства и последующих ссылок на рисунке 1 в виде диаграммы классов UML приведено обзорное представление типов данных, определенных в настоящем стандарте.
7.3 Базовые типы данных
7.3.1 Введение
Базовые типы данных обеспечивают инфраструктурную поддержку специфичных типов данных, определенных в следующих подразделах (см. рисунок 2).
Рисунок 2 - Базовые типы данных
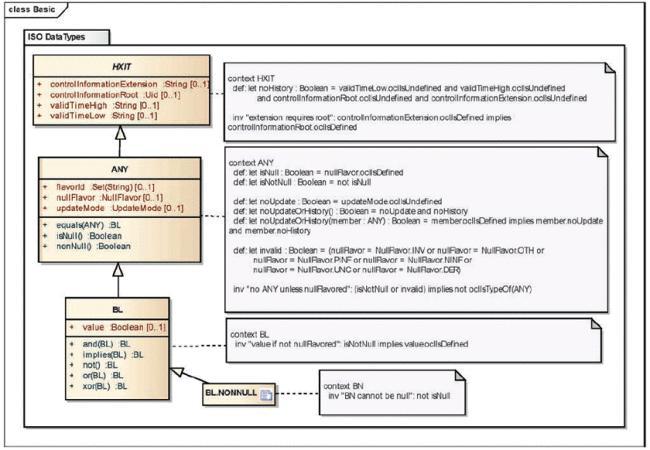
Рисунок 2 - Базовые типы данных
7.3.2 Тип данных HXIT
7.3.2.1 Описание
Абстрактный и частный (private) - этот тип данных не должен быть использован вне типов данных, определенных в настоящем стандарте.
Информация об истории значения: срок действия и ссылка на идентифицируемое событие, которое ввело данное значение в действие.
Вследствие способа определения типов данных ряду их атрибутов присвоены типы данных, произведенные от HXIT. В этих случаях атрибуты HXIT ограничены пустыми значениями. Единственным случаем, когда атрибуты HXIT разрешены в типе данных, служит элемент коллекции (DSET, LIST, BAG, HIST).
В спецификациях, оперирующих этими типами, использование этих атрибутов обычно является предметом дополнительных ограничений.
7.3.2.2 Синтаксис ИСО/МЭК 11404
type HXIT = class (
validTimeLow : characterstring,
validTimeHigh : characterstring,
controllnformationRoot : characterstring,
controllnformationExtension : characterstring
)
7.3.2.3 Атрибуты
7.3.2.3.1 validTimeLow: String : момент времени, когда данная информация стала или станет действительной.
Это не момент времени, когда какая-либо система впервые получила данное значение, а то время, когда соответствующая информация стала правильной (например, дата, когда пациент поменял свою фамилию).
7.3.2.3.2 validTimeHigh: String : момент времени, когда данная информация перестала или перестанет быть правильной.
Оба атрибута validTimeLow и validTimeHigh должны быть допустимыми штампами времени, представленными в формате, описанном в 7.8.10.3.1 (значение TS.value).
7.3.2.3.3 controllnformationRoot: Uid: корень идентификатора события, связанного с присвоением типу данных его указанного значения.
7.3.2.3.4 controllnformationExtension : String: расширение идентификатора события, связанного с присвоением типу данных его указанного значения.
В сочетании корень и расширение идентифицируют конкретную запись о событии реального мира, которая может предоставить дополнительную информацию о значении, например, кто выполнил изменение, почему оно произошло, какая система инициировала изменение. Эта информация существует, поскольку иногда она требуется, но значение представлено во внешнем контексте, не содержащем подходящую связь с контрольной информацией о самом значении. Запись не обязана быть непосредственно доступной или легко доступной. В объявлениях соответствия могут быть приведены дополнительные сведения об этих двух свойствах или о том, как рекомендуется разрешать такую ссылку.
7.3.2.4 Равенство
Поскольку тип данных HXIT является абстрактным и частным, равенство его экземпляров не определено. Атрибуты класса HXIT (validTimeLow, validTimeHigh, controllnformationRoot, controllnformationExtension) никогда не участвуют в определении равенства специализаций этого класса.
7.3.2.5 Инварианты
Если атрибут controllnformationExtension присутствует, то должен присутствовать и атрибут ControllnformationRoot.
Представление инвариантов на языке OCL:
def: let noHistory : Boolean =
validTimeLow. oclIsUndefined and
validTimeHigh. oclIsUndefined and
controllnformationRoot. oclIsUndefined and
controllnformationExtension. oclIsUndefined
inv "extension requires root":
controllnformationExtension.оclIsDefined implies
controllnformationRoot.oclIsDefined
7.3.2.6 Пример
<example
xsi:type="ST" value="Это некоторое содержание"
validTimeLow="200506011000" validTimeHigh="200507031500"
controllnformationRoot="1.2.3.4.5.6">
</example>
В этом примере значение атрибута "Это некоторое содержание" было действительно с 10:00 1 июня по 15:00 3 июля 2005 года. Значение "Это некоторое содержание" было присвоено в связи с событием, идентифицируемым ОИД 1.2.3.4.5.6. Некоторая где-то находящаяся информационная система (определение ее местонахождения должно быть описано в применимом профиле соответствия) способна преобразовать этот ОИД в ссылку, которая может использоваться для идентификации пользователя, осуществившего ввод данного значения в систему.
7.3.3 Тип данных ANY
7.3.3.1 Описание
Специализация типа данных HXIT
Определяет базовые свойства каждого значения данных. Концептуально представляет собой абстрактный тип, то есть никакое правильное значение не может быть только значением данных, не принадлежащим ни к какому конкретному типу. Каждый общедоступный тип данных является специализацией этого общего абстрактного типа данных.
Однако исключительные значения (имеющие причину пустоты nullFlavor) могут иметь тип данных ANY, кроме исключительных значений, у которых подразумевается причина пустоты INV, поскольку для них тип данных должен быть значащим. Следует обратить внимание на то, что не все значения причины пустоты допустимы в типе данных ANY (дополнительные детали см. в 7.1.4).
7.3.3.2 Синтаксис ИСО/МЭК 11404
type ANY = class (
validTimeLow : characterstring,
validTimeHigh : characterstring,
controllnformationRoot : characterstring,
controllnformationExtension : characterstring,
nullFlavor : NullFlavor,
updateMode : UpdateMode,
flavorld : Set (characterstring)
)
Правильное использование всех трех атрибутов типа данных ANY (дополняющих четыре свойства, унаследованные от типа данных HXIT) связано исключительно со спецификацией, использующей типы данных. Обычно в такой спецификации требуется описать специальные способы управления их использованием. В элементах обработки информации, объявляющих непосредственное или косвенное соответствие, должно быть точно указано, как контролируется использование этих трех атрибутов.
7.3.3.3 Атрибуты
7.3.3.3.1 nullFlavor: NullFlavor: если значение не является правильным, в этом атрибуте указана причина.
Хотя это понятие имеет некоторую связь с пустым значением null, определенным в языках UML и OCL, это не одно и то же, и для правильной реализации настоящего стандарта необходимо понимать связь и различия между этими двумя понятиями. Детальное обсуждение см. в 7.1.4.
Примечание - Понятие причины пустоты nullFlavor включает в себя понятие пустого значения null, определенного в языке UML, а также потенциально полностью заполненные экземпляры, не соответствующие требованиям, предъявляемым к экземпляру (называемые также "исключительными экземплярами").
Как непустые значения (nonNull), так и значения, имеющие причину пустоты nullFlavor, всегда должны быть действительными в соответствии с правилами, приведенными в настоящем стандарте.
Если этому атрибуту присваивается значение, то оно должно быть взято из системы кодирования HL7 NullFlavor. Текущие значения приведены в таблице 5.
Таблица 5 - Перечисление NullFlavor, ОИД: 2.16.840.1.113883.5.1008
Уровень | Код | Описание | Определение |
1 | NI | Nolnformation | Отсутствует какая бы то ни было информация, которую можно вывести из данного исключительного значения. Это наиболее общее исключительное значение, оно также используется по умолчанию |
2 | INV | Invalid | Значение, представленное в экземпляре, не принадлежит ограниченному домену значений переменной |
3 | OTH | Other | Фактическое значение не является элементом ограниченного домена значений переменной (например, в используемой системе кодирования данное понятие отсутствует) |
4 | PINF | Positive infinity | Положительная бесконечность чисел |
4 | NINF | Negative infinity | Отрицательная бесконечность чисел |
3 | UNC | Unencoded | Попытки правильной кодировки информации не предпринимались, но некодированное исходное значение представлено (обычно в атрибуте originalText) |
3 | DER | Derived | Фактическое значение может существовать, но оно должно быть произведено из предоставленной информации (обычно выражение задается непосредственно) |
2 | UNK | Unknown | Правильное значение имеется, но оно неизвестно |
3 | ASKU | Asked but unknown | Информация запрошена, но ответ не получен (например, пациенту задали вопрос, а ответ он не знает) |
4 | NAV | Temporarily unavailable | Информация в данное время недоступна, но может стать доступной позже |
3 | NASK | Not asked | Эта информация не запрашивалась (например, пациенту вопрос не задавался) |
3 | QS | Sufficient quantity | Конкретная величина неизвестна, но известно, что она ненулевая и не указана, поскольку образована из большого объема вещества. "Добавить 10 мг ингредиента X, 50 мг ингредиента Y и достаточное количество воды до 100 мл". Эта причина пустоты может использоваться для представления количества воды |
3 | TRC | Trace | Содержание отлично от нуля, но слишком мало, чтобы можно было узнать его количество |
2 | MSK | Masked | Информация об этом элементе имеется, но не предоставлена отправителем по причине безопасности, конфиденциальности и т.д. Для получения доступа к этой информации могут существовать альтернативные механизмы. |
2 | NA | not applicable | В данном контексте правильное значение не существует (например, последний менструальный период у мужчины) |
Синтаксис ИСО/МЭК 11404 атрибута nullFlavor:
type NullFlavor = enumerated (NI, INV, OTH, NINF, PINF, UNC, DER, UNK, ASKU, NAV, QS, NASK, TRC, MSK, NA)
При этом, не все значения причины пустоты nullFlavor применимы ко всем типам данных. Причины NINF, PINF, QS и TRC должны использоваться только с типами данных количества QTY. Причина пустоты UNC должна использоваться только с типом данных, у которого есть свойство originalText, и если UNC используется, то свойство originalText должно быть непустым. Если используется причина пустоты DER, то должно быть непустым выражение expression.
7.3.3.3.2 updateMode : UpdateMode: это свойство позволяет системе-отправителю идентифицировать роль, которую этот атрибут играет в обработке экземпляра, которому он принадлежит.
Если это свойство не пусто, то его значение должно быть взято из системы кодирования HL7 UpdateMode. Текущие значения приведены в таблице 6.
Таблица 6 - Перечисление UpdateMode, ОИД: 2.16.840.1.113883.5.57
Уровень | Код | Описание | Определение |
1 | А | Add (добавить) | Элемент был (или должен быть) добавлен, если он еще не существует (если он уже существует, то это может трактоваться как ошибка.) |
1 | D | Remove (удалить) | Элемент был (или должен быть) удален (иногда он только помечается как удаленный). Если элемент является частью коллекции, то удаляются все совпадающие с ним элементы |
1 | R | replace (заменить) | Элемент уже существовал и был (или будет) пересмотрен (если в момент удаления элемент не существует, то это может трактоваться как ошибка) |
1 | AR | Add or Replace (добавить или заменить) | Элемент был (или должен быть) добавлен или заменен. О его предшествующем существовании никаких предположений не делается |
N | No Change (не изменять) | Не было (или не должно быть) изменения элемента. Этот код в основном используется, если данный элемент не изменен, но другие атрибуты экземпляра изменились | |
1 | U | Unknown (неизвестно) | Не указано, произошло ли изменение элемента и если произошло, какого вида, или элемент присутствует в форме ссылки или идентифицирующего свойства |
1 | К | Key (ключ) | Этот элемент является частью информации, идентифицирующей содержащий его объект |
Синтаксис ИСО/МЭК 11404 атрибута updateMode:
type UpdateMode = enumerated (A, D, R, AR, N, U, K)
Если атрибут updateMode отсутствует, то нет сведений о том, как вновь предоставленная информация изменяет уже существующую. В приведенном выше описании используется слово "совпадающий". При применении к типам данных оно означает, что в настоящем стандарте определены операции равенства (в других контекстах применения данной системы кодирования слово "совпадающий" может иметь другие значения).
Примечание - Атрибут updateMode не воздействует на семантику или поведение самого типа данных, но может управлять поведением систем, обрабатывающих объекты, содержащие экземпляры типа данных.
7.3.3.3.3 flavorld : Set(String): сигнализирует о наложении на тип данных одного или нескольких множеств ограничений. Единственное назначение указания того, что существует дополнительное ограничение типа данных, заключается в обеспечении проверки экземпляра: средства контроля могут найти правила, заданные с помощью атрибута flavorld, и подтвердить, что экземпляр удовлетворяет этим правилам. Никакая другая обработка не должна зависеть от значения атрибута flavorld.
Никакая другая семантика или вычислительное применение не должны зависеть от значения этого свойства. Если оно не пусто, то должно быть допустимым ограничением типа данных значения.
Дополнительное обсуждение использования атрибутов тонкостей типов данных и атрибута flavorld приведены в разделе А.3.
7.3.3.4 Равенство equals
7.3.3.4.1 По умолчанию равенство equals определяется в соответствии с нижеизложенным. Отдельные специализации типа данных ANY переопределяют равенство equals в целях указания семантики вычисления равенства для этих специализаций. Для каждого типа данных точно документируется вычисление равенства equals.
7.3.3.4.2 В таблице 7 суммируются отношения между значениями null, nullFlavor и равенством equals.
Таблица 7 - Отношения между значениями null, nullFlavor и равенством equals
Другое значение | null | nullFlavor | Правильное значение |
Это значение | |||
null | null | null | null |
nullFlavor | null | nullFlavor | nullFlavor |
Правильное значение | null | nullFlavor | правильное значение |
|
Согласно общему алгоритму равенства equals два значения равны, если они имеют одинаковый тип данных и если равны все атрибуты, не унаследованные от типов данных HXIT и ANY. Если какой-либо из приравниваемых атрибутов имеет пустое значение null или причину пустоты nullFlavor, то результат равен пустому значению null или первой общей генерализации причин пустоты (см. комментарии к сравнению причин пустоты в 7.1.4.
Операция равенства equals является рефлексивной, симметричной, транзитивной и постоянной, и все реализации должны удовлетворять этим требованиям. Правила равенства equals, определенные в настоящем стандарте, этим требованиям удовлетворяют.
Операция equals удовлетворяет общим правилам, описанным для операций и для причин пустоты, приведенным в 7.1.4, но здесь для большей ясности эти правила описаны более глубоко. В частности, правила транзитивны при применении операции равенства equals: если какой-либо из атрибутов или элементов коллекции имеет причину пустоты nullFlavor (отличающуюся от причины NA), то результатом будет то же самое значение причины пустоты nullFlavor, если иное особо не оговорено.
Операции равенства equals не переопределяют ни операцию "=", определенную в языке OCL, ни обычный эквивалент последней, используемой в любой платформе реализации. Она определяет семантическое равенство.
Примечание - При проверке равенства атрибуты updateMode и flavorld всегда игнорируются.
7.3.3.5 Инварианты
Экземпляр может иметь тип данных ANY (а не его специализацию), если у него есть причина пустоты nullFlavor, у которой не подразумевается значение INV.
Представление инвариантов на языке OCL:
def: let isNull : Boolean = nullFlavor.oclIsDefined
def: let isNotNull : Boolean = not isNull
def: let noUpdate : Boolean = updateMode.oclIsUndefined
def: let noUpdateOrHistory() : Boolean = noUpdate and noHistory
def: let noUpdateOrHistory (member : ANY) : Boolean =
member.oclIsDefined implies member.noUpdate and member.noHistory
def: let invalid : Boolean = (nullFlavor = NullFlavor.INV or
nullFlavor = NullFlavor.OTH or nullFlavor = NullFlavor.PINF or
nullFlavor = NullFlavor.NINF or nullFlavor = NullFlavor.UNC or
nullFlavor = NullFlavor.DER)
inv "тип данных ANY разрешен только при наличии причины пустоты nullFlavor": (isNotNull or invalid) implies
not oclIsTypeOf(ANY)
7.3.3.6 Операции
7.3.3.6.1 equals(other : ANY) : BL: указывает, считается ли это значение данных семантически равным другому значению данных (other), то есть имеют ли одинаковый смысл. Обсуждение определения этой операции см. в 7.3.3.4.
7.3.3.6.2 isNull() : Boolean: указывает, имеет ли это значение причину пустоты nullFlavor или нет.
Эта операция является исключением из общих правил, описанных для операций и для причин пустоты: она возвращает true, если значение имеет причину пустоты nullFlavor, и false в противном случае.
7.3.3.6.3 notNull() : Boolean: указывает, имеет ли это значение причину пустоты nullFlavor или нет.
Эта операция является исключением из общих правил, описанных для операций и для причин пустоты: она возвращает true, если значение не имеет причину пустоты nullFlavor, и false в противном случае.
7.3.3.7 Примеры
7.3.3.7.1 Неизвестное значение
<example xsi:type="ANY" nullFlavor="UNK"/>
Значение не известно, и не известен также тип значения (он не указан в экземпляре и не определяется контекстом).
7.3.3.7.2 Пустое значение null и причина пустоты nullFlavor
Ниже приведено представление кодированного понятия как значения простого типа данных (см. 7.5.1).
<example code="784.0" codeSystem="2.16.840.1.113883.6.42">
<displayName value="Headache"/>
</example>
У этого значения заданы атрибуты code, codeSystem и displayName. Все другие атрибуты пусты. В смысловых терминах это значение идентично следующему:
<example code="784.0" codeSystem="2.16.840.1.113883.6.42">
<displayName value="Headache"/>
<translation nullFlavor="NI"/>
</example>
Они имеют один и тот же смысл, поскольку в случае пустоты атрибута о нем можно сказать только то, что о его значении нет информации и причина этого неизвестна, то есть утверждать ровно то, что предусмотрено в значении пустоты nullFlavor.NI: нет информации, почему это значение не является правильным.
Аналогичным образом тот же смысл имеет следующее значение:
<example code="784.0" codeSystem="2.16.840.1.113883.6.42">
<displayName value="Headache"/>
<translation nullFlavor="NI" codeSystem="2.16.840.1.113883.6.96"/>
</example>
В данном случае есть определенное отличие: преобразование translation существует. Однако нет информации ни о нем, ни о том, почему его значение здесь отсутствует. Поэтому в смысловых терминах результат тот же.
В следующем примере показано, что для атрибута с причиной пустоты nullFlavor вполне можно предоставить дополнительную информацию:
<example code="784.0" codeSystem="2.16.840.1.113883.6.42">
<displayName value="Headache"/>
<translation nullFlavor="NI" codeSystem="2.16.840.1.113883.6.96"/>
</example>
В этом выражении указано несколько иное, а именно, что нет информации о преобразовании данного кода в систему кодирования SNOMED-CT. В отдельных случаях такая информация может оказаться значимой, хотя такое бывает редко.
7.3.3.7.3 Атрибут updateMode
Атрибут режима изменений updateMode принципиально важен при взаимодействии тесно связанных систем передачи и обработки сообщений. Тесно связанной системой является та, у которой ограниченное число приложений используется по строго определенным соглашениям между партнерами, а поток информации, передаваемой и принимаемой этими приложениями, хорошо организован и понятен. В этих условиях может оказаться выгоднее договориться, что вместо передачи в каждом сообщении всей имеющейся информации передаются только сведения об изменениях, произошедших в каждой транзакции. Это дает то преимущество, что стоимость реализации обмена информацией существенно снижается как для отправителя, так и для получателя, но при этом возрастает риск потери искажения информации, если порядок получения сообщений нарушен. Для правильного указания той информации, которая изменилась в транзакции, требуется атрибут updateMode.
В более общем случае, например для передачи медицинских документов или электронных медицинских карт, подобная обработка транзакций не применима, поэтому в таких контекстах атрибут updateMode обычно должен иметь фиксированное значение null.
Ниже показано несколько примеров того, как атрибут updateMode может использоваться в тесно связанных системах передачи и обработки сообщений. Эти примеры не должны рассматриваться как рекомендуемые руководства по использованию атрибута updateMode и соответствующей обработке, основанной на транзакциях.
В первом наборе примера рассмотрен простой случай, когда объектная модель имеет простой атрибут даты рождения лица birthDate :TS.
Пользователь открывает диалоговую форму для редактирования данных пациента и изменяет дату рождения на 21 июня 1975 года. Так как в системе уже хранится дата рождения, то она заменяется. Это приводит к тому, что тесно связанному целевому приложению передается экземпляр, содержащий следующий фрагмент:
<birthDate value="19750621" updateMode="R"/>
Приложение проверяет полученную информацию, определяет, что у него дата рождения уже хранится и заменяет ее на вновь полученное значение. Если бы прежней даты рождения не было, то это означало бы ошибку, хотя на практике обработка такой ситуации зависит от местных соглашений по безопасной обработке подобных случаев.
Позже другой пользователь открывает диалоговую форму для редактирования данных пациента и удаляет дату рождения. Это приводит к тому, что тесно связанному целевому приложению передается экземпляр, содержащий следующий фрагмент:
<birthDate nullFlavor="NI" updateMode="D"/>
Следует обратить внимание, что для придания этому значению допустимости требуется причина пустоты nullFlavor. Данный фрагмент означает, что дата рождения должна быть удалена и заменена на пустое значение с причиной пустоты NI. Это эквивалентно фрагменту:
<birthDate nullFlavor="NI" updateMode="R"/>
означающему, что дата рождения должна быть заменена на пустое значение с причиной пустоты NI. Как видно из этого примера, в подобных случаях в атрибуте updateMode нет особой необходимости. Он становится полезным, когда необходимо различать информацию, переданную в связи с ее изменением (UpdateMode.R), от информации, переданной для обеспечения идентификации. Для иллюстрации этого предположим, что в соглашении о транзакционной обработке было указано, что при изменении записи о пациенте в качестве идентификационных данных всегда должны передаваться фамилия, имя, отчество, пол и дата рождения. В этом случае экземпляр всегда содержит дату рождения. Используя значение атрибута updateMode, равное "К" (ключ), можно отметить, что атрибут даты рождения birthDate передан для идентификации, а не в связи с его изменением:
<birthDate nullFlavor="NI" updateMode="K"/>
Атрибут updateMode начинает приносить реальную пользу при управлении списками. В следующей группе примеров это демонстрируется на списке контактной информации пациента.
В типичном пользовательском интерфейсе для детализации разных видов контактной информации используются разные группы полей ввода. В информационную эру конкретные виды контактной информации, которые необходимо обеспечивать в интерфейсе, имеют тенденцию меняться, поэтому в настоящем стандарте детализация контактной информации представлена в виде типизированного списка (все больше и больше приложений следуют этому подходу). В данном гипотетическом случае используются отдельные поля ввода для номера стационарного телефона, номера мобильного телефона, номера факса и адреса электронной почты, а результатом ввода является атрибут contacts : DSET(TEL). Типичная запись пациента может содержать список контактной информации наподобие следующего, передаваемого в нетранзакционной среде:
<contacts>
<item value="tel:+11015551234" use="H" capabilities="voice"/>
<item value="tel:+11995556787" use="MC" capabilities="voice sms"/>
<item value="tel:+11015551235" capabilities="fax"/>
<item value="mailto:[email protected]"/>
</contacts>
В тесно связанной системе, использующей транзакционную обработку на основе атрибута updateMode, такой полный список редко будет передаваться. Вместо этого чаще будет передаваться только его часть.
Если пользователь открыл экранную форму с данными о пациенте и изменил в ней номер домашнего телефона, то может быть передан следующий экземпляр:
<contacts>
<item value="tel:+11015551234" use="H"
capabilities="voice" updateMode="D"/>
<item value="tel:+12315559876" use="H"
capabilities="voice" updateMode="A"/>
</contacts>
Приложение-получатель сравнивает имеющуюся у него информацию с этим экземпляром. Если оно не может найти исходный номер +11015551234, то это ошибка, которая должна быть обработана в соответствии с местными соглашениями. Если оно нашло этот номер, то удаляет его, а затем добавляет новый номер. Вместо указанного выше экземпляра можно попытаться послать другой, а именно:
<contacts>
<item value="tel:+12315559876" use="H"
capabilities="voice" updateMode="R"/>
</contacts>
с инструкцией о замене существующего номера. Однако какой номер следует заменить? На это нет ответа, поскольку совпадение основано на равенстве, значит, этот фрагмент означает замену номера домашнего телефона +12315559876 на номер +12315559876.
Поэтому лучше использовать операции удаления (D) и добавления (А), указывая значения типа данных. Операции замены (R) и добавления/замены (AR) не очень полезны: поскольку совпадение основано на равенстве, все, что можно сказать, это заменить значение А на значение А, что не имеет особого смысла. В общем случае полезнее использовать сложные объекты, включаемые в список допустимых значений типа данных, тем самым обеспечивая удовлетворение всех известных вариантов транзакционной обработки.
Существует пример, в котором можно использовать значение UpdateModel.R. Поскольку совпадение основано на равенстве, в котором используется передаваемый номер, то следующие два экземпляра несут один и тот же смысл:
<contacts>
<item value="tel:+11015551234" use="H"
capabilities="voice" upateMode="D"/>
<item value="tel:+ 11015551234" use="H WP"
capabilities="voice fax" updateMode="A"/>
</contacts>
<contacts>
<item value="tel:+ 11015551234" use="H W"
capabilities="voice fax" updateMode="R"/>
</contacts>
Оба этих экземпляра означают, что существующие детали использования номера +12315559876, а именно use (назначение) и capabilities (функции), надо заменить на новые.

{kind=link}